Math Is Fun Forum
You are not logged in.
- Topics: Active | Unanswered
#2251 2024-08-11 15:09:32
- Jai Ganesh
- Administrator

- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
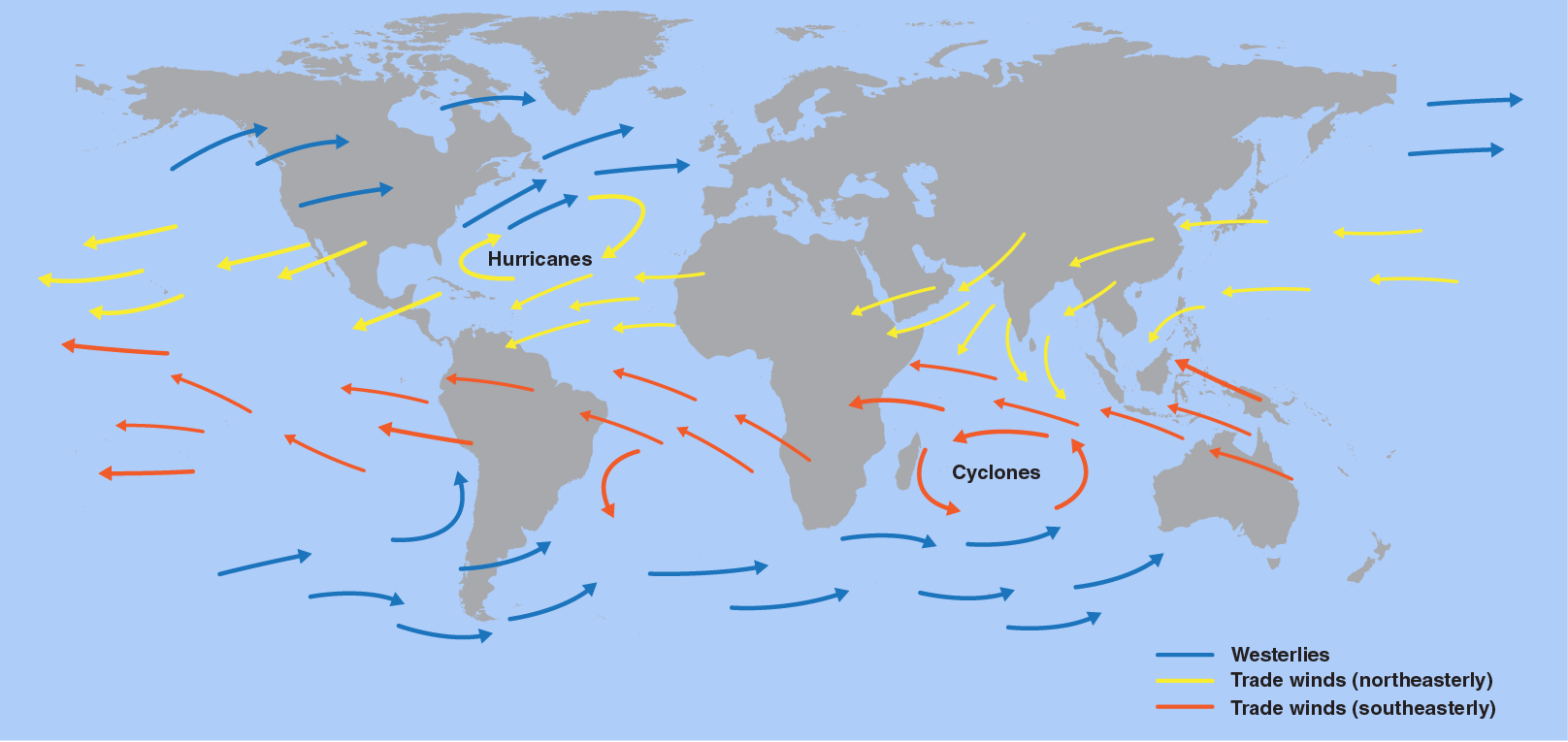
2253) Trade Winds
Gist
The trade winds are winds that reliably blow east to west just north and south of the equator. The winds help ships travel west, and they can also steer storms such as hurricanes, too.
What Are Trade Winds? Trade winds can be defined as the wind that flows towards the equator from the north-east in the Northern Hemisphere or from the south-east in the Southern Hemisphere. These are also known as tropical easterlies and are known for their consistency in force and direction.
Summary
Trade wind, persistent wind that blows westward and toward the Equator from the subtropical high-pressure belts toward the intertropical convergence zone (ITCZ). It is stronger and more consistent over the oceans than over land and often produces partly cloudy sky conditions, characterized by shallow cumulus clouds, or clear skies that make trade-wind islands popular tourist resorts. Its average speed is about 5 to 6 metres per second (11 to 13 miles per hour) but can increase to speeds of 13 metres per second (30 miles per hour) or more. The trade winds were named by the crews of sailing ships that depended on the winds during westward ocean crossings.
Details
The trade winds or easterlies are permanent east-to-west prevailing winds that flow in the Earth's equatorial region. The trade winds blow mainly from the northeast in the Northern Hemisphere and from the southeast in the Southern Hemisphere, strengthening during the winter and when the Arctic oscillation is in its warm phase. Trade winds have been used by captains of sailing ships to cross the world's oceans for centuries. They enabled European colonization of the Americas, and trade routes to become established across the Atlantic Ocean and the Pacific Ocean.
In meteorology, they act as the steering flow for tropical storms that form over the Atlantic, Pacific, and southern Indian oceans and cause rainfall in North America, Southeast Asia, and Madagascar and East Africa. Shallow cumulus clouds are seen within trade wind regimes and are capped from becoming taller by a trade wind inversion, which is caused by descending air aloft from within the subtropical ridge. The weaker the trade winds become, the more rainfall can be expected in the neighboring landmasses.
The trade winds also transport nitrate- and phosphate-rich Saharan dust to all Latin America, the Caribbean Sea, and to parts of southeastern and southwestern North America. Sahara dust is on occasion present in sunsets across Florida. When dust from the Sahara travels over land, rainfall is suppressed and the sky changes from a blue to a white appearance which leads to an increase in red sunsets. Its presence negatively impacts air quality by adding to the count of airborne particulates.
History
The term originally derives from the early fourteenth century sense of trade (in late Middle English) still often meaning "path" or "track". The Portuguese recognized the importance of the trade winds (then the volta do mar, meaning in Portuguese "turn of the sea" but also "return from the sea") in navigation in both the north and south Atlantic Ocean as early as the 15th century. From West Africa, the Portuguese had to sail away from continental Africa, that is, to west and northwest. They could then turn northeast, to the area around the Azores islands, and finally east to mainland Europe. They also learned that to reach South Africa, they needed to go far out in the ocean, head for Brazil, and around 30°S go east again. (This is because following the African coast southbound means sailing upwind in the Southern hemisphere.) In the Pacific Ocean, the full wind circulation, which included both the trade wind easterlies and higher-latitude westerlies, was unknown to Europeans until Andres de Urdaneta's voyage in 1565.
The captain of a sailing ship seeks a course along which the winds can be expected to blow in the direction of travel. During the Age of Sail, the pattern of prevailing winds made various points of the globe easy or difficult to access, and therefore had a direct effect on European empire-building and thus on modern political geography. For example, Manila galleons could not sail into the wind at all.
By the 18th century, the importance of the trade winds to England's merchant fleet for crossing the Atlantic Ocean had led both the general public and etymologists to identify the name with a later meaning of "trade": "(foreign) commerce". Between 1847 and 1849, Matthew Fontaine Maury collected enough information to create wind and current charts for the world's oceans.
Cause
As part of the Hadley cell, surface air flows toward the equator while the flow aloft is towards the poles. A low-pressure area of calm, light variable winds near the equator is known as the doldrums, near-equatorial trough, intertropical front, or the Intertropical Convergence Zone. When located within a monsoon region, this zone of low pressure and wind convergence is also known as the monsoon trough. Around 30° in both hemispheres, air begins to descend toward the surface in subtropical high-pressure belts known as subtropical ridges. The subsident (sinking) air is relatively dry because as it descends, the temperature increases, but the moisture content remains constant, which lowers the relative humidity of the air mass. This warm, dry air is known as a superior air mass and normally resides above a maritime tropical (warm and moist) air mass. An increase of temperature with height is known as a temperature inversion. When it occurs within a trade wind regime, it is known as a trade wind inversion.
The surface air that flows from these subtropical high-pressure belts toward the Equator is deflected toward the west in both hemispheres by the Coriolis effect. These winds blow predominantly from the northeast in the Northern Hemisphere and from the southeast in the Southern Hemisphere. Because winds are named for the direction from which the wind is blowing, these winds are called the northeasterly trade winds in the Northern Hemisphere and the southeasterly trade winds in the Southern Hemisphere. The trade winds of both hemispheres meet at the Doldrums.
As they blow across tropical regions, air masses heat up over lower latitudes due to more direct sunlight. Those that develop over land (continental) are drier and hotter than those that develop over oceans (maritime), and travel northward on the western periphery of the subtropical ridge. Maritime tropical air masses are sometimes referred to as trade air masses. All tropical oceans except the northern Indian Ocean have extensive areas of trade winds.
Weather and biodiversity effects
Clouds which form above regions within trade wind regimes are typically composed of cumulus which extend no more than 4 kilometres (13,000 ft) in height, and are capped from being taller by the trade wind inversion. Trade winds originate more from the direction of the poles (northeast in the Northern Hemisphere, southeast in the Southern Hemisphere) during the cold season, and are stronger in the winter than the summer. As an example, the windy season in the Guianas, which lie at low latitudes in South America, occurs between January and April. When the phase of the Arctic oscillation (AO) is warm, trade winds are stronger within the tropics. The cold phase of the AO leads to weaker trade winds. When the trade winds are weaker, more extensive areas of rain fall upon landmasses within the tropics, such as Central America.
During mid-summer in the Northern Hemisphere (July), the westward-moving trade winds south of the northward-moving subtropical ridge expand northwestward from the Caribbean Sea into southeastern North America (Florida and Gulf Coast). When dust from the Sahara moving around the southern periphery of the ridge travels over land, rainfall is suppressed and the sky changes from a blue to a white appearance which leads to an increase in red sunsets. Its presence negatively impacts air quality by adding to the count of airborne particulates. Although the Southeast US has some of the cleanest air in North America, much of the African dust that reaches the United States affects Florida. Since 1970, dust outbreaks have worsened due to periods of drought in Africa. There is a large variability in the dust transport to the Caribbean and Florida from year to year. Dust events have been linked to a decline in the health of coral reefs across the Caribbean and Florida, primarily since the 1970s.
Every year, millions of tons of nutrient-rich Saharan dust cross the Atlantic Ocean, bringing vital phosphorus and other fertilizers to depleted Amazon soils.
Additional Information
When you’re outside, you might notice that one day the wind blows one direction and the next day, wind is blowing a different direction. That’s a pretty common occurrence.
However, many winds on Earth are quite predictable. For example, high in the atmosphere, the jet streams typically blow across Earth from west to east. The trade winds are air currents closer to Earth’s surface that blow from east to west near the equator.
The Charles W. Morgan is the last of an American whaling fleet that once numbered more than 2,700 vessels. Ships like the Morgan often used routes defined by the trade winds to navigate the ocean.
Known to sailors around the world, the trade winds and associated ocean currents helped early sailing ships from European and African ports make their journeys to the Americas. Likewise, the trade winds also drive sailing vessels from the Americas toward Asia. Even now, commercial ships use "the trades" and the currents the winds produce to hasten their oceanic voyages.
How do these commerce-friendly winds form?
Between about 30 degrees north and 30 degrees south of the equator, in a region called the horse latitudes, the Earth's rotation causes air to slant toward the equator in a southwesterly direction in the northern hemisphere and in a northwesterly direction in the southern hemisphere. This is called the Coriolis Effect.
The Coriolis Effect, in combination with an area of high pressure, causes the prevailing winds—the trade winds—to move from east to west on both sides of the equator across this 60-degree "belt."
As the wind blows to about five degrees north and south of the equator, both air and ocean currents come to a halt in a band of hot, dry air. This 10-degree belt around Earth's midsection is called the Inter-Tropical Convergence Zone, more commonly known as the doldrums.
Intense solar heat in the doldrums warms and moistens the trade winds, thrusting air upwards into the atmosphere like a hot air balloon. As the air rises, it cools, causing persistent bands of showers and storms in the tropics and rainforests. The rising air masses move toward the poles, then sink back toward Earth's surface near the horse latitudes. The sinking air triggers the calm trade winds and little precipitation, completing the cycle.
Why do the trade winds blow from east to west?
The trade winds blow toward the west partly because of how Earth rotates on its axis. The trade winds begin as warm, moist air from the equator rises in the atmosphere and cooler air closer to the poles sinks.
The trade winds are created by a cycle of warm, moist air rising near the equator. The air eventually cools and sinks a bit further north in the tropics. This phenomenon is called the Hadley cell.
So, if air is cycling from the equator to the poles, why don’t all winds blow north and south? That’s where Earth’s rotation changes things. Because Earth rotates as the air is moving, the winds in the Northern Hemisphere curve to the right and air in the Southern Hemisphere curves to the left.
This phenomenon is called the Coriolis Effect and it’s why the trade winds blow toward the west in both the Northern Hemisphere and Southern Hemisphere. The trade winds can be found about 30 degrees north and south of the equator. Right at the equator there is almost no wind at all—an area sometimes called the doldrums.
Earth's rotation causes the trade winds to curve clockwise in the Northern Hemisphere and counterclockwise in the Southern Hemisphere. The area of almost no wind at the equator is called the doldrums.
How do the doldrums and trade winds affect our weather?
The Sun shines very directly at the equator, creating very intense heat. The heat warms the air and causes some ocean water to evaporate, meaning air in the doldrums becomes warm and moist. This warm, moist air rises in the atmosphere and cools, becoming clouds — and eventually rain and storms — in tropical regions. In the Atlantic Ocean, some of these storms become hurricanes, and the trade winds can steer hurricanes west toward the United States.
It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2252 2024-08-12 00:03:11
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2254) National Anthem
Gist
National Anthem is the official song of a country that is played at public events.
Summary
National anthem is a hymn or song expressing patriotic sentiment and either governmentally authorized as an official national hymn or holding that position in popular feeling. The oldest national anthem is Great Britain’s “God Save the Queen,” which was described as a national anthem in 1825, although it had been popular as a patriotic song and used on occasions of royal ceremonial since the mid-18th century.
During the 19th and early 20th centuries, most European countries followed Britain’s example, some national anthems being written especially for the purpose, others being adapted from existing tunes. The sentiments of national anthems vary, from prayers for the monarch to allusions to nationally important battles or uprisings (“The Star-Spangled Banner,” United States; “La Marseillaise,” France) to expressions of patriotic feeling (“O Canada”).
National anthems vary greatly in musical merit, and the verse or text, like the music, has not in every case been written by a national of the country concerned. Changes in politics or international relationships often cause the texts to be altered or a new anthem to be adopted. For example, the U.S.S.R. adopted “Gimn Sovetskogo Soyuza” (“Hymn of the Soviet Union”) as its national anthem in 1944, replacing the communist hymn “L’Internationale,” whose words and music were written in the late 19th century by two French workers.
Few national anthems have been written by poets or composers of renown, a notable exception being the first Austrian national anthem, “Gott erhalte Franz den Kaiser” (“God Save Emperor Francis”), composed by Joseph Haydn in 1797 and later (1929) sung to the text “Sei gesegnet ohne Ende” (“Be Blessed Forever”). Haydn’s melody was also used for the German national anthem “Deutschland, Deutschland über Alles” (“Germany, Germany Above All”), adopted in 1922. Beginning with its third verse, “Einigkeit und Recht und Freiheit” (“Unity and rights and freedom”), it continues in use as the national anthem of Germany, retitled as “Deutschlandlied.” The German national anthem before 1922 had been “Heil dir im Siegerkranz” (“Hail to Thee in Victor’s Garlands”), sung to the melody of “God Save the Queen.” Some authors of national anthems, such as Italy’s Goffredo Mameli, gained renown only as a result of their composition’s national popularity.
Details
A national anthem is a patriotic musical composition symbolizing and evoking eulogies of the history and traditions of a country or nation. The majority of national anthems are marches or hymns in style. American, Central Asian, and European nations tend towards more ornate and operatic pieces, while those in the Middle East, Oceania, Africa, and the Caribbean use a more simplistic fanfare. Some countries that are devolved into multiple constituent states have their own official musical compositions for them (such as with the United Kingdom, Russia, and the Soviet Union); their constituencies' songs are sometimes referred to as national anthems even though they are not sovereign states.
History
In the early modern period, some European monarchies adopted royal anthems. Some of these anthems have survived into current use. "God Save the King/Queen", first performed in 1619, remains the royal anthem of the United Kingdom and the Commonwealth realms. La Marcha Real, adopted as the royal anthem of the Spanish monarchy in 1770, was adopted as the national anthem of Spain in 1939. Denmark retains its royal anthem, Kong Christian stod ved højen mast (1780) alongside its national anthem (Der er et yndigt land, adopted 1835). In 1802, Gia Long commissioned a royal anthem in the European fashion for the Kingdom of Vietnam.
Following the reinstating of La Marseillaise in 1830, in the wake of the July Revolution, as the national anthem of France, it became common for newly formed nations to define national anthems, notably as a result of the Latin American wars of independence, for Argentina (1813), Peru (1821), Brazil (1831) but also Belgium (1830). Consequently, adoption of national anthems prior to the 1930s was mostly by newly formed or newly independent states, such as the First Portuguese Republic (A Portuguesa, 1911), the Kingdom of Greece ("Hymn to Liberty", 1865), the First Philippine Republic (Marcha Nacional Filipina, 1898), Lithuania (Tautiška giesmė, 1919), Weimar Germany (Deutschlandlied, 1922), Ireland (Amhrán na bhFiann, 1926) and Greater Lebanon ("Lebanese National Anthem", 1927). Though the custom of an officially adopted national anthem became popular in the 19th century, some national anthems predate this period, often existing as patriotic songs long before their designation as national anthem.
If an anthem is defined as consisting of both a melody and lyrics, then the oldest national anthem in use today is the national anthem of the Netherlands, the Wilhelmus. Written between 1568 and 1572 during the Dutch Revolt, it was already a popular orangist hymn during the 17th century, though it would take until 1932 for it to be officially recognized as the Dutch national anthem. The lyrics of the Japanese national anthem, Kimigayo, predate those of the Dutch anthem by several centuries, being taken from a Heian period (794–1185) poem, but were not set to music until 1880. If a national anthem is defined by being officially designated as the national song of a particular state, then La Marseillaise, which was officially adopted by the French National Convention in 1796, would qualify as the first official national anthem.
The Olympic Charter of 1920 introduced the ritual of playing the national anthems of the gold medal winners. From this time, the playing of national anthems became increasingly popular at international sporting events, creating an incentive for such nations that did not yet have an officially defined national anthem to introduce one.
The United States introduced the patriotic song The Star-Spangled Banner as a national anthem in 1931. Following this, several nations moved to adopt as official national anthem patriotic songs that had already been in de facto use at official functions, such as Mexico (Mexicanos, al grito de guerra, composed 1854, adopted 1943) and Switzerland ("Swiss Psalm", composed 1841, de facto use from 1961, adopted 1981).
By the period of decolonisation in the 1960s, it had become common practice for newly independent nations to adopt an official national anthem. Some of these anthems were specifically commissioned, such as the anthem of Kenya, Ee Mungu Nguvu Yetu, produced by a dedicated "Kenyan Anthem Commission" in 1963.
A number of nations remain without an official national anthem adopted de iure. In these cases, there are established de facto anthems played at sporting events or diplomatic receptions. These include the United Kingdom (God Save the King) and Sweden (Du gamla, Du fria; the country also has a royal anthem, Kungssangen). Countries that have moved to officially adopt de iure their long-standing de facto anthems since the 1990s include:
Luxembourg (Ons Heemecht, adopted 1993), South Africa (National anthem of South Africa, adopted 1997), Israel (Hatikvah, composed 1888, de facto use from 1948, adopted 2004) and Italy (Il Canto degli Italiani, composed 1847, de facto use from 1946, adopted 2017).
Usage
Star-Spangled Banner with the American flag (ca. 1940s). Anthems used during sign-on and sign-off sequences have become less common due to the increasing prevalence of 24-hour-a-day, seven-day-a-week broadcasting.
National anthems are used in a wide array of contexts. Certain etiquette may be involved in the playing of a country's anthem. These usually involve military honours, standing up, removing headwear etc. In diplomatic situations the rules may be very formal. There may also be royal anthems, presidential anthems, state anthems etc. for special occasions.
They are played on national holidays and festivals, and have also come to be closely connected with sporting events. Wales was the first country to adopt this, during a rugby game against New Zealand in 1905. Since then during sporting competitions, such as the Olympic Games, the national anthem of the gold medal winner is played at each medal ceremony; also played before games in many sports leagues, since being adopted in baseball during World War II.[8] When teams from two nations play each other, the anthems of both nations are played, the host nation's anthem being played last.
In some countries, the national anthem is played to students each day at the start and/or end of school as an exercise in patriotism, such as in Tanzania. In other countries the state anthem may be played in a theatre before a play or in a cinema before a movie. Many radio and television stations have adopted this and play the national anthem when they sign on in the morning and again when they sign off at night. For instance, the national anthem of China is played before the broadcast of evening news on Hong Kong's local television stations including TVB Jade. In Colombia, it is a law to play the National Anthem at 6:00 and 18:00 on every public radio and television station, while in Thailand, "Phleng Chat Thai" is played at 08:00 and 18:00 nationwide (the Royal Anthem is used for sign-ons and closedowns instead). The use of a national anthem outside of its country, however, is dependent on the international recognition of that country. For instance, Taiwan has not been recognized by the International Olympic Committee as a separate nation since 1979 and must compete as Chinese Taipei; its "National Banner Song" is used instead of its national anthem. In Taiwan, the country's national anthem is sung before instead of during flag-rising and flag-lowering, followed by the National Banner Song during the actual flag-rising and flag-lowering. Even within a state, the state's citizenry may interpret the national anthem differently (such as in the United States some view the U.S. national anthem as representing respect for dead soldiers and policemen whereas others view it as honouring the country generally).
Various solutions may be used when countries with different national anthems compete in a unified team. When North Korea and South Korea participated together in the 2018 Winter Olympics, the folk song "Arirang", beloved on both sides of the border and seen as a symbol of Korea as a whole, was used as an anthem instead of the national anthem of either state.
On 21 September 2021, to mark the International Day of Peace, Australian sisters Teresa and Augnes Joy set a world record for singing the national anthems of 193 countries in a hundred languages at an event hosted by the United Nations Association of Australia in Brisbane.
Creators
Most of the best-known national anthems were written by little-known or unknown composers such as Claude Joseph Rouget de Lisle, composer of "La Marseillaise" and John Stafford Smith who wrote the tune for "The Anacreontic Song", which became the tune for the U.S. national anthem, "The Star-Spangled Banner". The author of "God Save the King", one of the oldest and best-known anthems in the world, is unknown and disputed.
Very few countries have a national anthem written by a world-renowned composer. Exceptions include Germany, whose anthem "Das Lied der Deutschen" uses a melody written by Joseph Haydn, and Austria, whose national anthem "Land der Berge, Land am Strome" is sometimes credited to Wolfgang Amadeus Mozart. The music of the "Pontifical Anthem", anthem of the Vatican City, was composed in 1869 by Charles Gounod, for the golden jubilee of Pope Pius IX's priestly ordination. When Armenia was under Soviet rule, its anthem, the "Anthem of the Armenian Soviet Socialist Republic" used a melody by Aram Khachaturian.
The committee charged with choosing a national anthem for the Federation of Malaya (later Malaysia) at independence decided to invite selected composers of international repute to submit compositions for consideration, including Benjamin Britten, William Walton, Gian Carlo Menotti and Zubir Said, who later composed "Majulah Singapura", the national anthem of Singapore. None were deemed suitable. The tune eventually selected was (and still is) the anthem of the constituent state of Perak, which was in turn adopted from a popular French melody titled "La Rosalie" composed by the lyricist Pierre-Jean de Béranger.
A few anthems have words by Nobel laureates in literature. The first Asian laureate, Rabindranath Tagore, wrote the words and music of "Jana Gana Mana" and "Amar Shonar Bangla", later adopted as the national anthems of India and Bangladesh respectively. Bjørnstjerne Bjørnson wrote the lyrics for the Norwegian national anthem "Ja, vi elsker dette landet".
Other countries had their anthems composed by locally important people. This is the case for Colombia, whose anthem's lyrics were written by former president and poet Rafael Nuñez, who also wrote the country's first constitution, and in Malta, written by Dun Karm Psaila, already a National Poet. A similar case is Liberia, the national anthem of which was written by its third president, Daniel Bashiel Warner.
Languages
A national anthem, when it has lyrics (as is usually the case), is most often in the national or most common language of the country, whether de facto or official, there are notable exceptions. Most commonly, states with more than one national language may offer several versions of their anthem, for instance:
* The "Swiss Psalm", the national anthem of Switzerland, has different lyrics for each of the country's four official languages (French, German, Italian and Romansh).
* The national anthem of Canada, "O Canada", has official lyrics in both English and French which are not translations of each other, and is frequently sung with a mixture of stanzas, representing the country's bilingual nature. The song itself was originally written in French.
* "Flower of Scotland", the unofficial national anthem of Scotland, features some words written and spoken in the Scots language
* "The Soldier's Song", the national anthem of Ireland, was originally written and adopted in English, but an Irish translation, although never formally adopted, is nowadays almost always sung instead, even though only 10.5% of Ireland speaks Irish natively.
* The current South African national anthem is unique in that five of the country's eleven official languages are used in the same anthem (the first stanza is divided between two languages, with each of the remaining three stanzas in a different language). It was created by combining two songs together and then modifying the lyrics and adding new ones.
* The former country of Czechoslovakia combined the two national anthems of the two lands; the first stanza consisting of the first stanza of the Czech anthem "Kde domov můj", and the second stanza consisting of the first stanza of the Slovak anthem "Nad Tatrou sa blýska".
* One of the two official national anthems of New Zealand, "God Defend New Zealand", is now commonly sung with the first verse in Māori ("Aotearoa") and the second in English ("God Defend New Zealand"). The tune is the same but the words are not a direct translation of each other.
* "God Bless Fiji" has lyrics in English and Fijian which are not translations of each other. Although official, the Fijian version is rarely sung, and it is usually the English version that is performed at international sporting events.
* Although Singapore has four official languages, with English being the current lingua franca, the national anthem, "Majulah Singapura" is in Malay and, by law, can only be sung with its original Malay lyrics, despite Malay being a minority language in Singapore. This is because Part XIII of the Constitution of the Republic of Singapore declares, "the national language shall be the Malay language and shall be in the Roman script [...]"
* There are several countries that do not have official lyrics to their national anthems. One of these is the "Marcha Real", the national anthem of Spain. Although it originally had lyrics, those lyrics were discontinued after governmental changes in the early 1980s after Francisco Franco's dictatorship ended. In 2007, a national competition to write words was held, but no lyrics were chosen. Other national anthems with no words include "Inno Nazionale della Repubblica", the national anthem of San Marino, that of Bosnia and Herzegovina, that of Russia from 1990 to 2000, and that of Kosovo, entitled "Europe".
* The national anthem of India, "Jana Gana Mana": the official lyrics are in Bengali; they were adapted from a poem written by Rabindranath Tagore.
* Despite the most common language in Wales being English, the unofficial national anthem of Wales, "Hen Wlad Fy Nhadau" is sung in the Welsh language.
* An unofficial national anthem of Finland, "Maamme", was first written in Swedish and only later translated to Finnish. It is nowadays sung in both languages as there is a Swedish speaking minority of about 5% in the country. * * The national anthem of Estonia, "Mu isamaa, mu õnn ja rõõm" has a similar melody with "Maamme", but only with different lyrics and without repeating the second halves of strophes. Finlandia has been repeatedly suggested to be the official national anthem of Finland.
* The national anthem of Pakistan, the "Qaumi Taranah", is unique in that it is entirely in Farsi (Persian) with the exception of one word which is in Urdu, the national language.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2253 2024-08-12 22:02:10
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2255) Cardamom
Gist
Cardamom has a strong taste, with an aromatic, resinous fragrance. Black cardamom has a more smoky – though not bitter – aroma, with a coolness some consider similar to mint. Green cardamom is one of the most expensive spices by weight, but little is needed to impart flavor.
Cardamom is a spice consisting of whole or ground dried fruits, or seeds, of Elettaria cardamomum, a herbaceous perennial plant of the ginger family (Zingiberaceae). The seeds have a warm, slightly pungent, and highly aromatic flavour somewhat reminiscent of camphor.
Summary
cardamom, spice consisting of whole or ground dried fruits, or seeds, of Elettaria cardamomum, a herbaceous perennial plant of the ginger family (Zingiberaceae). The seeds have a warm, slightly pungent, and highly aromatic flavour somewhat reminiscent of camphor. They are a popular seasoning in South Asian dishes, particularly curries, and in Scandinavian pastries.
Introduced to Europe in the mid-16th century, cardamom bears a name that blends the Greek words for “spice” and “cress.” The name is sometimes mistakenly applied to similar spices in the ginger family, but it properly describes two related varieties of the spice, black and green, the latter being the more common. Black cardamom is aromatic and smoky, whereas green cardamom has a milder flavour.
Physical description
Leafy shoots of the cardamom plant arise 1.5 to 6 metres (5 to 20 feet) from the branching rootstock. Flowering shoots, approximately 1 metre (3 feet) long, may be upright or sprawling; each bears numerous flowers about 5 cm (2 inches) in diameter with greenish petals and a purple-veined white lip. The whole fruit, 0.8 to 1.5 cm, is a green three-sided oval capsule containing 15 to 20 dark, reddish brown to brownish black, hard, angular seeds. The essential oil occurs in large parenchyma cells underlying the epidermis of the seed coat. The essential oil content varies from 2 to 10 percent; its principal components are cineole and α-terpinyl acetate.
Cultivation and processing
Cardamom fruits may be collected from wild plants, native to the moist forests of southern India, but most cardamom is cultivated in India, Sri Lanka, and Guatemala. The fruits are picked or clipped from the stems just before maturity, cleansed, and dried in the sun or in a heated curing chamber. Cardamom may be bleached to a creamy white colour in the fumes of burning sulfur. After curing and drying, the small stems of the capsules are removed by winnowing. Decorticated cardamom consists of husked dried seeds.
Cooking uses and health benefits
The cardamom pod, which contains hard, black seeds, is sometimes added whole to dishes. More commonly, the pods are opened and the seeds are removed, then roasted in an oven or a skillet. These seeds contain the spice’s essential oil, which gives it its flavour and scent, with hints of mint and lemon. The seeds are ground with a mortar and pestle, then added to South Asian foods such as curry and chai. Cardamom is a characteristic ingredient in Middle Eastern cuisine as well. It also figures in pastries, especially in the Scandinavian countries, where it is also used as a flavouring for coffee and tea. The spice mixes well with cinnamon, as well as nutmeg and cloves. It is also an ingredient in the Indian spice blend called garam masala.
Cardamom contains vitamin C, niacin, magnesium, and potassium. Apart from its distinctive flavour, cardamom contains high levels of antioxidants, and it is used in Ayurvedic medicine to treat urinary tract disorders and to lower blood sugar levels. It is also frequently incorporated as an ingredient in homeopathic toothpaste for its antibacterial and breath-freshening qualities. Stronger health claims, such as its efficacy in fighting cancers, lack medical substantiation to date.
Although cardamom is widely cultivated at various elevations in South Asia, most of the world market demand is met by Guatemala, where cardamom was introduced by European coffee planters. It is ranked high among the world’s most expensive spices by weight.
Details
Cardamom, sometimes cardamon or cardamum, is a spice made from the seeds of several plants in the genera Elettaria and Amomum in the family Zingiberaceae. Both genera are native to the Indian subcontinent and Indonesia. They are recognized by their small seed pods: triangular in cross-section and spindle-shaped, with a thin, papery outer shell and small, black seeds; Elettaria pods are light green and smaller, while Amomum pods are larger and dark brown.
Species used for cardamom are native throughout tropical and subtropical Asia. The first references to cardamom are found in Sumer, and in Ayurveda. In the 21st century, it is cultivated mainly in India, Indonesia, and Guatemala.
Etymology
The word cardamom is derived from the Latin cardamōmum, as a Latinisation of the Greek (kardámōmon), a compound of (kárdamon, "cress") and (ámōmon), of unknown origin.
The earliest attested form of the word signifying "cress" is the Mycenaean Greek ka-da-mi-ja, written in Linear B syllabic script, in the list of flavorings on the spice tablets found among palace archives in the House of the Sphinxes in Mycenae.
The modern genus name Elettaria is derived from the root ēlam attested in Dravidian languages.
Types and distribution
The two main types of cardamom are:
* True or green cardamom (or white cardamom when bleached) comes from the species Elettaria cardamomum and is distributed from India to Malaysia. What is often referred to as white cardamon is actually Siam cardamom, Amomum krervanh.
* Black cardamom, also known as brown, greater, large, longer, or Nepal cardamom, comes from the species Amomum subulatum and is native to the eastern Himalayas and mostly cultivated in Eastern Nepal, Sikkim, and parts of Darjeeling district in West Bengal of India, and southern Bhutan.
The two types of cardamom were distinguished in the fourth century BCE by Theophrastus.
Uses
Both forms of cardamom are used as flavorings and cooking spices in both food and drink. E. cardamomum (green cardamom) is used as a spice, a masticatory, or is smoked.
Food and beverage
Cardamom has a strong taste, with an aromatic, resinous fragrance. Black cardamom has a more smoky – though not bitter – aroma, with a coolness some consider similar to mint.
Green cardamom is one of the most expensive spices by weight, but little is needed to impart flavor. It is best stored in the pod, as exposed or ground seeds quickly lose their flavor. Grinding the pods and seeds together lowers both the quality and the price. For recipes requiring whole cardamom pods, a generally accepted equivalent is 10 pods equals 1+1/2 teaspoons (7.4 ml) of ground cardamom.
Cardamom is a common ingredient in Indian cooking. It is also often used in baking in the Nordic countries, in particular in Sweden, Norway, and Finland, where it is used in traditional treats such as the Scandinavian Yule bread Julekake, the Swedish kardemummabullar sweet bun, and Finnish sweet bread pulla. In the Middle East, green cardamom powder is used as a spice for sweet dishes, and as a traditional flavouring in coffee and tea. Cardamom is used to a wide extent in savoury dishes. In some Middle Eastern countries, coffee and cardamom are often ground in a wooden mortar, a mihbaj, and cooked together in a skillet, a mehmas, over wood or gas, to produce mixtures with up to 40% cardamom.
In Asia, both types of cardamom are widely used in both sweet and savoury dishes, particularly in the south. Both are frequent components in such spice mixes as Indian and Nepali masalas and Thai curry pastes. Green cardamom is often used in traditional Indian sweets and in masala chai (spiced tea). Both are also often used as a garnish in basmati rice and other dishes. Individual seeds are sometimes chewed and used in much the same way as chewing gum. It is used by confectionery giant Wrigley; its Eclipse Breeze Exotic Mint packaging indicates the product contains "cardamom to neutralize the toughest breath odors". It is also included in aromatic bitters, gin, and herbal teas.
In Korea, Tavoy cardamom (Wurfbainia villosa var. xanthioides) and red cardamom (Lanxangia tsao-ko) are used in tea called jeho-tang.
Composition
The essential oil content of cardamom seeds depends on storage conditions and may be as high as 8%. The oil is typically 45% α-terpineol, 27% myrcene, 8% limonene, 6% menthone, 3% β-phellandrene, 2% 1,8-cineol, 2% sabinene and 2% heptane. Other sources report the following contents: 1,8-cineol (20 to 50%), α-terpenylacetate (30%), sabinene, limonene (2 to 14%), and borneol.
In the seeds of round cardamom from Java (Wurfbainia compacta), the content of essential oil is lower (2 to 4%), and the oil contains mainly 1,8-cineol (up to 70%) plus β-pinene (16%); furthermore, α-pinene, α-terpineol and humulene are found.
Production
In 2022, world production of cardamom (included with nutmeg and mace for reporting to the United Nations) was 138,888 tonnes, led by India, Indonesia and Guatemala, which together accounted for 85% of the total.
Production practices
According to Nair (2011), in the years when India achieves a good crop, it is still less productive than Guatemala. Other notable producers include Costa Rica, El Salvador, Honduras, Papua New Guinea, Sri Lanka, Tanzania, Thailand, and Vietnam.
Much production of cardamom in India is cultivated on private property or in areas the government leases out to farmers. Traditionally, small plots of land within the forests (called eld-kandies) where the wild or acclimatised plant existed are cleared during February and March. Brushwood is cut and burned, and the roots of powerful weeds are torn up to free the soil. Soon after clearing, cardamom plants spring up. After two years the cardamom plants may have eight-to-ten leaves and reach 30 cm (1 ft) in height. In the third year, they may be 120 cm (4 ft) in height. In the following May or June the ground is again weeded, and by September to November a light crop is obtained. In the fourth year, weeding again occurs, and if the cardamoms grow less than 180 cm (6 ft) apart a few are transplanted to new positions. The plants bear for three or four years; and historically the life of each plantation was about eight or nine years. In Malabar the seasons run a little later than in Mysore, and – according to some reports – a full crop may be obtained in the third year. Cardamoms grown above 600 m (2,000 ft) elevation are considered to be of higher quality than those grown below that altitude.
Plants may be raised from seed or by division of the rhizome. In about a year, the seedlings reach about 30 cm (1 ft) in length, and are ready for transplantation. The flowering season is April to May, and after swelling in August and September, by the first half of October usually attain the desired degree of ripening. The crop is accordingly gathered in October and November, and in exceptionally moist weather, the harvest protracts into December. At the time of harvesting, the scapes or shoots bearing the clusters of fruits are broken off close to the stems and placed in baskets lined with fresh leaves. The fruits are spread out on carefully prepared floors, sometimes covered with mats, and are then exposed to the sun. Four or five days of careful drying and bleaching in the sun is usually enough. In rainy weather, drying with artificial heat is necessary, though the fruits suffer greatly in colour; they are consequently sometimes bleached with steam and sulphurous vapour or with ritha nuts.
The industry is highly labour-intensive, each hectare requiring considerable maintenance throughout the year. Production constraints include recurring climate vagaries, the absence of regular re-plantation, and ecological conditions associated with deforestation.
Cultivation
In 1873 and 1874, Ceylon (now Sri Lanka) exported about 4,100 kg (9,000 lb) each year. In 1877, Ceylon exported 5,039 kg (11,108 lb), in 1879, 8,043 kg (17,732 lb), and in the 1881–82 season, 10,490 kg (23,127 lb). In 1903, 1,600 hectares (4,000 acres) of cardamom growing areas were owned by European planters. The produce of the Travancore plantations was given as 290,000 kg (650,000 lb), or just a little under that of Ceylon. The yield of the Mysore plantations was approximately 91,000 kg (200,000 lb), and the cultivation was mainly in Kadur district. The volume for 1903–04 stated the value of the cardamoms exported to have been Rs. 3,37,000 as compared with Rs. 4,16,000 the previous year. India, which ranks second in world production, recorded a decline of 6.7 percent in cardamom production for 2012–13, and projected a production decline of 30–40% in 2013–14, compared with the previous year due to unfavorable weather. In India, the state of Kerala is by far the most productive producer, with the districts of Idukki, Palakkad and Wynad being the principal producing areas. Given that a number of bureaucrats have personal interests in the industry, in India, several organisations have been set up to protect cardamom producers such as the Cardamom Growers Association (est. 1992) and the Kerala Cardamom Growers Association (est. 1974). Research in India's cardamom plantations began in the 1970s while Kizhekethil Chandy held the office of Chairman of the Cardamom Board. The Kerala Land Reforms Act imposed restrictions on the size of certain agricultural holdings per household to the benefit of cardamom producers.
In 1979–1980, Guatemala surpassed India in worldwide production. Guatemala cultivates Elettaria cardamomum, which is native to the Malabar Coast of India. Alta Verapaz Department produces 70 percent of Guatemala's cardamom. Cardamom was introduced to Guatemala before World War I by the German coffee planter Oscar Majus Kloeffer. After World War II, production was increased to 13,000 to 14,000 tons annually.
The average annual income for a plantation-owning household in 1998 was US$3,408. Although the typical harvest requires over 210 days of labor per year, most cardamom farmers are better off than many other agricultural workers, and there are a significant number of those from the upper strata of society involved in the cultivation process. Increased demand since the 1980s, principally from China, for both Wurfbainia villosa and Lanxangia tsao-ko, has provided a key source of income for poor farmers living at higher altitudes in localized areas of China, Laos, and Vietnam, people typically isolated from many other markets. Laos exports about 400 tonnes annually through Thailand according to the FAO.
Trade
Cardamom production's demand and supply patterns of trade are influenced by price movements, nationally and internationally, in 5 to 6-year cycles. Importing leaders mentioned are Saudi Arabia and Kuwait, while other significant importers include Germany, Iran, Japan, Jordan, Pakistan, Qatar, United Arab Emirates, the UK, and the former USSR. According to the United Nations Conference on Trade and Development, 80 percent of cardamom's total consumption occurs in the Middle East.
In the 19th century, Bombay and Madras were among the principal distributing ports of cardamom. India's exports to foreign countries increased during the early 20th century, particularly to the United Kingdom, followed by Arabia, Aden, Germany, Turkey, Japan, Persia and Egypt. However, some 95% of cardamom produced in India is for domestic purposes, and India is itself by far the most important consuming country for cardamoms in the world. India also imports cardamom from Sri Lanka. In 1903–1904, these imports came to 122,076 kg (269,132 lb), valued at Rs. 1,98,710. In contrast, Guatemala's local consumption is negligible, which supports the exportation of most of the cardamom that is produced. In the mid-1800s, Ceylon's cardamom was chiefly imported by Canada. After saffron and vanilla, cardamom is currently the third most expensive spice, and is used as a spice and flavouring for food and liqueurs.
History
Cardamom has been used in flavorings and food over centuries. During the Middle Ages, cardamom dominated the trade industry. The Arab states played a significant role in the trade of Indian spices, including cardamom. It is now ranked the third most expensive spice following saffron and vanilla.
Cardamom production began in ancient times, and has been referred to in ancient Sanskrit texts as ela. The Babylonians and Assyrians used the spice early on, and trade in cardamom opened up along land routes and by the interlinked Persian Gulf route controlled from Dilmun as early as the third millennium BCE Early Bronze Age, into western Asia and the Mediterranean world.
The ancient Greeks thought highly of cardamom, and the Greek physicians Dioscorides and Hippocrates wrote about its therapeutic properties, identifying it as a digestive aid. Due to demand in ancient Greece and Rome, the cardamom trade developed into a handsome luxury business; cardamom was one of the spices eligible for import tax in Alexandria in 126 CE. In medieval times, Venice became the principal importer of cardamom into the west, along with pepper, cloves and cinnamon, which was traded with merchants from the Levant with salt and meat products.
In China, Amomum was an important part of the economy during the Song Dynasty (960–1279). In 1150, the Arab geographer Muhammad al-Idrisi noted that cardamom was being imported to Aden, in Yemen, from India and China.
The Portuguese became involved in the trade in the 16th century, and the industry gained wide-scale European interest in the 19th century.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2254 2024-08-13 16:23:11
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2256) Eye Bank
Gist
Eye banks can be defined as “a non-profit organization that obtains, medically evaluates and distributes eye tissue for transplant, research, and education”. Ideally, an eye bank should function autonomously and not be part of a medical organization. Eye banks feature a wide range of functions and specializations.
Summary
While prevention is the most desirable way to control corneal blindness, once a cornea has lost its transparency, a corneal transplant, or graft, is a patient's best chance to regain vision in the affected eye(s). However, the biggest limiting factor is the worldwide shortage of donated corneas.
In low- and middle-income countries, where the magnitude of corneal blindness is greatest, the availability of donated corneas is very low. This is due in large part to the lack of local eye banks. Efforts are under way to develop eye banks of optimal standards in many low- and middle-income countries, with countries like India and Philippines making notable progress. Myanmar, Ethiopia, and Kenya are examples where high quality eye banks have been established. However, this is still not enough to meet the need for corneas.
The Eye Bank of Ethiopia in Addis Ababa has been in existence since 2003. It is associated with Menelik II Referral Hospital, a tertiary referral centre, where most of the transplants are done. The eye bank also sends corneas to two university referral hospitals in northwestern and southern Ethiopia. Between 130 and 150 corneas are harvested (using in situ corneal excision) and used in 90–120 transplants every year. There are five corneal transplant surgeons in Ethiopia. Cornea donation is encouraged in a variety of ways, including media campaigns with well-known personalities such as the president of Ethiopia and athlete Haile Gabreselassi. So far, 6,000 Ethiopians, including Mr Gabreselassi, have pledged their corneas, and next-of-kin consent is being used increasingly. The eye bank is funded by ORBIS International Ethiopia and Addis Ababa City Government Health Bureau; it also raises funds locally. (Elmien Wolvaardt Ellison)
What is an eye bank?
Eye banks are the institutions responsible for collecting (harvesting) and processing donor corneas, and for distributing them to trained corneal graft surgeons. Eye banks are regulated and part of the local health system; they may be attached to a hospital or housed in a separate building.
Cornea harvesting is the surgical removal from a deceased person of either the whole eye (enucleation) or the cornea (in situ corneal excision). This can be done by appropriately trained eye care personnel (eye bank technicians, ophthalmology residents, ophthalmologists, or general practitioners) in a variety of settings, including hospitals, homes, and funeral grounds.
Before harvesting
Corneas can be harvested up to twelve hours after death, but ideally within six hours. The person who will harvest the cornea must first do the following:
* Obtain written consent from the senior next of kin of the deceased.
* Verify the death certificate and ensure there is a stated cause of death.
* Review the donor's medical and social history to ensure they have no contraindications to donation. (This is done by studying medical records, interviewing the physician under whose care the donor was, and interviewing close family members. Each eye bank must have a list of such contraindications, which are available from other well-established eye banks.)
* Obtain information about any blood loss occurred prior to and at time of death, and whether the donor received infusion/transfusion of crystalloids, colloids, and blood; these are used to calculate plasma dilution.
During harvesting
Aseptic methods must be adhered to, including maintaining a sterile field while performing enucleation or in-situ corneal excision. Standard protocols include:
* pen torch examination of the eyes for foreign objects and other defects
* preparing the face and eyes of the donor using povidone iodine
* employing aseptic techniques for in situ corneal excision or enucleation
* immediate preservation of the excised eye or cornea in an appropriate cornea preservation medium
* drawing blood to screen the donor for infectious diseases. Each eye bank must decide the most appropriate serological tests needed but at a minimum they must test for HIV, hepatits B, and syphilis.
Storing donated corneas
Whole eyes can be stored in a moist chamber at two to eight degrees Celsius. This is the simplest and least expensive way to store whole eyes, but the eyes have to be used within 48 hours. Such a storage method may be suitable for some eye banks with limited resources.
Excised corneas can be stored in intermediate-term preservation media, such as McCary Kaufman medium (MK medium) or Optisol, both maintained at four degrees Celsius. Corneas can be stored for 96 hours in the MK medium and ten days in Optisol.
With the availability of MK medium and Optisol, eye banks should ideally switch over from enucleation to in situ corneal excision procedures. This will enable better viability of donated corneas during storage. With increased resistance to the antibiotics used in preservation media, inclusion of alternative antibiotics must be considered.
After corneas reach the eye bank, they are examined using a slit lamp to check for corneal and stromal pathology. The endothelial cell density is also examined by specular microscope; this is necessary as donor corneas with a low number of endothelial cells are likely to fail soon after surgery. The processing of whole eyes must be done within a laminar flow hood maintained in sterile conditions.
The suitability of a cornea for transplantation is assessed by the corneal surgeon, who will consider the donor screening report, slit lamp and specular microscopic results, and serology reports. Following processing and evaluation of corneas and serological testing, transplantable corneas are transported to hospitals individually sealed and packaged, maintaining the cold chain at four degrees Celcius. The vial containing the cornea must be labelled properly with the eye bank name, tissue number, name of the preservative medium, medium lot number, expiry date of the medium, and date and time of the donor's death. The surgeon must also be provided with the donor screening, tissue evaluation, and serology reports. It is important that the eye bank follows a fair and equitable system of tissue distribution.
Standards
Eye banks should develop and adhere to acceptable standards. This reduces the risk that grafts will fail or that infection will be transmitted. It may help to refer to the technical guidelines and acceptable minimum medical standards of the European Eye Banking Association (see Useful Resources, page 38).
Finding donors
Even with an effective eye bank, finding enough people willing to donate their corneas can be difficult.
Public awareness programmes play an important role. They must emphasise that corneas can be donated by anyone, whatever their age, religion, or gender, and that neither enucleation nor in situ corneal excision causes disfigurement of the face or any delays in funeral arrangements. Family pledging is also becoming more important as family consent is usually needed before eyes or corneas can be removed.
Some of these problems may be circumvented by favourable legislation for eye donation, such as a ‘required request' law. This law requires hospital authorities to identify potential cornea donors and obtain consent from bereaved family members. Another law employed in some countries, such as the United States and Ethiopia, is a ‘presumed consent' law. Under this law, every person who dies while in hospital is presumed to be an eye donor unless this is actively rejected by their next of kin.
Hospital cornea retrieval programmes can meet some of the immediate need. In these programmes, trained eye donation counsellors approach family members of the deceased and motivate them to consider eye donation. Training these counsellors in the art of grief counselling assists them in approaching family members at an appropriate time, sharing their grief, and preparing them to take the positive step of giving permission for eye donation on behalf of their loved one.
Details
What is an eye bank? What do eye bankers do?
Eye banks are facilities where eye bankers restore sight and change lives in their local communities and around the world by facilitating cornea donation and providing ocular tissue for transplant, research, and education.
EBAA eye banks are non-profit organizations that obtain, medically evaluate, and distribute ocular tissue for transplant, research, and education. On average, U.S. EBAA eye banks provide tissue for more than 85,000 sight-restoring corneal transplants each year.
EBAA Member eye banks serve all 50 U.S. states, Washington DC, Puerto Rico, and locations around the world. Eye banks can be eye only, eye and tissue, or part of an organ procurement organization, and they vary in the functions that are performed including: recovery, storage, tissue evaluation, donor eligibility determination, processing, and distribution. Besides core functions, many eye banks conduct or provide tissue for innovative research to advance eye banking and sight restoration.
EBAA Medical Standards and Food and Drug Administration (FDA) regulations are the foundation for eye bank procedures, ensuring that all tissue is recovered, processed, and distributed in adherence to approved medical processes and resulting in the healthiest, most high quality tissue with the best possible outcomes for recipients. The majority of EBAA Member eye banks are EBAA Accredited which assures that their processes and facilities have undergone thorough inspection by peer eye bank professionals and corneal surgeons, meeting or exceeding industry standards and regulations.
Eye Bank Structures
Eye banking organizations vary in structure and functions, but typically fall into these categories:
* Eye Bank Only Functions
* Tissue and Eye Bank Functions
* Recovery Centers
* Processing Centers
* Distribution Centers
* Multicenter Eye Banks
What is an Eye Banker?
While roles vary, generally speaking, an eye banker is an individual who works at/for an eye bank, and is committed to the EBAA mission to #RestoreSight worldwide.
Departments/Eye Banking Roles
Eye banks typically consist of the departments outlined below, with eye bankers working in various roles.
Donor Eligibility
Review potential donors’ medical history to verify if the donor is eligible to donate.
Recovery
Procure ocular tissue from deceased donors who have been cleared for donation through first person authorization, or consent from the next of kin.
Evaluation
Evaluate tissue using slit lamp and specular microscopes, as well as other equipment to assess the health and quality of the tissue.
Processing
Perform procedures to prepare the tissue for transplant, this can include testing for microorganisms, preparing the tissue, manipulating or resizing the tissue based on surgical specifications, sterilizing the tissue, or removing adventitious agents.
Distribution
Work with surgical centers, hospitals, and practices, to fulfill requests for tissue. Package and ship tissue for transplant and research.
Quality Assurance
Develop, implement, and monitor quality systems and quality assurance as it relates to regulatory compliance, departmental, and organizational strategic goals and processes.
Hospital Development/ Partner Relations/ Community Outreach
Build and strengthen relationships with the local community, hospitals, hospices, funeral homes, medical examiner/ coroner offices and other third-party organizations.
Family Services
Provide information and resources to donor family members and cornea recipients.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2255 2024-08-14 00:17:29
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2257) Papaya
Details
The papaya, papaw, or pawpaw is the plant species Carica papaya, one of the 21 accepted species in the genus Carica of the family Caricaceae, and also the name of its fruit. It was first domesticated in Mesoamerica, within modern-day southern Mexico and Central America. It is grown in several countries in regions with a tropical climate. In 2022, India produced 38% of the world's supply of papayas.
Etymology
The word papaya derives from Arawak via Spanish, and is also the name for the plant. The name papaw or pawpaw is used alternatively for the fruit only in some regions.
Description
The papaya is a small, sparsely branched tree, usually with a single stem growing from 5 to 10 m (16 to 33 ft) tall, with spirally arranged leaves confined to the top of the trunk. The lower trunk is conspicuously scarred where leaves and fruit were borne. The leaves are large, 50–70 cm (20–28 in) in diameter, deeply palmately lobed, with seven lobes. All plant parts contain latex in articulated laticifers.
Flowers
Papayas are dioecious. The flowers are five-parted and highly dimorphic; the male flowers have the stamens fused to the petals. There are two different types of papaya flowers. The female flowers have a superior ovary and five contorted petals loosely connected at the base.
Male and female flowers are borne in the leaf axils; the male flowers are in multiflowered dichasia, and the female ones are in few-flowered dichasia. The pollen grains are elongated and approximately 35 microns in length. The flowers are sweet-scented, open at night, and are wind- or insect-pollinated.
Fruit
The fruit is a large berry about 15–45 cm (6–17+3/4 in) long and 10–30 cm (4–11+3/4 in) in diameter. It is ripe when it feels soft (as soft as a ripe avocado or softer), its skin has attained an amber to orange hue and along the walls of the large central cavity are attached numerous black seeds.
Chemistry
Papaya skin, pulp, and seeds contain a variety of phytochemicals, including carotenoids and polyphenols, as well as benzyl isothiocyanates and benzyl glucosinates, with skin and pulp levels that increase during ripening. The carotenoids, lutein and beta-carotene, are prominent in the yellow skin, while lycopene is dominant in the red flesh (table). Papaya seeds also contain the cyanogenic substance prunasin. The green fruit contains papain, a cysteine protease enzyme used to tenderize meat.
Distribution and habitat
Native to tropical America, papaya originates from southern Mexico and Central America. Papaya is also considered native to southern Florida, introduced by predecessors of the Calusa no later than AD 300. Spaniards introduced papaya to the Old World in the 16th century. Papaya cultivation is now nearly pantropical, spanning Hawaii, Central Africa, India, and Australia.
Wild populations of papaya are generally confined to naturally disturbed tropical forests. Papaya is found in abundance on Everglades hammocks following major hurricanes, but is otherwise infrequent. In the rain forests of southern Mexico, papaya thrives and reproduces quickly in canopy gaps while dying off in the mature closed-canopy forests.
Ecology
Viruses
Papaya ringspot virus is a well-known virus within plants in Florida. The first signs of the virus are yellowing and vein-clearing of younger leaves and mottling yellow leaves. Infected leaves may obtain blisters, roughen, or narrow, with blades sticking upwards from the middle of the leaves. The petioles and stems may develop dark green greasy streaks and, in time, become shorter. The ringspots are circular, C-shaped markings that are a darker green than the fruit. In the later stages of the virus, the markings may become gray and crusty. Viral infections impact growth and reduce the fruit's quality. One of the biggest effects that viral infections have on papaya is taste. As of 2010, the only way to protect papaya from this virus is genetic modification.
The papaya mosaic virus destroys the plant until only a small tuft of leaves is left. The virus affects both the leaves of the plant and the fruit. Leaves show thin, irregular, dark-green lines around the borders and clear areas around the veins. The more severely affected leaves are irregular and linear in shape. The virus can infect the fruit at any stage of its maturity. Fruits as young as two weeks old have been spotted with dark-green ringspots about 1 inch (25 mm) in diameter. Rings on the fruit are most likely seen on either the stem end or the blossom end. In the early stages of the ringspots, the rings tend to be many closed circles, but as the disease develops, the rings increase in diameter consisting of one large ring. The difference between the ringspot and the mosaic viruses is the ripe fruit in the ringspot has a mottling of colors, and the mosaic does not.
Fungi and oomycetes
The fungus anthracnose is known to attack papaya, especially mature fruits. The disease starts small with very few signs, such as water-soaked spots on ripening fruits. The spots become sunken, turn brown or black, and may get bigger. In some of the older spots, the fungus may produce pink spores. The fruit ends up being soft and having an off flavor because the fungus grows into the fruit.
The fungus powdery mildew occurs as a superficial white presence on the leaf's surface, which is easily recognized. Tiny, light yellow spots begin on the lower surfaces of the leaf as the disease starts to make its way. The spots enlarge, and white powdery growth appears on the leaves. The infection usually appears at the upper leaf surface as white fungal growth. Powdery mildew is not as severe as other diseases.
The fungus-like oomycete Phytophthora causes damping-off, root rot, stem rot, stem girdling, and fruit rot. Damping-off happens in young plants by wilting and death. The spots on established plants start as white, water-soaked lesions at the fruit and branch scars. These spots enlarge and eventually cause death. The disease's most dangerous feature is the fruit's infection, which may be toxic to consumers. The roots can also be severely and rapidly infected, causing the plant to brown and wilt away, collapsing within days.
Pests
The papaya fruit fly lays its eggs inside of the fruit, possibly up to 100 or more eggs. The eggs usually hatch within 12 days when they begin to feed on seeds and interior parts of the fruit. When the larvae mature, usually 16 days after being hatched, they eat their way out of the fruit, drop to the ground, and pupate in the soil to emerge within one to two weeks later as mature flies. The infected papaya turns yellow and drops to the ground after the papaya fruit fly infestation.
The two-spotted spider mite is a 0.5-mm-long brown or orange-red or a green, greenish-yellow translucent oval pest. They all have needle-like piercing-sucking mouthparts and feed by piercing the plant tissue with their mouthparts, usually on the underside of the plant. The spider mites spin fine threads of webbing on the host plant, and when they remove the sap, the mesophyll tissue collapses, and a small chlorotic spot forms at the feeding sites. The leaves of the papaya fruit turn yellow, gray, or bronze. If the spider mites are not controlled, they can cause the death of the fruit.
The papaya whitefly lays yellow, oval eggs that appear dusted on the undersides of the leaves. They eat papaya leaves, therefore damaging the fruit. There, the eggs developed into flies in three stages called instars. The first instar has well-developed legs and is the only mobile immature life stage. The crawlers insert their mouthparts in the lower surfaces of the leaf when they find it suitable and usually do not move again in this stage. The next instars are flattened, oval, and scale-like. In the final stage, the pupal whiteflies are more convex, with large, conspicuously red eyes.
Papayas are one of the most common hosts for fruit flies like A. suspensa, which lay their eggs in overripe or spoiled papayas. The larvae of these flies then consume the fruit to gain nutrients until they can proceed into the pupal stage. This parasitism has led to extensive economic costs for nations in Central America.
Cultivation
Historical accounts from 18th-century travelers and botanists suggested that papaya seeds were transported from the Caribbean to Malacca and then to India. From Malacca or the Philippines, papaya spread throughout Asia and into the South Pacific region. Credit for introducing papaya to Hawaii is often given to Francisco de Paula Marín, a Spanish explorer and horticulturist, who brought it from the Marquesas Islands in the early 1800s. Since then, papaya cultivation has expanded to all tropical countries and many subtropical regions worldwide. Today, papaya is grown extensively across the globe, owing to its adaptability to various climates and its popularity as a tropical fruit.
Papaya plants grow in three sexes: male, female, and hermaphrodite. The male produces only pollen, never fruit. The female produces small, inedible fruits unless pollinated. The hermaphrodite can self-pollinate since its flowers contain both male stamens and female ovaries. Almost all commercial papaya orchards contain only hermaphrodites.
Originally from southern Mexico (particularly Chiapas and Veracruz), Central America, northern South America, and southern Florida the papaya is now cultivated in most tropical countries. In cultivation, it grows rapidly, fruiting within three years. It is, however, highly frost-sensitive, limiting its production to tropical climates. Temperatures below −2 °C (29 °F) are greatly harmful, if not fatal. In Florida, California, and Texas, growth is generally limited to the southern parts of those states. It prefers sandy, well-drained soil, as standing water can kill the plant within 24 hours.
Cultivars
Two kinds of papayas are commonly grown. One has sweet, red, or orange flesh, and the other has yellow flesh; in Australia, these are called "red papaya" and "yellow papaw," respectively. Either kind, picked green, is called a "green papaya."
The large-fruited, red-fleshed 'Maradol,' 'Sunrise,' and 'Caribbean Red' papayas often sold in U.S. markets are commonly grown in Mexico and Belize.
In 2011, Philippine researchers reported that by hybridizing papaya with Vasconcellea quercifolia, they had developed papaya resistant to papaya ringspot virus (PRV), part of a long line of attempts to transfer resistance from Vasconcellea species into papaya.
Genetically engineered cultivars
Carica papaya was the first transgenic fruit tree to have its genome sequenced. In response to the papaya ringspot virus outbreak in Hawaii in 1998, genetically altered papaya were approved and brought to market (including 'SunUp' and 'Rainbow' varieties.) Varieties resistant to PRV have some DNA of this virus incorporated into the plant's DNA. As of 2010, 80% of Hawaiian papaya plants were genetically modified. The modifications were made by University of Hawaii scientists, who made the modified seeds available to farmers without charge.
In transgenic papaya, resistance is produced by inserting the viral coat protein gene into the plant's genome. Doing so seems to cause a similar protective reaction in the plant to cross-protection, which involves using an attenuated virus to protect against a more dangerous strain. Conventional varieties of transgenic papaya has reduced resistance against heterologous (not closely related to the coat gene source) strains, forcing different localities to develop their own transgenic varieties. As of 2016, one transgenic line appears able to deal with three different heterologous strains in addition to its source.
Production
In 2022, global production of papayas was 13.8 million tonnes, led by India with 38% of the world total. Global papaya production grew significantly over the early 21st century, mainly as a result of increased production in India and demand by the United States. The United States is the largest consumer of papayas worldwide.
In South Africa, papaya orchards yield up to 100 tonnes of fruit per hectare.
Toxicity
Papaya releases a latex fluid when not ripe, possibly causing irritation and an allergic reaction in some people. Because the enzyme papain acts as an allergen in sensitive individuals, meat that has been tenderized with it may induce an allergic reaction.
Culinary use
The ripe fruit of the papaya is usually eaten raw, without skin or seeds. The black seeds are edible and have a sharp, spicy taste. The unripe green fruit is usually cooked due to its latex content.
Both green papaya fruit and its latex are rich in papain, a cysteine protease used for tenderizing meat and other proteins, as practiced currently by indigenous Americans, people of the Caribbean region, and the Philippines. It is included as a component in some powdered meat tenderizers. Papaya is not suitable for foods which set due to gelatin (such as jelly or aspic) because the enzymatic properties of papain prevent gelatin from setting.
Nutrition
Raw papaya pulp contains 88% water, 11% carbohydrates, and negligible fat and protein. In a 100-g amount, papaya fruit provides 43 kilocalories and is a significant source of vitamin C (75% of the Daily Value, DV) and a moderate source of folate (10% DV), but otherwise has a low content of nutrients.
Additional Information
Papayas contain a range of nutrients, such as antioxidants and potassium. Possible health benefits of eating papaya may include reducing the risk of heart disease, diabetes, cancer, and more.
Papaya, papaw, or pawpaw, is a soft, fleshy fruit of the plant species Carica papaya.
This article examines the possible health benefits and uses of papaya fruit, its nutritional value, and how to incorporate more papaya into a diet.
Fast facts on papaya:
* Papaya is native to Mexico. However, it grows naturally in the Caribbean and Florida too.
* According to the Food and Agriculture Organization of the United Nations (FAO), India produces the most papayas – over 5 million tons in 2013.
* It can be added to salads, smoothies, and other dishes.
The nutrients in papaya may have a range of health benefits. They may help protect against a number of health conditions.
Vision and eye health
Some of the organic compounds present in papaya may help prevent inflammation and oxidative stress in age-related eye diseases, such as macular degeneration.
One of these compounds, called lycopene, may help protect the retinal pigment epithelium — a part of the retina essential for healthy vision — against inflammation and oxidative stress.
Papaya also contains carotene, a compound that gives the papaya its distinctive orange color. Carotene has links to vision improvement and the prevention of night blindness.
Zeaxanthin, an antioxidant in papaya, filters out harmful blue light rays. It is thought to play a protective role in eye health and may ward off macular degeneration.
Asthma
Consuming a high amount of fruits and vegetables lowers the risk of developing asthma and can prevent the condition from worsening.
This may be due to dietary components in fruits and vegetables, such as antioxidants, fiber, and vitamin D. These nutrients can assist the immune system’s typical functioning, which over-responds in people with asthma.
One 2022 study also linked a higher intake of carotenes, lycopene, and zeaxanthin to a lower risk of developing asthma in adults. Papaya contains all three of these organic compounds.
A 2017 animal study also found that papaya leaf extract has an anti-inflammatory effect on the airways of mice. However, more research is necessary into the effect of papaya leaf extract on humans.
Cancer
Many of the compounds present in papaya — such as lycopene, zeaxanthin, and lutein, may have anticancer effects.
A 2022 review explained that some studies have shown that lycopene has anticancer properties, particularly against prostate cancer. However, the researchers mentioned more research is necessary to determine the recommended doses.
A 2020 study suggested that zeaxanthin may have a beneficial effect on gastric cancer cells.
Another 2018 study also found that lutein selectively slows the growth of breast cancer cells.
Additionally, eating a diet rich in fruits and vegetables can help reduce the risk of cancer more generally. Generally, plants with the most color — dark green, yellow, red, and orange — have the most nutrients.
Bone health
Papaya is a source of vitamin K. Low intakes of vitamin K have associations with a higher risk of bone fracture.
Adequate vitamin K consumption is important for good health. It improves calcium absorption and may reduce urinary excretion of calcium, meaning there is more calcium in the body to strengthen and rebuild bones.
Diabetes
Studies have shown that people with type 1 diabetes who consume high fiber diets have lower blood glucose levels. Additionally, those with type 2 diabetes following high fiber diets may have improved blood sugar, lipid, and insulin levels.
One small papaya provides nearly 3 grams (g) of fiber, with only 17 g of carbohydrates.
Digestion
Papaya is high in fiber and water content, which help prevent constipation and promote regularity and a healthy digestive tract.
Heart disease
Antioxidants in papaya, such as lycopene, may reduce the risk of heart disease and stroke. Papaya also contains fiber, which research shows may help lower cholesterol.
It is also high in potassium, which can be beneficial for those with high blood pressure.
An increase in potassium intake along with a decrease in sodium intake is the most important dietary change someone can make to reduce their risk of cardiovascular disease.
Hair health
Papaya is also great for hair because it contains vitamin A, a nutrient necessary for sebum production, which keeps hair moisturized.
Vitamin A is also necessary for the growth of all bodily tissues, including skin and hair.
Adequate intake of vitamin C, which papaya can provide, is necessary for the building and maintenance of collagen, which provides structure to the skin.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2256 2024-08-15 00:19:10
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2258) Prime Meridian
Prime Meridian
Gist
The prime meridian is the imaginary line that divides Earth into two equal parts: the Eastern Hemisphere and the Western Hemisphere. The prime meridian is also used as the basis for the world's time zones. The prime meridian appears on maps and globes. It is the starting point for the measuring system called longitude.
The prime meridian is the line of 0° longitude, the starting point for measuring distance both east and west around Earth. The prime meridian is arbitrary, meaning it could be chosen to be anywhere. Any line of longitude (a meridian) can serve as the 0° longitude line.
Summary
The prime meridian is the line of 0° longitude, the starting point for measuring distance both east and west around Earth. The prime meridian is arbitrary, meaning it could be chosen to be anywhere.
The prime meridian is the line of 0° longitude, the starting point for measuring distance both east and west around Earth.
The prime meridian is arbitrary, meaning it could be chosen to be anywhere. Any line of longitude (a meridian) can serve as the 0° longitude line. However, there is an international agreement that the meridian that runs through Greenwich, England, is considered the official prime meridian.
Governments did not always agree that the Greenwich meridian was the prime meridian, making navigation over long distances very difficult. Different countries published maps and charts with longitude based on the meridian passing through their capital city. France published maps with 0° longitude running through Paris. Cartographers in China published maps with 0° longitude running through Beijing. Even different parts of the same country published materials based on local meridians.
Finally, at an international convention called by U.S. President Chester Arthur in 1884, representatives from 25 countries agreed to pick a single, standard meridian. They chose the meridian passing through the Royal Observatory in Greenwich, England. The Greenwich Meridian became the international standard for the prime meridian.
UTC
The prime meridian also sets Coordinated Universal Time (UTC). UTC never changes for daylight savings or anything else. Just as the prime meridian is the standard for longitude, UTC is the standard for time. All countries and regions measure their time zones according to UTC.
There are 24 time zones in the world. If an event happens at 11:00 a.m. in Houston, Texas, United States, it would be reported at 12 p.m. in Orlando, Florida, United States; 4:00 p.m. in Morocco; 9:00 p.m. in Kolkata, India; and 6:00 a.m. in Honolulu, Hawai'i, United States. The event happened at 4:00 p.m. UTC.
The prime meridian also helps establish the International Date Line. Earth's longitude measures 360°, so the halfway point from the prime meridian is the 180° longitude line. The meridian at 180° longitude is commonly known as the International Date Line. As you pass the International Date Line, you either add a day (going west) or subtract a day (going east.)
Hemispheres
The prime meridian and the International Date Line create a circle that divides Earth into the Eastern and Western Hemispheres. This is similar to the way the Equator serves as the 0° latitude line and divides Earth into the northern and southern hemispheres.
The Eastern Hemisphere is east of the prime meridian and west of the International Date Line. Most of Earth's landmasses, including all of Asia and Australia, and most of Africa, are part of the Eastern Hemisphere.
The Western Hemisphere is west of the prime meridian and east of the International Date Line. The Americas, the western part of the British Isles (including Ireland and Wales), and the northwestern part of Africa are land masses in the Western Hemisphere.
Details
A prime meridian is an arbitrarily-chosen meridian (a line of longitude) in a geographic coordinate system at which longitude is defined to be 0°. Together, a prime meridian and its anti-meridian (the 180th meridian in a 360°-system) form a great circle. This great circle divides a spheroid, like Earth, into two hemispheres: the Eastern Hemisphere and the Western Hemisphere (for an east-west notational system). For Earth's prime meridian, various conventions have been used or advocated in different regions throughout history. Earth's current international standard prime meridian is the IERS Reference Meridian. It is derived, but differs slightly, from the Greenwich Meridian, the previous standard.
A prime meridian for a planetary body not tidally locked (or at least not in synchronous rotation) is entirely arbitrary, unlike an equator, which is determined by the axis of rotation. However, for celestial objects that are tidally locked (more specifically, synchronous), their prime meridians are determined by the face always inward of the orbit (a planet facing its star, or a moon facing its planet), just as equators are determined by rotation.
Longitudes for the Earth and Moon are measured from their prime meridian (at 0°) to 180° east and west. For all other Solar System bodies, longitude is measured from 0° (their prime meridian) to 360°. West longitudes are used if the rotation of the body is prograde (or 'direct', like Earth), meaning that its direction of rotation is the same as that of its orbit. East longitudes are used if the rotation is retrograde.
History
The notion of longitude for Greeks was developed by the Greek Eratosthenes (c. 276 – 195 BCE) in Alexandria, and Hipparchus (c. 190 – 120 BCE) in Rhodes, and applied to a large number of cities by the geographer Strabo (64/63 BCE – c. 24 CE). But it was Ptolemy (c. 90 – 168 CE) who first used a consistent meridian for a world map in his Geographia.
Ptolemy used as his basis the "Fortunate Isles", a group of islands in the Atlantic, which are usually associated with the Canary Islands (13° to 18°W), although his maps correspond more closely to the Cape Verde islands (22° to 25° W). The main point is to be comfortably west of the western tip of Africa (17.5° W) as negative numbers were not yet in use. His prime meridian corresponds to 18° 40' west of Winchester (about 20°W) today. At that time the chief method of determining longitude was by using the reported times of lunar eclipses in different countries.
One of the earliest known descriptions of standard time in India appeared in the 4th century CE astronomical treatise Surya Siddhanta. Postulating a spherical Earth, the book described the thousands years old customs of the prime meridian, or zero longitude, as passing through Avanti, the ancient name for the historic city of Ujjain, and Rohitaka, the ancient name for Rohtak (28°54′N 76°38′E), a city near the Kurukshetra.
Ptolemy's Geographia was first printed with maps at Bologna in 1477, and many early globes in the 16th century followed his lead. But there was still a hope that a "natural" basis for a prime meridian existed. Christopher Columbus reported (1493) that the compass pointed due north somewhere in mid-Atlantic, and this fact was used in the important Treaty of Tordesillas of 1494, which settled the territorial dispute between Spain and Portugal over newly discovered lands. The Tordesillas line was eventually settled at 370 leagues (2,193 kilometers, 1,362 statute miles, or 1,184 nautical miles) west of Cape Verde. This is shown in the copies of Spain's Padron Real made by Diogo Ribeiro in 1527 and 1529. São Miguel Island (25.5°W) in the Azores was still used for the same reason as late as 1594 by Christopher Saxton, although by then it had been shown that the zero magnetic declination line did not follow a line of longitude.
In 1541, Mercator produced his famous 41 cm terrestrial globe and drew his prime meridian precisely through Fuerteventura (14°1'W) in the Canaries. His later maps used the Azores, following the magnetic hypothesis. But by the time that Ortelius produced the first modern atlas in 1570, other islands such as Cape Verde were coming into use. In his atlas longitudes were counted from 0° to 360°, not 180°W to 180°E as is usual today. This practice was followed by navigators well into the 18th century. In 1634, Cardinal Richelieu used the westernmost island of the Canaries, El Hierro, 19° 55' west of Paris, as the choice of meridian. The geographer Delisle decided to round this off to 20°, so that it simply became the meridian of Paris disguised.
In the early 18th century the battle was on to improve the determination of longitude at sea, leading to the development of the marine chronometer by John Harrison. But it was the development of accurate star charts, principally by the first British Astronomer Royal, John Flamsteed between 1680 and 1719 and disseminated by his successor Edmund Halley, that enabled navigators to use the lunar method of determining longitude more accurately using the octant developed by Thomas Godfrey and John Hadley.
In the 18th century most countries in Europe adapted their own prime meridian, usually through their capital, hence in France the Paris meridian was prime, in Prussia it was the Berlin meridian, in Denmark the Copenhagen meridian, and in United Kingdom the Greenwich meridian.
Between 1765 and 1811, Nevil Maskelyne published 49 issues of the Nautical Almanac based on the meridian of the Royal Observatory, Greenwich. "Maskelyne's tables not only made the lunar method practicable, they also made the Greenwich meridian the universal reference point. Even the French translations of the Nautical Almanac retained Maskelyne's calculations from Greenwich – in spite of the fact that every other table in the Connaissance des Temps considered the Paris meridian as the prime."
In 1884, at the International Meridian Conference in Washington, D.C., 22 countries voted to adopt the Greenwich meridian as the prime meridian of the world. The French argued for a neutral line, mentioning the Azores and the Bering Strait, but eventually abstained and continued to use the Paris meridian until 1911.
The current international standard Prime Meridian is the IERS Reference Meridian. The International Hydrographic Organization adopted an early version of the IRM in 1983 for all nautical charts. It was adopted for air navigation by the International Civil Aviation Organization on 3 March 1989.
International prime meridian
Since 1984, the international standard for the Earth's prime meridian is the IERS Reference Meridian. Between 1884 and 1984, the meridian of Greenwich was the world standard. These meridians are very close to each other.
Prime meridian at Greenwich
In October 1884 the Greenwich Meridian was selected by delegates (forty-one delegates representing twenty-five nations) to the International Meridian Conference held in Washington, D.C., United States to be the common zero of longitude and standard of time reckoning throughout the world.
The position of the historic prime meridian, based at the Royal Observatory, Greenwich, was established by Sir George Airy in 1851. It was defined by the location of the Airy Transit Circle ever since the first observation he took with it. Prior to that, it was defined by a succession of earlier transit instruments, the first of which was acquired by the second Astronomer Royal, Edmond Halley in 1721. It was set up in the extreme north-west corner of the Observatory between Flamsteed House and the Western Summer House. This spot, now subsumed into Flamsteed House, is roughly 43 metres (47 yards) to the west of the Airy Transit Circle, a distance equivalent to roughly 2 seconds of longitude. It was Airy's transit circle that was adopted in principle (with French delegates, who pressed for adoption of the Paris meridian abstaining) as the Prime Meridian of the world at the 1884 International Meridian Conference.
All of these Greenwich meridians were located via an astronomic observation from the surface of the Earth, oriented via a plumb line along the direction of gravity at the surface. This astronomic Greenwich meridian was disseminated around the world, first via the lunar distance method, then by chronometers carried on ships, then via telegraph lines carried by submarine communications cables, then via radio time signals. One remote longitude ultimately based on the Greenwich meridian using these methods was that of the North American Datum 1927 or NAD27, an ellipsoid whose surface best matches mean sea level under the United States.
IERS Reference Meridian
Beginning in 1973 the International Time Bureau and later the International Earth Rotation and Reference Systems Service changed from reliance on optical instruments like the Airy Transit Circle to techniques such as lunar laser ranging, satellite laser ranging, and very-long-baseline interferometry. The new techniques resulted in the IERS Reference Meridian, the plane of which passes through the centre of mass of the Earth. This differs from the plane established by the Airy transit, which is affected by vertical deflection (the local vertical is affected by influences such as nearby mountains). The change from relying on the local vertical to using a meridian based on the centre of the Earth caused the modern prime meridian to be 5.3″ east of the astronomic Greenwich prime meridian through the Airy Transit Circle. At the latitude of Greenwich, this amounts to 102 metres (112 yards). This was officially accepted by the Bureau International de l'Heure (BIH) in 1984 via its BTS84 (BIH Terrestrial System) that later became WGS84 (World Geodetic System 1984) and the various International Terrestrial Reference Frames (ITRFs).
Due to the movement of Earth's tectonic plates, the line of 0° longitude along the surface of the Earth has slowly moved toward the west from this shifted position by a few centimetres (inches); that is, towards the Airy Transit Circle (or the Airy Transit Circle has moved toward the east, depending on your point of view) since 1984 (or the 1960s). With the introduction of satellite technology, it became possible to create a more accurate and detailed global map. With these advances there also arose the necessity to define a reference meridian that, whilst being derived from the Airy Transit Circle, would also take into account the effects of plate movement and variations in the way that the Earth was spinning. As a result, the IERS Reference Meridian was established and is commonly used to denote the Earth's prime meridian (0° longitude) by the International Earth Rotation and Reference Systems Service, which defines and maintains the link between longitude and time. Based on observations to satellites and celestial compact radio sources (quasars) from various coordinated stations around the globe, Airy's transit circle drifts northeast about 2.5 centimetres (1 inch) per year relative to this Earth-centred 0° longitude.
It is also the reference meridian of the Global Positioning System operated by the United States Department of Defense, and of WGS84 and its two formal versions, the ideal International Terrestrial Reference System (ITRS) and its realization, the International Terrestrial Reference Frame (ITRF). A current convention on the Earth uses the line of longitude 180° opposite the IRM as the basis for the International Date Line.
Additional Information
The Greenwich meridian is a prime meridian, a geographical reference line that passes through the Royal Observatory, Greenwich, in London, England. From 1884 to 1974, the Greenwich meridian was the international standard prime meridian, used worldwide for timekeeping and navigation. The modern standard, the IERS Reference Meridian, is based on the Greenwich meridian, but differs slightly from it. This prime meridian (at the time, one of many) was first established by Sir George Airy in 1851, and by 1884, over two-thirds of all ships and tonnage used it as the reference meridian on their charts and maps. In October of that year, at the invitation of the President of the United States, 41 delegates from 25 nations met in Washington, D.C., United States, for the International Meridian Conference. This conference selected the meridian passing through Greenwich as the world standard prime meridian due to its popularity. However, France abstained from the vote, and French maps continued to use the Paris meridian for several decades. In the 18th century, London lexicographer Malachy Postlethwayt published his African maps showing the "Meridian of London" intersecting the Equator a few degrees west of the later meridian and Accra, Ghana.
The plane of the prime meridian is parallel to the local gravity vector at the Airy transit circle (51°28′40.1″N 0°0′5.3″W) of the Greenwich observatory. The prime meridian was therefore long symbolised by a brass strip in the courtyard, now replaced by stainless steel, and since 16 December 1999, it has been marked by a powerful green laser shining north across the London night sky.
The Global Positioning System (GPS) receivers show that the marking strip for the prime meridian at Greenwich is not exactly at zero degrees, zero minutes, and zero seconds but at approximately 5.3 seconds of arc to the west of the meridian (meaning that the meridian appears to be 102 metres east). In the past, this offset has been attributed to the establishment of reference meridians for space-based location systems such as WGS-84 (which the GPS relies on) or to the fact that errors gradually crept into the International Time Bureau timekeeping process. The actual reason for the discrepancy is that the difference between precise GNSS coordinates and astronomically determined coordinates everywhere remains a localized gravity effect due to vertical deflection; thus, no systematic rotation of global longitudes occurred between the former astronomical system and the current geodetic system.
History
Before the establishment of a common meridian, most maritime countries established their own prime meridian, usually passing through the country in question. In 1721, Great Britain established its own meridian passing through an early transit circle at the newly established Royal Observatory at Greenwich. The meridian was moved around 10 metres or so east on three occasions as transit circles with newer and better instruments were built, on each occasion next door to the existing one. This was to allow uninterrupted observation during each new construction. The final meridian was established as an imaginary line from the North Pole to the South Pole passing through the Airy transit circle. This became the United Kingdom's meridian in 1851. For all practical purposes of the period, the changes as the meridian was moved went unnoticed.
Transit instruments are installed to be perpendicular to the local level (which is a plane perpendicular to a plumb line). In 1884, the International Meridian Conference took place in Washington, D.C. to establish an internationally-recognised single meridian. The meridian chosen was that which passed through the Airy transit circle at Greenwich, and it became the prime meridian of the world for a century. In 1984 it was superseded in that role by the IERS Reference Meridian which, at this latitude, runs about 102 metres to the east of the Greenwich meridian.
At around the time of the 1884 conference, scientists were making measurements to determine the deflection of the vertical on a large scale. One might expect that plumb lines set up in various locations, if extended downward, would all pass through a single point, the centre of Earth, but this is not the case, primarily due to Earth being an ellipsoid, not a sphere. The downward extended plumb lines don't even all intersect the rotation axis of Earth; this much smaller effect is due to the uneven distribution of Earth's mass. To make computations feasible, scientists defined ellipsoids of revolution, more closely emulating the shape of Earth, modified for a particular zone; a published ellipsoid would be a good base line for measurements. The difference between the direction of a plumb line or vertical, and a line perpendicular to the surface of the ellipsoid of revolution – a normal to said ellipsoid – at a particular observatory, is the deflection of the vertical.
When the Airy transit circle was built, a mercury basin was used to align the telescope to the perpendicular. Thus the circle was aligned with the local vertical or plumb line, which is deflected slightly from the normal, or line perpendicular, to the reference ellipsoid used to define geodetic latitude and longitude in the International Terrestrial Reference Frame (which is nearly the same as the WGS84 system used by the GPS). While Airy's local vertical, set by the apparent centre of gravity of Earth still points to (aligns with) the modern celestial meridian (the intersection of the prime meridian plane with the celestial sphere), it does not pass through Earth's rotation axis. As a result of this, the ITRF zero meridian, defined by a plane passing through Earth's rotation axis, is 102.478 metres to the east of the prime meridian. A 2015 analysis by Malys et al. shows the offset between the former and the latter can be explained by this deflection of the vertical alone; other possible sources of the offset that have been proposed in the past are smaller than the current uncertainty in the deflection of the vertical, locally. The astronomical longitude of the Greenwich prime meridian was found to be 0.19″ ±&nbp;s0.47″ E, i.e. the plane defined by the local vertical on the Greenwich prime meridian and the plane passing through Earth's rotation axis on the ITRF zero meridian are effectively parallel. Claims, such as that on the BBC website, that the gap between astronomical and geodetic coordinates means that any measurements of transit time across the IRTF zero meridian will occur precisely 0.352 seconds (or 0.353 sidereal seconds) before the transit across the "intended meridian" are based on a failure of understanding. The explanation by Malys et al. on the other hand is more studied and correct.
More Information
The prime meridian is the imaginary line that divides Earth into two equal parts: the Eastern Hemisphere and the Western Hemisphere. The prime meridian is also used as the basis for the world’s time zones.
The prime meridian appears on maps and globes. It is the starting point for the measuring system called longitude. Longitude is a system of imaginary north-south lines called meridians. They connect the North Pole to the South Pole. Meridians are used to measure distance in degrees east or west from the prime meridian. The prime meridian is 0° longitude. The 180th meridian is the line of longitude that is exactly opposite the prime meridian. It is 180° longitude. Lines of longitude east of the prime meridian are numbered from 1 to 179 east (E). Lines of longitude west of the prime meridian are numbered from 1 to 179 west (W).
The prime meridian is also called the Greenwich meridian because it passes through Greenwich, England. Before 1884 map makers usually began numbering the lines of longitude on their maps at whichever meridian passed through the site of their national observatory. Many countries used British maps because Great Britain was a world leader in exploration and map making. In 1884, therefore, scientists decided that the starting point of longitude for everyone would be the meridian running through Britain’s royal observatory in Greenwich.
It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2257 2024-08-16 00:17:45
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2259) Professor
Gist
i) a university teacher of the highest level.
ii) American : a teacher at a college or university.
Summary
Professor (often shortened to Prof.) is an academic rank at most universities and colleges. The word professor comes from Latin. It means a "person who professes", so professors are usually experts in arts or sciences. A professor is a teacher of the highest rank. Professors are often active in research. In many institutions, the job title 'professor' means the same as "instructor".
Description
A professor is an accomplished and recognized academic. In most Commonwealth nations, as well as northern Europe, the title professor is the highest academic rank at a university. In the United States and Canada, the title of professor is also the highest rank, but a higher percentage achieve it. In these areas, professors are scholars with doctorate degrees (typically Ph.D. degrees) or equivalent qualifications, though some have master's degrees. Most professors teach in four-year colleges and universities. An emeritus professor is a title given to selected retired professors with whom the university wishes to continue to be associated due to their stature and ongoing research. Emeritus professors do not receive a salary. However, they are often given office or lab space, and use of libraries, labs, and so on.
The term professor is also used in the titles assistant professor and associate professor, which are not considered non-tenured professors. In Australia, the title associate professor is used in place of reader, ranking above senior lecturer and below full professor.
Beyond holding the proper academic title, universities in many countries also give notable artists, athletes and foreign dignitaries the title honorary professor, even if these persons do not have the academic qualifications typically necessary for professorship and they do not take up professorial duties. However, such "professors" usually do not undertake academic work for the granting institution. In general, the title of professor is strictly used for academic positions rather than for those holding it on honorary basis.
Adjunct
An adjunct professor, also called an adjunct lecturer or adjunct instructor is a non-tenure position in the U.S. and Canada. They usually rank below a full professor. They are usually hired on a contract basis. They are often hired as part-time instructors especially at universities and colleges with tightening budgets. The position of an adjunct can often lead to a full-time professorship. It is also an opportunity for professionals to teach part-time.
Salary
A professor's salary can vary by education, school, subject taught and country. A professor typically earns a base salary and a range of benefits. In addition, a professor who undertakes additional roles in her institution (e.g., department chair, dean, head of graduate studies, etc.) earns additional income. In the United States, in 2014, a tenured Law professor made an average of $143,509 a year. By comparison, those teaching history, English, the Arts or Theology make about half that amount. But both are far above the median income for a person in the US
Details
Professor (commonly abbreviated as Prof.) is an academic rank at universities and other post-secondary education and research institutions in most countries. Literally, professor derives from Latin as a "person who professes". Professors are usually experts in their field and teachers of the highest rank.
In most systems of academic ranks, "professor" as an unqualified title refers only to the most senior academic position, sometimes informally known as "full professor". In some countries and institutions, the word professor is also used in titles of lower ranks such as associate professor and assistant professor; this is particularly the case in the United States, where the unqualified word is also used colloquially to refer to associate and assistant professors as well, and often to instructors or lecturers.
Professors often conduct original research and commonly teach undergraduate, postgraduate, or professional courses in their fields of expertise. In universities with graduate schools, professors may mentor and supervise graduate students conducting research for a thesis or dissertation. In many universities, full professors take on senior managerial roles such as leading departments, research teams and institutes, and filling roles such as president, principal or vice-chancellor. The role of professor may be more public-facing than that of more junior staff, and professors are expected to be national or international leaders in their field of expertise.
Etymology
The term professor was first used in the late 14th century to mean 'one who teaches a branch of knowledge'. The word comes "...from Old French professeur (14c.) and directly from [the] Latin professor[, for] 'person who professes to be an expert in some art or science; teacher of highest rank'"; the Latin term came from the "...agent noun from profiteri 'lay claim to, declare openly'". As a title that is "prefixed to a name, it dates from 1706". The "short form prof is recorded from 1838". The term professor is also used with a different meaning: "one professing religion. This canting use of the word comes down from the Elizabethan period, but is obsolete in England."
Description
A professor is an accomplished and recognized academic. In most Commonwealth nations, as well as northern Europe, the title professor is the highest academic rank at a university. In the United States and Canada, the title of professor applies to most post-doctoral academics, so a larger percentage are thus designated. In these areas, professors are scholars with doctorate degrees (typically PhD degrees) or equivalent qualifications who teach in colleges and universities. An emeritus professor is a title given to selected retired professors with whom the university wishes to continue to be associated due to their stature and ongoing research. Emeritus professors do not receive a salary, but they are often given office or lab space, and use of libraries, labs, and so on.
The term professor is also used in the titles assistant professor and associate professor, which are not considered professor-level positions in all European countries. In Australia, the title associate professor is used in place of the term reader as used in the United Kingdom and other Commonwealth countries; ranking above senior lecturer and below full professor.
Beyond holding the proper academic title, universities in many countries also give notable artists, athletes and foreign dignitaries the title honorary professor, even if these persons do not have the academic qualifications typically necessary for professorship and they do not take up professorial duties. However, such "professors" usually do not undertake academic work for the granting institution. In general, the title of professor is strictly used for academic positions rather than for those holding it on honorary basis.
Tasks
Professors are qualified experts in their field who generally perform some or all the following tasks:
* Managing teaching, research, and publications in their departments (in countries where a professor is head of a department);
* Presenting lectures and seminars in their specialties (i.e., they "profess");
* Performing, leading and publishing advanced original research in peer reviewed journals in their fields;
* Providing community service, including consulting functions (such as advising government and nonprofit organizations) or providing expert commentary on TV or radio news or public affairs programs;
* Mentoring graduate students in their academic training;
* Mentoring more junior academic staff;
* Conducting administrative or managerial functions, usually at a high level (e.g. deans, heads of departments, research centers, etc.); and
* Assessing students in their fields of expertise (e.g., through grading examinations or viva voce defenses).
Other roles of professorial tasks depend on the institution, its legacy, protocols, place (country), and time. For example, professors at research-oriented universities in North America and, generally, at European universities, are promoted primarily on the basis of research achievements and external grant-raising success.
Around the world
Many colleges and universities and other institutions of higher learning throughout the world follow a similar hierarchical ranking structure amongst scholars in academia; the list above provides details.
A professor typically earns a base salary and a range of employee benefits. In addition, a professor who undertakes additional roles in their institution (e.g., department chair, dean, head of graduate studies, etc.) sometimes earns additional income. Some professors also earn additional income by moonlighting in other jobs, such as consulting, publishing academic or popular press books, giving speeches, or coaching executives. Some fields (e.g., business and computer science) give professors more opportunities for outside work.
Germany and Switzerland
A report from 2005 by the "Deutscher Hochschulverband DHV", a lobby group for German professors, the salary of professors, the annual salary of a German professor is €46,680 in group "W2" (mid-level) and €56,683 in group "W3" (the highest level), without performance-related bonuses. The anticipated average earnings with performance-related bonuses for a German professor is €71,500. The anticipated average earnings of a professor working in Switzerland vary for example between 158,953 CHF (€102,729) to 232,073 CHF (€149,985) at the University of Zurich and 187,937 CHF (€121,461) to 247,280 CHF (€159,774) at the ETH Zurich; the regulations are different depending on the Cantons of Switzerland.
Italy
As late as 2021, in the Italian universities there are about 18 thousand Assistant Professors, 23 thousand Associate Professors, and 14 thousand Full Professors. The role of "professore a contratto" (the equivalent of an "adjunct professor"), a non-tenured position which does not require a PhD nor any habilitation, is paid at the end of the academic year nearly €3000 for the entire academic year, without salary during the academic year. There are about 28 thousand "Professori a contratto" in Italy, . Associate Professors have a gross salary in between 52.937,59 and 96.186,12 euros per year, Full Professors have a gross salary in between 75.431,76 and 131.674 Euros per year, and adjunct professors of around 3,000 euros per year.
Saudi Arabia
According to The World Salaries , the salary of a professor in any public university is 447,300 SAR, or 119 217.18 USD
Spain
The salaries of civil servant professors in Spain are fixed on a nationwide basis, but there are some bonuses related to performance and seniority and a number of bonuses granted by the Autonomous Regional governments. These bonuses include three-year premiums (Spanish: trienios, according to seniority), five-year premiums (quinquenios, according to compliance with teaching criteria set by the university) and six-year premiums (sexenios, according to compliance with research criteria laid down by the national government). These salary bonuses are relatively small. Nevertheless, the total number of sexenios is a prerequisite for being a member of different committees.
The importance of these sexenios as a prestige factor in the university was enhanced by legislation in 2001 (LOU). Some indicative numbers can be interesting, in spite of the variance in the data. We report net monthly payments (after taxes and social security fees), without bonuses: Ayudante, €1,200; Ayudante Doctor, €1,400; Contratado Doctor; €1,800; Profesor Titular, €2,000; Catedrático, €2,400. There are a total of 14 payments per year, including 2 extra payments in July and December (but for less than a normal monthly payment).
United States
Professors in the United States commonly occupy any of several positions in academia. In the U.S., the word "professor" informally refers collectively to the academic ranks of assistant professor, associate professor, or professor. This usage differs from the predominant usage of the word "professor" internationally, where the unqualified word "professor" only refers to full professors. The majority of university lecturers and instructors in the United States, as of 2015, do not occupy these tenure-track ranks, but are part-time adjuncts.
Research professor
In a number of countries, the title "research professor" refers to a professor who is exclusively or mainly engaged in research, and who has few or no teaching obligations. For example, the title is used in this sense in the United Kingdom (where it is known as a research professor at some universities and professorial research fellow at some other institutions) and in northern Europe. A research professor is usually the most senior rank of a research-focused career pathway in those countries and is regarded as equal to the ordinary full professor rank. Most often they are permanent employees, and the position is often held by particularly distinguished scholars; thus the position is often seen as more prestigious than an ordinary full professorship. The title is used in a somewhat similar sense in the United States, with the exception that research professors in the United States are often not permanent employees and often must fund their salary from external sources, which is usually not the case elsewhere.
In fiction
Traditional fictional portrayals of professors, in accordance with a stereotype, are shy, absent-minded individuals often lost in thought. In many cases, fictional professors are socially or physically awkward. Examples include the 1961 film The Absent-Minded Professor or Professor Calculus of The Adventures of Tintin stories. Professors have also been portrayed as being misguided into an evil pathway, such as Professor Metz, who helped Bond villain Blofeld in the film Diamonds Are Forever; or simply evil, like Professor Moriarty, archenemy of British detective Sherlock Holmes. The modern animated series Futurama has Professor Hubert Farnsworth, a typical absent-minded but genius-level professor. A related stereotype is the mad scientist.
Vladimir Nabokov, author and professor of English at Cornell, frequently used professors as the protagonists in his novels. Professor Henry Higgins is a main character in George Bernard Shaw's play Pygmalion. In the Harry Potter series, set at the wizard school Hogwarts, the teachers are known as professors, many of whom play important roles, notably Professors Dumbledore, McGonagall and Snape. In the board game Cluedo, Professor Plum has been depicted as an absent-minded academic. Christopher Lloyd played Plum's film counterpart, a psychologist who had an affair with one of his patients.
Since the 1980s and 1990s, various stereotypes were re-evaluated, including professors. Writers began to depict professors as just normal human beings and might be quite well-rounded in abilities, excelling both in intelligence and in physical skills. An example of a fictional professor not depicted as shy or absent-minded is Indiana Jones, a professor as well as an archeologist-adventurer, who is skilled at both scholarship and fighting. The popularity of the Indiana Jones movie franchise had a significant impact on the previous stereotype, and created a new archetype which is both deeply knowledgeable and physically capable. The character generally referred to simply as the Professor on the television sitcom series, Gilligan's Island, although described alternatively as a high-school science teacher or research scientist, is depicted as a sensible advisor, a clever inventor, and a helpful friend to his fellow castaways. John Houseman's portrayal of law school professor Charles W. Kingsfield, Jr., in The Paper Chase (1973) remains the epitome of the strict, authoritarian professor who demands perfection from students. Annalise Keating (played by Viola Davis) from the American Broadcasting Company (ABC) legal drama mystery television series How to Get Away with Murder is a law professor at the fictional Middleton University. Early in the series, Annalise is a self-sufficient and confident woman, respected for being a great law professor and a great lawyer, feared and admired by her students, whose image breaks down as the series progresses. Sandra Oh stars as an English professor, Ji-Yoon Kim, recently promoted to the role of department chair in the 2021 Netflix series The Chair. The series includes her character's negotiation of liberal arts campus politics, in particular issues of racism, and social mores.
Mysterious, older men with magical powers (and unclear academic standing) are sometimes given the title of "Professor" in literature and theater. Notable examples include Professor X in the X-Men franchise, Professor Marvel in The Wizard of Oz and Professor Drosselmeyer (as he is sometimes known) from the ballet The Nutcracker. Also, the magician played by Christian Bale in the film The Prestige adopts 'The Professor' as his stage name. A variation of this type of non-academic professor is the "crackpot inventor", as portrayed by Professor Potts in the film version of Chitty Chitty Bang Bang or the Jerry Lewis-inspired Professor Frink character on The Simpsons. Other professors of this type are the thoughtful and kind Professor Digory Kirke of C. S. Lewis's Chronicles of Narnia.
Non-academic usage
The title has been used by comedians, such as "Professor" Irwin Corey and Soupy Sales in his role as "The Big Professor". In the past, pianists in saloons and other rough environments have been called "professor". The puppeteer of a Punch and Judy show is also traditionally known as "Professor". Aside from such examples in the performing arts, one apparently novel example is known where the title of professor has latterly been applied to a college appointee with an explicitly "non-academic role", which seems to be primarily linked to claims of "strategic importance".
Additional Information
Bruce Macfarlane, the author of Intellectual Leadership in Higher Education, describes ‘professor’ as ‘a slippery term’. That’s because in the UK it means something quite different from what it denotes in North America. In North America ‘professor’ and ‘professorship’ are generic labels applied to all academics employed to research and teach in universities. In the UK, much of Europe (and, for the most part, in Australasia and South Africa), ‘professorship’ denotes distinction: a professor is someone who has been promoted to the highest academic grade – usually on the basis of her or his scholarly achievements. It’s the equivalent to what, in North America, is known as full professorship.
Some people are unclear about how someone known as ‘Dr’ is different from someone whose title is ‘Professor’. ‘Dr’ denotes someone who has studied for, and been awarded, a PhD, so it denotes an academic qualification: the holder of the highest university degree. It’s the equivalent of writing ‘PhD’ after someone’s name. Most professors will be PhD-holders, but so will be many – if not most – other academics employed as university teachers and researchers. ‘Professor’ doesn’t denote a qualification but an academic staff grade – the most senior one. So, in the UK, an academic whose title is ‘Dr’ is someone who’s got a PhD, but hasn’t been promoted to the highest academic grade, while an academic whose title is ‘Professor’ is someone who probably (but not necessarily) has a PhD, but who has been promoted to the highest grade on the university pay scale. Professorship therefore denotes seniority and status. If we make a comparison with medical doctors working in a hospital, all will have medical degrees, but they are employed at different levels of seniority, with consultants being the most senior doctors. We may think of professors as the equivalent of hospital consultants.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2258 2024-08-16 22:10:21
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2260) Pulse Oximetry
Gist
Pulse oximetry is a test used to measure the oxygen level (oxygen saturation) of the blood. It's an easy, painless measure of how well oxygen is being sent to parts of your body furthest from your heart, such as the arms and legs. A clip-like device called a probe is placed on a body part, such as a finger or ear lobe.
Summary:
What is pulse oximetry?
Pulse oximetry is a test used to measure the oxygen level (oxygen saturation) of the blood. It's an easy, painless measure of how well oxygen is being sent to parts of your body furthest from your heart, such as the arms and legs.
A clip-like device called a probe is placed on a body part, such as a finger or ear lobe. The probe uses light to measure how much oxygen is in the blood. This information helps the healthcare provider decide if a person needs extra oxygen.
Why might I need pulse oximetry?
Pulse oximetry may be used to see if there is enough oxygen in the blood. This information is needed in many kinds of situations. It may be used:
* As part of a routine wellness check
* During or after surgery or procedures that use sedation
* To see how well lung medicines are working
* To check a person’s ability to handle increased activity levels
* To see if a ventilator is needed to help with breathing, or to see how well it’s working
* To check a person who has moments when breathing stops during sleep (sleep apnea)
Pulse oximetry is also used to check the health of a person with any condition that affects blood oxygen levels, such as:
* Heart attack
* Heart failure
* Chronic obstructive pulmonary disease (COPD)
* Anemia
* Lung cancer
* Asthma
* Pneumonia
Your healthcare provider may have other reasons to advise pulse oximetry.
Details
Pulse oximetry is a noninvasive method for monitoring blood oxygen saturation. Peripheral oxygen saturation (SpO2) readings are typically within 2% accuracy (within 4% accuracy in 95% of cases) of the more accurate (and invasive) reading of arterial oxygen saturation (SaO2) from arterial blood gas analysis.
A standard pulse oximeter passes two wavelengths of light through tissue to a photodetector. Taking advantage of the pulsate flow of arterial blood, it measures the change in absorbance over the course of a cardiac cycle, allowing it to determine the absorbance due to arterial blood alone, excluding unchanging absorbance due to venous blood, skin, bone, muscle, fat, and, in many cases, nail polish. The two wavelengths measure the quantities of bound (oxygenated) and unbound (non-oxygenated) hemoglobin, and from their ratio, the percentage of bound hemoglobin is computed. The most common approach is transmissive pulse oximetry. In this approach, one side of a thin part of the patient's body, usually a fingertip or earlobe, is illuminated, and the photodetector is on the other side. Fingertips and earlobes have disproportionately high blood flow relative to their size, in order to keep warm, but this will be lacking in hypothermic patients. Other convenient sites include an infant's foot or an unconscious patient's cheek or tongue.
Reflectance pulse oximetry is a less common alternative, placing the photodetector on the same surface as the illumination. This method does not require a thin section of the person's body and therefore may be used almost anywhere on the body, such as the forehead, chest, or feet, but it still has some limitations. Vasodilation and pooling of venous blood in the head due to compromised venous return to the heart can cause a combination of arterial and venous pulsations in the forehead region and lead to spurious SpO2 results. Such conditions occur while undergoing anaesthesia with endotracheal intubation and mechanical ventilation or in patients in the Trendelenburg position.
Medical uses
A pulse oximeter is a medical device that indirectly monitors the oxygen saturation of a patient's blood (as opposed to measuring oxygen saturation directly through a blood sample) and changes in blood volume in the skin, producing a photoplethysmogram that may be further processed into other measurements. The pulse oximeter may be incorporated into a multiparameter patient monitor. Most monitors also display the pulse rate. Portable, battery-operated pulse oximeters are also available for transport or home blood-oxygen monitoring.
Advantages
Pulse oximetry is particularly convenient for noninvasive continuous measurement of blood oxygen saturation. In contrast, blood gas levels must otherwise be determined in a laboratory on a drawn blood sample. Pulse oximetry is useful in any setting where a patient's oxygenation is unstable, including intensive care, operating, recovery, emergency and hospital ward settings, pilots in unpressurized aircraft, for assessment of any patient's oxygenation, and determining the effectiveness of or need for supplemental oxygen. Although a pulse oximeter is used to monitor oxygenation, it cannot determine the metabolism of oxygen, or the amount of oxygen being used by a patient. For this purpose, it is necessary to also measure carbon dioxide (CO2) levels. It is possible that it can also be used to detect abnormalities in ventilation. However, the use of a pulse oximeter to detect hypoventilation is impaired with the use of supplemental oxygen, as it is only when patients breathe room air that abnormalities in respiratory function can be detected reliably with its use. Therefore, the routine administration of supplemental oxygen may be unwarranted if the patient is able to maintain adequate oxygenation in room air, since it can result in hypoventilation going undetected.
Because of their simplicity of use and the ability to provide continuous and immediate oxygen saturation values, pulse oximeters are of critical importance in emergency medicine and are also very useful for patients with respiratory or cardiac problems, especially COPD, or for diagnosis of some sleep disorders such as apnea and hypopnea. For patients with obstructive sleep apnea, pulse oximetry readings will be in the 70–90% range for much of the time spent attempting to sleep.
Portable battery-operated pulse oximeters are useful for pilots operating in non-pressurized aircraft above 10,000 feet (3,000 m) or 12,500 feet (3,800 m) in the U.S. where supplemental oxygen is required. Portable pulse oximeters are also useful for mountain climbers and athletes whose oxygen levels may decrease at high altitudes or with exercise. Some portable pulse oximeters employ software that charts a patient's blood oxygen and pulse, serving as a reminder to check blood oxygen levels.
Connectivity advancements have made it possible for patients to have their blood oxygen saturation continuously monitored without a cabled connection to a hospital monitor, without sacrificing the flow of patient data back to bedside monitors and centralized patient surveillance systems.
For patients with COVID-19, pulse oximetry helps with early detection of silent hypoxia, in which the patients still look and feel comfortable, but their SpO2 is dangerously low. This happens to patients either in the hospital or at home. Low SpO2 may indicate severe COVID-19-related pneumonia, requiring a ventilator.
Safety
Continuous monitoring with pulse oximetry is generally considered safe for most patients for up to 8 hours. However, prolonged use in certain types of patients can cause burns due to the heat emitted by the infrared LED, which reaches up to 43°C. Additionally, pulse oximeters occasionally develop electrical faults which causes them to heat up above this temperature. Patients at greater risk include those with delicate or fragile skin, such as infants, particularly premature infants, and the elderly. Additional risks for injury include lack of pain response where the probe is placed, such as having an insensate limb, or being unconscious or under anesthesia, or having communication difficulties. Patients who are at high risk for injury should be have the site of their probe moved frequently, i.e. every hour, whereas patients who are at lower risk should have theirs moved every 2-4 hours.
Limitations:
Fundamental limitations
Pulse oximetry solely measures hemoglobin saturation, not ventilation and is not a complete measure of respiratory sufficiency. It is not a substitute for blood gases checked in a laboratory, because it gives no indication of base deficit, carbon dioxide levels, blood pH, or bicarbonate (HCO3−) concentration. The metabolism of oxygen can be readily measured by monitoring expired CO2, but saturation figures give no information about blood oxygen content. Most of the oxygen in the blood is carried by hemoglobin; in severe anemia, the blood contains less hemoglobin, which despite being saturated cannot carry as much oxygen.
Pulse oximetry also is not a complete measure of circulatory oxygen sufficiency. If there is insufficient bloodflow or insufficient hemoglobin in the blood (anemia), tissues can suffer hypoxia despite high arterial oxygen saturation.
Since pulse oximetry measures only the percentage of bound hemoglobin, a falsely high or falsely low reading will occur when hemoglobin binds to something other than oxygen:
* Hemoglobin has a higher affinity to carbon monoxide than it does to oxygen. Therefore, in cases of carbon monoxide poisoning, most hemoglobin might be bound not to oxygen but to carbon monoxide. A pulse oximeter would correctly report most hemoglobin to be bound, but nevertheless the patient would be in a state of hypoxemia and subsequently hypoxia (low cellular oxygen level).
* Cyanide poisoning gives a high reading because it reduces oxygen extraction from arterial blood. In this case, the reading is not false, as arterial blood oxygen is indeed high early in cyanide poisoning: the patient is not hypoxemic, but is hypoxic.
* Methemoglobinemia characteristically causes pulse oximetry readings in the mid-80s.
* COPD [especially chronic bronchitis] may cause false readings.
A noninvasive method that allows continuous measurement of the dyshemoglobins is the pulse CO-oximeter, which was built in 2005 by Masimo. By using additional wavelengths, it provides clinicians a way to measure the dyshemoglobins, carboxyhemoglobin, and methemoglobin along with total hemoglobin.
Conditions affecting accuracy
Because pulse oximeter devices are calibrated for healthy subjects, their accuracy is poor for critically ill patients and preterm newborns. Erroneously low readings may be caused by hypoperfusion of the extremity being used for monitoring (often due to a limb being cold or from vasoconstriction secondary to the use of vasopressor agents); incorrect sensor application; highly calloused skin; or movement (such as shivering), especially during hypoperfusion. To ensure accuracy, the sensor should return a steady pulse and/or pulse waveform. Pulse oximetry technologies differ in their abilities to provide accurate data during conditions of motion and low perfusion. Obesity, hypotension (low blood pressure), and some hemoglobin variants can reduce the accuracy of the results. Some home pulse oximeters have low sampling rates, which can significantly underestimate dips in blood oxygen levels. The accuracy of pulse oximetry deteriorates considerably for readings below 80%. Research has suggested that error rates in common pulse oximeter devices may be higher for adults with dark skin color, leading to claims of encoding systemic racism in countries with multi-racial populations such as the United States. The issue was first identified decades ago; one of the earliest studies on this topic occurred in 1976, which reported reading errors in dark-skinned patients that reflected lower blood oxygen saturation values. Further studies indicate that while accuracy with dark skin is good at higher, healthy saturation levels, some devices overestimate the saturation at lower levels, which may lead to hypoxia not being detected. A study that reviewed thousands of cases of occult hypoxemia, where patients were found to have oxygen saturation below 88% per arterial blood gas measurement despite pulse oximeter readings indicating 92% to 96% oxygen saturation, found that black patients were three times as likely as white patients to have their low oxygen saturation missed by pulse oximeters. Another research study investigated patients in the hospital with COVID-19 and found that occult hypoxemia occurred in 28.5% of black patients compared to only 17.2% of white patients. There has been research to indicate that black COVID-19 patients were 29% less likely to receive supplemental oxygen in a timely manner and three times more likely to have hypoxemia.[26] A further study, which used a MIMIC-IV critical care dataset of both pulse oximeter readings and oxygen saturation levels detected in blood samples, demonstrated that black, Hispanic, and Asian patients had higher SpO2 readings than white patients for a given blood oxygen saturation level measured in blood samples. As a result, black, Hispanic, and Asian patients also received lower rates of supplemental oxygen than white patients. It is suggested that melanin can interfere with the absorption of light used to measure the level of oxygenated blood, often measured from a person's finger. Further studies and computer simulations show that the increased amounts of melanin found in people with darker skin scatter the photons of light used by the pulse oximeters, decreasing the accuracy of the measurements. As the studies used to calibrate the devices typically oversample people with lighter skin, the parameters for pulse oximeters are set based on information that is not equitably balanced to account for diverse skin colors. This inaccuracy can lead to potentially missing people who need treatment, as pulse oximetry is used for the screening of sleep apnea and other types of sleep-disordered breathing, which in the United States are conditions more prevalent among minorities. This bias is a significant concern, as a 2% decrease is important for respiratory rehabilitation, studies of sleep apnea, and athletes performing physical efforts; it can lead to severe complications for the patient, requiring an external oxygen supply or even hospitalization. Another concern regarding pulse oximetry bias is that insurance companies and hospital systems increasingly use these numbers to inform their decisions. Pulse oximetry measurements are used to identify candidates for reimbursement. Similarly, pulse oximetry data is being incorporated into algorithms for clinicians. Early Warning Scores, which provide a record for analyzing a patient's clinical status and alerting clinicians if needed, incorporate algorithms with pulse oximetry information and can result in misinformed patient records.
Equipment:
Consumer pulse oximeters
In addition to pulse oximeters for professional use, many inexpensive "consumer" models are available. Opinions vary about the reliability of consumer oximeters; a typical comment is "The research data on home monitors has been mixed, but they tend to be accurate within a few percentage points". Some smart watches with activity tracking incorporate an oximeter function. An article on such devices, in the context of diagnosing COVID-19 infection, quoted João Paulo Cunha of the University of Porto, Portugal: "these sensors are not precise, that's the main limitation ... the ones that you wear are only for the consumer level, not for the clinical level". Pulse oximeters used for diagnosis of conditions such as COVID-19 should be Class IIB medical grade oximeters. Class IIB oximeters can be used on patients of all skin colors, low pigmentation and in the presence of motion.[citation needed] When a pulse oximeter is shared between two patients, to prevent cross-infection it should be cleaned with alcohol wipes after each use or a disposable probe or finger cover should be used.
According to a report by iData Research, the US pulse oximetry monitoring market for equipment and sensors was over $700 million in 2011.
Mobile apps
Mobile app pulse oximeters use the flashlight and the camera of the phone, instead of infrared light used in conventional pulse oximeters. However, apps do not generate as accurate readings because the camera cannot measure the light reflection at two wavelengths, so the oxygen saturation readings that are obtained through an app on a smartphone are inconsistent for clinical use. At least one study has suggested these are not reliable relative to clinical pulse oximeters.
Additional Information
A pulse oximeter measures your blood oxygen levels and pulse. A low level of oxygen saturation may occur if you have certain health conditions. Your skin tone may also affect your reading.
Pulse oximetry is a noninvasive test that measures the oxygen saturation level of your blood.
It can rapidly detect even small changes in oxygen levels. These levels show how efficiently blood is carrying oxygen to the extremities furthest from your heart, including your arms and legs.
The pulse oximeter is a small, clip-like device. It attaches to a body part, most commonly to a finger.
Medical professionals often use them in critical care settings like emergency rooms or hospitals. Some doctors, such as pulmonologists, may use them in office settings. You can even use one at home.
Purpose and uses
The purpose of pulse oximetry is to see if your blood is well oxygenated.
Medical professionals may use pulse oximeters to monitor the health of people with conditions that affect blood oxygen levels, especially while they’re in the hospital.
These can include:
* chronic obstructive pulmonary disease (COPD)
* asthma
* pneumonia
* lung cancer
* anemia
* heart attack or heart failure
* congenital heart disease
Doctors use pulse oximetry for a number of different reasons, including:
* to assess how well a new lung medication is working
* to evaluate whether someone needs help breathing
* to evaluate how helpful a ventilator is
* to monitor oxygen levels during or after surgical procedures that require sedation
* to determine whether someone needs supplemental oxygen therapy
* to determine how effective supplemental oxygen therapy is, especially when treatment is new
* to assess someone’s ability to tolerate increased physical activity
* to evaluate whether someone momentarily stops breathing while sleeping — like in cases of sleep apnea — during a sleep study.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2259 2024-08-17 16:56:49
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2261) Pollination
Gist
Pollination is the act of transferring pollen grains from the male anther of a flower to the female stigma. The goal of every living organism, including plants, is to create offspring for the next generation. One of the ways that plants can produce offspring is by making seeds.
Summary
Pollination is the transfer of pollen from an anther of a plant to the stigma of a plant, later enabling fertilisation and the production of seeds. Pollinating agents can be animals such as insects, for example beetles or butterflies; birds, and bats; water; wind; and even plants themselves. Pollinating animals travel from plant to plant carrying pollen on their bodies in a vital interaction that allows the transfer of genetic material critical to the reproductive system of most flowering plants. When self-pollination occurs within a closed flower. Pollination often occurs within a species. When pollination occurs between species, it can produce hybrid offspring in nature and in plant breeding work.
In angiosperms, after the pollen grain (gametophyte) has landed on the stigma, it germinates and develops a pollen tube which grows down the style until it reaches an ovary. Its two gametes travel down the tube to where the gametophyte(s) containing the female gametes are held within the carpel. After entering an ovule through the micropyle, one male nucleus fuses with the polar bodies to produce the endosperm tissues, while the other fuses with the egg cell to produce the embryo. Hence the term: "double fertilisation". This process would result in the production of a seed, made of both nutritious tissues and embryo.
In gymnosperms, the ovule is not contained in a carpel, but exposed on the surface of a dedicated support organ, such as the scale of a cone, so that the penetration of carpel tissue is unnecessary. Details of the process vary according to the division of gymnosperms in question. Two main modes of fertilisation are found in gymnosperms: cycads and Ginkgo have motile sperm that swim directly to the egg inside the ovule, whereas conifers and gnetophytes have sperm that are unable to swim but are conveyed to the egg along a pollen tube.
The study of pollination spans many disciplines, such as botany, horticulture, entomology, and ecology. The pollination process as an interaction between flower and pollen vector was first addressed in the 18th century by Christian Konrad Sprengel. It is important in horticulture and agriculture, because fruiting is dependent on fertilisation: the result of pollination. The study of pollination by insects is known as anthecology. There are also studies in economics that look at the positives and negatives of pollination, focused on bees, and how the process affects the pollinators themselves.
Process of pollination
Pollen germination has three stages; hydration, activation and pollen tube emergence. The pollen grain is severely dehydrated so that its mass is reduced, enabling it to be more easily transported from flower to flower. Germination only takes place after rehydration, ensuring that premature germination does not take place in the anther. Hydration allows the plasma membrane of the pollen grain to reform into its normal bilayer organization providing an effective osmotic membrane. Activation involves the development of actin filaments throughout the cytoplasm of the cell, which eventually become concentrated at the point from which the pollen tube will emerge. Hydration and activation continue as the pollen tube begins to grow. In conifers, the reproductive structures are borne on cones. The cones are either pollen cones (male) or ovulate cones (female), but some species are monoecious and others dioecious. A pollen cone contains hundreds of microsporangia carried on (or borne on) reproductive structures called sporophylls. Spore mother cells in the microsporangia divide by meiosis to form haploid microspores that develop further by two mitotic divisions into immature male gametophytes (pollen grains). The four resulting cells consist of a large tube cell that forms the pollen tube, a generative cell that will produce two sperm by mitosis, and two prothallial cells that degenerate. These cells comprise a very reduced microgametophyte, that is contained within the resistant.
The pollen grains are dispersed by the wind to the female, ovulate cone that is made up of many overlapping scales (sporophylls, and thus megasporophylls), each protecting two ovules, each of which consists of a megasporangium (the nucellus) wrapped in two layers of tissue, the integument and the cupule, that were derived from highly modified branches of ancestral gymnosperms. When a pollen grain lands close enough to the tip of an ovule, it is drawn in through the micropyle ( a pore in the integuments covering the tip of the ovule) often by means of a drop of liquid known as a pollination drop. The pollen enters a pollen chamber close to the nucellus, and there it may wait for a year before it germinates and forms a pollen tube that grows through the wall of the megasporangium (=nucellus) where fertilisation takes place. During this time, the megaspore mother cell divides by meiosis to form four haploid cells, three of which degenerate. The surviving one develops as a megaspore and divides repeatedly to form an immature female gametophyte (egg sac). Two or three archegonia containing an egg then develop inside the gametophyte. Meanwhile, in the spring of the second year two sperm cells are produced by mitosis of the body cell of the male gametophyte. The pollen tube elongates and pierces and grows through the megasporangium wall and delivers the sperm cells to the female gametophyte inside. Fertilisation takes place when the nucleus of one of the sperm cells enters the egg cell in the megagametophyte's archegonium.
In flowering plants, the anthers of the flower produce microspores by meiosis. These undergo mitosis to form male gametophytes, each of which contains two haploid cells. Meanwhile, the ovules produce megaspores by meiosis, further division of these form the female gametophytes, which are very strongly reduced, each consisting only of a few cells, one of which is the egg. When a pollen grain adheres to the stigma of a carpel it germinates, developing a pollen tube that grows through the tissues of the style, entering the ovule through the micropyle. When the tube reaches the egg sac, two sperm cells pass through it into the female gametophyte and fertilisation takes place.
Details
Pollination is transfer of pollen grains from the stamens (the flower parts that produce them) to the ovule-bearing organs or to the ovules (seed precursors) themselves. In gymnosperm plants such as conifers and cycads, in which the ovules are exposed, the pollen is simply caught in a drop of fluid secreted by the ovule. In flowering plants, however, the ovules are contained within a hollow organ called the pistil, and the pollen is deposited on the pistil’s receptive surface, the stigma. There the pollen germinates and gives rise to a pollen tube, which grows down through the pistil toward one of the ovules in its base. In an act of double fertilization, one of the two sperm cells within the pollen tube fuses with the egg cell of the ovule, making possible the development of an embryo, and the other cell combines with the two subsidiary sexual nuclei of the ovule, which initiates formation of a reserve food tissue, the endosperm. The growing ovule then transforms itself into a seed.
As a prerequisite for fertilization, pollination is essential to the perpetuation of the vast majority of the world’s wild plants as well as to the production of most fruit and seed crops. It also plays an important part in programs designed to improve plants by breeding. Furthermore, studies of pollination are invaluable for understanding the evolution of flowering plants and their distribution in the world today. As sedentary organisms, plants usually must enlist the services of external agents for pollen transport. In flowering plants, these are (roughly in order of diminishing importance) insects, wind, birds, mammals, and water.
Types: self-pollination and cross-pollination:
Cross-pollination
An egg cell in an ovule of a flower may be fertilized by a sperm cell derived from a pollen grain produced by that same flower or by another flower on the same plant, in either of which two cases fertilization is said to be due to self-pollination (autogamy); or, the sperm may be derived from pollen originating on a different plant individual, in which case the process is called cross-pollination (heterogamy). Both processes are common, but cross-pollination clearly has certain evolutionary advantages for the species: the seeds formed may combine the hereditary traits of both parents, and the resulting offspring generally are more varied than would be the case after self-pollination. In a changing environment, some of the individuals resulting from cross-pollination still may be found capable of coping with their new situation, ensuring survival of the species, whereas the individuals resulting from self-pollination might all be unable to adjust. Self-pollination, or selfing, although foolproof in a stable environment, thus is an evolutionary cul-de-sac. There also is a more direct, visible difference between selfing and outbreeding (cross-pollination): in those species where both methods work, cross-pollination usually produces more, and better quality, seeds. A dramatic demonstration of this effect is found with hybrid corn (maize), a superior product that results from cross-breeding of several especially bred lines.
Mechanisms that prevent self-pollination:
Structural
Not surprisingly, many species of plants have developed mechanisms that prevent self-pollination. Some—e.g., date palms (Phoenix dactylifera) and willows (Salix species)—have become dioecious; that is, some plants produce only “male” (staminate) flowers, with the rest producing only “female” (pistillate or ovule-producing) ones. In species in which staminate and pistillate flowers are found on the same individual (monoecious plants) and in those with hermaphroditic flowers (flowers possessing both stamens and pistils), a common way of preventing self-fertilization is to have the pollen shed either before or after the period during which the stigmas on the same plant are receptive, a situation known as dichogamy. The more usual form of dichogamy, which is found especially in such insect-pollinated flowers as fireweed (Epilobium angustifolium) and salvias (Salvia species), is protandry, in which the stamens ripen before the pistils. Protogyny, the situation in which the pistils mature first, occurs in arum lilies and many wind-pollinated plants, such as grasses—although several grasses are self-pollinated, including common varieties of wheat, barley, and oats. Avocado has both protogynous and protandrous varieties, and these often are grown together to encourage cross-fertilization.
A structural feature of flowers that discourages selfing is heterostyly, or variation in the length of the style (neck of the pistil). This occurs in the common primrose (Primula vulgaris) and species of wood sorrel (Oxalis) and flax. In most British primrose populations, for example, approximately half the individuals have so-called “pin” flowers, which possess short stamens and a long style, giving the stigma a position at the flower’s mouth, whereas the other half have “thrum” flowers, in which the style is short and the stamens are long, forming a “thrumhead” at the opening of the flower. Bees can hardly fail to deposit the pollen they receive from one type of flower onto the stigmas of the other type. The genetic system that regulates flower structure in these primroses is so constituted that cross-pollination automatically maintains a 50:50 ratio between pins and thrums. In the flowers of purple loosestrife (Lythrum salicaria), the stamens and styles are of three different lengths to limit self-fertilization.
Chemical
Chemical self-incompatibility is another device for preventing self-fertilization. In this phenomenon, which depends on chemical substances within the plant, the pollen may fail to grow on a stigma of the same flower that produced it or, after germination, the pollen tube may not grow normally down the style to effect fertilization. The process is controlled genetically; it need not be absolute and can change in degree during the flowering season. Not surprisingly, chemical incompatibility usually is not found in those plants that have strong structural or temporal barriers against self-pollination. Formation of one such mechanism during evolution apparently was enough for most plant species.
Mechanisms that permit self-pollination
Self-pollination
In many instances, successful self-pollination takes place at the end of a flower’s life-span if cross-pollination has not occurred. Such self-pollination may be achieved by curving of stamens or style as occurs, for example, in fireweed. It can be an evolutionary advantage when animal pollinators are temporarily scarce or when the plants in a population are widely scattered. Under such circumstances, selfing may tide the species over until better circumstances for outbreeding arrive. For this reason, selfing is common among annual plants; these often must produce an abundance of seed for the rapid and massive colonization of any bare ground that becomes available. If, in a given year, an annual plant were to produce no seed at all, survival of the species might be endangered.
A persistent habit of self-pollination apparently has been adopted successfully by some plant species whose natural pollinators have died out. Continued selfing also is practiced by many food-crop plants. Some of these plants are cleistogamous, meaning that the flowers fail to open, an extreme way of ensuring self-pollination. A similar process is apomixis, the development of an ovule into a seed without fertilization. Apomixis is easily demonstrated in lawn dandelions, which produce seeds even when stamens and styles are cut off just before the flowers open. Consistent apomixis has the same pros and cons as continued selfing. The offspring show very little genetic variability, but there is good survival if the species is well adapted to its habitat and if the environment does not change.
Evolution of insect pollination
Pollination by insects probably occurred in primitive seed plants, reliance on other means being a relatively recent evolutionary development. Reasonable evidence indicates that flowering plants first appeared in tropical rainforests during the Mesozoic Era (about 66 million to 252.2 million years ago). The most prevalent insect forms of the period were primitive beetles; no bees and butterflies were present. Some Mesozoic beetles, already adapted to a diet of spores from primitive plants, apparently became pollen eaters, capable of effecting chance pollination with grains accidentally spared. The visits of such beetles to primitive flowering plants may have been encouraged by insect attractants, such as odors of carrion, dung, or fruit, or by sex attractants. In addition, visits of the insects to the plants could be made to last longer and thus potentially be more valuable to the plant as far as fertilization was concerned, if the flower had a functional, traplike structure. Nowadays, such flowers are found predominantly, although not exclusively, in tropical families regarded as ancient—e.g., the water lily (Nymphaeaceae) and the arum lily (Araceae) families.
At the same time, other plants apparently began to exploit the fact that primitive gall-forming insects visited the flowers to deposit eggs. In the ancient genus Ficus (figs and banyan trees), pollination still depends on gall wasps. In general, Mesozoic flowering plants could not fully rely on their pollinators, whose presence also depended on the existence of a complete, well-functioning ecological web with dung, cadavers, and food plants always available.
More advanced flowers escaped from such dependence on chance by no longer relying on deceit, trapping, and tasty pollen alone; nectar became increasingly important as a reward for the pollinators. Essentially a concentrated, aqueous sugar solution, nectar existed in certain ancestors of the flowering plants. In bracken fern even nowadays, nectar glands (nectaries) are found at the base of young leaves. In the course of evolutionary change, certain nectaries were incorporated into the modern flower (floral nectaries), although extrafloral nectaries also persist. Flower colors thus seem to have been introduced as “advertisements” of the presence of nectar, and more specific nectar guides (such as patterns of dots or lines, contrasting color patches, or special odor patterns) were introduced near the entrance to the flower, pointing the way to the nectar hidden within. At the same time, in a complex pattern of parallel evolution, groups of insects appeared with sucking mouthparts capable of feeding on nectar. In extreme cases, there arose a complete mutual dependence. For example, a Madagascar orchid, Angraecum sesquipedale, with a nectar receptacle 20 to 35 cm (8 to 14 inches) long, depends for its pollination exclusively on the local race of a hawk moth, Xanthopan morganii, which has a proboscis of 22.5 cm (9 inches). Interestingly enough, the existence of the hawk moth was predicted by Charles Darwin and Alfred Russel Wallace, codiscoverers of evolution, about 40 years before its actual discovery.
Agents of pollen dispersal:
Insects
The ancient principle of trapping insects as a means of ensuring pollination was readopted by some advanced families (e.g., orchids and milkweeds), and further elaboration perfected the flower traps of primitive families. The cuckoopint (Arum maculatum), for example, attracts minute flies, which normally breed in cow dung, by means of a fetid smell. This smell is generated in early evening, along with considerable heat, which helps to volatilize the odor ingredients. The flies visiting the plant, many of which carry Arum pollen, enter the floral trap through a zone of bristles and then fall into a smooth-walled floral chamber from which escape is impossible. Gorging themselves on a nutritious stigmatic secretion produced by the female flowers at the base of the chamber, the flies effect cross-pollination. Late at night, when the stigmas no longer function, the male flowers, situated much higher on the floral column, proceed to bombard the flies with a rain of pollen. The next day, when smell, heat, and food are gone, the prisoners, “tarred” with stigmatic secretion and “feathered” with pollen, are allowed to escape by a wilting of the inflorescence (flower cluster). Usually the escaped flies are soon recaught by another inflorescence, which is still in the smelly, receptive stage, and cross-pollination again ensues. Superb timing mechanisms underlie these events. The heat-generating metabolic process in the inflorescence is triggered by a hormone, calorigen, originating in the male flower buds only under the right conditions. The giant inflorescences of the tropical titan arum plant Amorphophallus titanum similarly trap large carrion beetles.
In general, trap flowers victimize beetles or flies of a primitive type. Although beetles most likely were involved as pollinators when flowering plants as a group were born, their later performance in pollination has been disappointing. Some modern beetles do visit smelly flowers of an open type, such as elderberry and hawthorn, but with few exceptions they are still mainly pollen eaters. Flies as a group have become much more diversified in their habits than beetles have. Female short-tongued flies may be deceived by open-type flowers with carrion smells—e.g., the flowers of Stapelia and Rafflesia. Mosquitoes with their long tongues are effective pollinators of certain orchids (Habenaria species) in North American swamps. In Europe, the bee fly (Bombylius) is an important long-tongued pollinator. Extremely specialized as nectar drinkers are certain South African flies; for example, Moegistorhynchus longirostris, which has a tongue that is 60 to 70 mm (2.3 to 2.7 inches) long.
The voraciousness of flower beetles demonstrates the futility of enticing insect pollinators solely with such an indispensable material as pollen. As a defensive strategy, certain nectar-free flowers that cater to beetles and bees—such as wild roses, peonies, and poppies—produce a superabundance of pollen. Other plants—e.g., Cassia—have two types of stamens, one producing a special sterile pollen used by insects as food, the other yielding normal pollen for fertilizing the ovules. Other flowers contain hairs or food bodies that are attractive to insects.
Bees
In the modern world, bees are probably the most important insect pollinators. Living almost exclusively on nectar as adults, they feed their larvae pollen and nectar; some species also make honey (a modified nectar) for their larvae. To obtain their foods, they possess striking physical and behavioral adaptations, such as tongues as long as 2.5 cm (1 inch), often hairy bodies, and (in honeybees and bumblebees) special pollen baskets.
The Austrian naturalist Karl von Frisch has demonstrated that honeybees, although blind to red light, distinguish at least four different color regions, namely, yellow (including orange and yellow green), blue green, blue (including purple and violet), and ultraviolet. Their sensitivity to ultraviolet enables bees to follow nectar-guide patterns not apparent to the human eye. They are able to taste several different sugars and also can be trained to differentiate between aromatic, sweet, or minty odors but not foul smells. Fragrance may be the decisive factor in establishing the honeybee’s habit of staying with one species of flower as long as it is abundantly available. Also important is that honeybee workers can communicate to one another both the distance and the direction of an abundant food source by means of special dances.
Bee flowers, open in the daytime, attract their insect visitors primarily by bright colors; at close range, special patterns and fragrances come into play. Many bee flowers provide their visitors with a landing platform in the form of a broad lower lip on which the bee sits down before pushing its way into the flower’s interior, which usually contains both stamens and pistils. The hermaphroditism of most bee flowers makes for efficiency, because the flower both delivers and receives a load of pollen during a single visit of the pollinator, and the pollinator never travels from one flower to another without a full load of pollen. Indeed, the floral mechanism of many bee flowers permits only one pollination visit. The pollen grains of most bee flowers are sticky, spiny, or highly sculptured, ensuring their adherence to the bodies of the bees. Since one load of pollen contains enough pollen grains to initiate fertilization of many ovules, most individual bee flowers produce many seeds.
Examples of flowers that depend heavily on bees are larkspur, monkshood, bleeding heart, and Scotch broom. Alkali bees (Nomia) and leaf-cutter bees (Megachile) are both efficient pollinators of alfalfa; unlike honeybees, they are not afraid to trigger the explosive mechanism that liberates a cloud of pollen in alfalfa flowers. Certain Ecuadorian orchids (Oncidium) are pollinated by male bees of the genus Centris; vibrating in the breeze, the beelike flowers are attacked headlong by the strongly territorial males, who mistake them for competitors. Other South American orchids, nectarless but very fragrant, are visited by male bees (Euglossa species) who, for reasons not yet understood, collect from the surface of the flowers an odor substance, which they store in the inflated parts of their hindlegs.
Wasps
Few wasps feed their young pollen or nectar. Yellow jackets, however, occurring occasionally in large numbers and visiting flowers for nectar for their own consumption, may assume local importance as pollinators. These insects prefer brownish-purple flowers with easily accessible nectar, such as those of figwort. The flowers of some Mediterranean and Australian orchids mimic the females of certain wasps (of the families Scoliidae and Ichneumonidae) so successfully that the males of these species attempt copulation and receive the pollen masses on their bodies. In figs, it is not the pollinator’s sexual drive that is harnessed by the plant but the instinct to take care of the young; tiny gall wasps (Blastophaga) use the diminutive flowers (within their fleshy receptacles) as incubators.
Butterflies and moths
Orange-tailed butterfly (Eurema proterpia) on an ash-colored aster (Machaeranthera tephrodes). The upstanding yellow stamens are tipped with pollen, which brushes the body of the butterfly as it approaches the center of the flat-topped aster to feed on the nectar.
The evolution of moths and butterflies (Lepidoptera) was made possible only by the development of the modern flower, which provides their food. Nearly all species of Lepidoptera have a tongue, or proboscis, especially adapted for sucking. The proboscis is coiled at rest and extended in feeding. Hawk moths hover while they feed, whereas butterflies alight on the flower. Significantly, some butterflies can taste sugar solutions with their feet. Although moths, in general, are nocturnal and butterflies are diurnal, a color sense has been demonstrated in representatives of both. Generally, the color sense in Lepidoptera is similar to that of bees, but swallowtails and certain other butterflies also respond to red colors. Typically, color and fragrance cooperate in guiding Lepidoptera to flowers, but in some cases there is a strong emphasis on just one attractant; for example, certain hawk moths can find fragrant honeysuckles hidden from sight.
Biotic interaction
Typical moth flowers—e.g., jimsonweed, stephanotis, and honeysuckle—are light-colored, often long and narrow, without landing platforms. The petals are sometimes fringed; the copious nectar is often in a spur. They are open and overwhelmingly fragrant at night. Butterfly flowers—e.g., those of butterfly bush, milkweed, and verbena—are conspicuously colored, often red, generally smaller than moth flowers, but grouped together in erect, flat-topped inflorescences that provide landing space for the butterflies.
Important pollinating moths are the various species of the genus Plusia, sometimes occurring in enormous numbers, and the hummingbird hawk moth (Macroglossa), which is active in daylight. A small moth, Tegeticula maculata, presents an interesting case. It is totally dependent on yucca flowers, in whose ovules its larvae develop. Before depositing their eggs, the females pollinate the flowers, following an almost unbelievable pattern of specialized behavior, which includes preparing a ball of pollen grains and carrying it to the stigma of the plant they are about to use for egg laying.
Wind
Although prevalent in the primitive cycads and in conifers, such as pine and fir, wind pollination (anemophily) in the flowering plants must be considered as a secondary development. It most likely arose when such plants left the tropical rainforest where they originated and faced a more hostile environment, in which the wind weakened the effectiveness of smell as an insect attractant and the lack of pollinating flies and beetles also made itself felt. Lacking in precision, wind pollination is a wasteful process. For example, one male plant of Mercurialis annua, a common weed, produces 1.25 billion grains of pollen to be dispersed by the wind; a male sorrel plant produces 400 million. Although, in general, the concentration of such pollen becomes very low about one-fourth mile (0.4 km) from its source, nonetheless in windy areas it can cover considerable distances. Pine pollen, for example, which is naturally equipped with air sacs, can travel up to 500 miles (800 km) although the grains may lose their viability in the process. Statistically, this still gives only a slim chance that an individual stigma will be hit by more than one or two pollen grains. Also relevant to the number of pollen grains per stigma is the fact that the dry, glueless, and smooth-surfaced grains are shed singly. Since the number of fertilizing pollen grains is low, the number of ovules in a single flower is low and, as a consequence, so is the number of seeds in each fruit. In hazel, walnut, beech, and oak, for example, there are only two ovules per flower, and, in stinging nettle, elm, birch, sweet gale, and grasses, there is only one.
Wind-pollinated flowers are inconspicuous, being devoid of insect attractants and rewards, such as fragrance, showy petals, and nectar. To facilitate exposure of the flowers to the wind, blooming often takes place before the leaves are out in spring, or the flowers may be placed very high on the plant. Inflorescences, flowers, or the stamens themselves move easily in the breeze, shaking out the pollen, or the pollen containers (anthers) burst open in an explosive fashion when the sun hits them, scattering the pollen widely into the air. The stigmas often are long and divided into arms or lobes, so that a large area is available for catching pollen grains. Moreover, in open areas wind-pollinated plants of one species often grow together in dense populations. The chance of self-pollination, high by the very nature of wind pollination, is minimized by the fact that many species are dioecious or (like hazel) have separate male and female flowers on each plant. Familiar flowering plants relying on wind pollination are grasses, rushes, sedges, cattail, sorrel, lamb’s-quarters, hemp, nettle, plantain, alder, hazel, birch, poplar, and oak. (Tropical oaks, however, may be insect-pollinated.)
Birds
Because the study of mechanisms of pollination began in Europe, where pollinating birds are rare, their importance is often underestimated. In fact, in the tropics and the southern temperate zones, birds are at least as important as pollinators as insects are, perhaps more so. About a third of the 300 families of flowering plants have at least some members with ornithophilous (“bird-loving”) flowers—i.e., flowers attractive to birds. Conversely, about 2,000 species of birds, belonging to 50 or more families, visit flowers more or less regularly to feed on nectar, pollen, and flower-inhabiting insects or spiders. Special adaptations to this way of life, in the form of slender, sometimes curved, beaks and tongues provided with brushes or shaped into tubes, are found in over 1,600 species of eight families: hummingbirds, sunbirds (see The Rodent That Acts Like a Hippo and Other Examples of Convergent Evolution), honeyeaters, brush-tongued parrots, white-eyes, flower-peckers, honeycreepers (or sugarbirds), and Hawaiian honeycreepers such as the iiwi. Generally, the sense of smell in birds is poorly developed and not used in their quest for food; instead, they rely on their powerful vision and their color sense, which resembles that of human (ultraviolet not being seen as a color, whereas red is). Furthermore, the sensitivity of the bird’s eye is greatest in the middle and red part of the spectrum. This is sometimes ascribed to the presence in the retina of orange-red drops of oil, which together may act as a light filter.
Although other explanations have been forwarded, the special red sensitivity of the bird eye is usually thought to be the reason why so many bird-pollinated flowers are of a uniform, pure red color. Combinations of complementary colors, such as orange and blue, or green and red, also are found, as are white flowers. As might be expected, bird flowers generally lack smell and are open in the daytime; they are bigger than most insect flowers and have a wider floral tube. Bird flowers also are sturdily constructed as a protection against the probing bill of the visitors, with the ovules kept out of harm’s way in an inferior ovary beneath the floral chamber or placed at the end of a special stalk or behind a screen formed by the fused bases of the stamens. The latter, often so strong as to resemble metal wire, are usually numerous, brightly colored, and protruding, so that they touch a visiting bird on the breast or head as it feeds. The pollen grains often stick together in clumps or chains, with the result that a single visit may result in the fertilization of hundreds of ovules.
In the Americas, where hummingbirds usually drag the nectar of flowers on the wing, ornithophilous flowers (e.g., fuchsias) are often pendant and radially symmetrical, lacking the landing platform of the typical bee flower. In Africa and Asia, bird flowers often are erect and do offer their visitors, which do not hover, either a landing platform or special perches in the form of small twigs near the flower . Pollinating birds are bigger than insects and have a very high rate of metabolism. Although some hummingbirds go into a state resembling hibernation every night, curtailing their metabolism drastically, others keep late hours. Thus, in general, birds need much more nectar per individual than insects do. Accordingly, bird flowers produce nectar copiously—a thimbleful in each flower of the coral tree, for example, and as much as a liqueur glassful in flowers of the spear lily (Doryanthus). Plants bearing typical bird flowers are cardinal flower, fuchsia, red columbine, trumpet vine, hibiscus, strelitzia, and eucalyptus, and many members of the pea, orchid, cactus, and pineapple families.
Mammals
In Madagascar, the mouse lemurs (Microcebus), which are only ten centimeters (four inches) long, obtain food from flowers, and in Australia the diminutive marsupial honey possums and pygmy possums also are flower specialists. Certain highly specialized tropical bats, particularly Macroglossus and Glossophaga, also obtain most or all of their food from flowers. The Macroglossus (big-tongued) species of southern Asia and the Pacific are small bats with sharp snouts and long, extensible tongues, which carry special projections (papillae) and sometimes a brushlike tip for picking up a sticky mixture of nectar and pollen. Significantly, they are almost toothless. Color sense and that sonar sense so prominent in other bats, seem to be lacking. Their eyesight is keen but, since they feed at night, they are probably guided to the flowers principally by their highly developed sense of smell. The bats hook themselves into the petals with their thumb claws and stick their slender heads into the flowers, extracting viscid nectar and protein-rich pollen with their tongues.
The plants that utilize bat pollination have, in the process of evolution, responded to the winged mammals by producing large (sometimes huge) amounts of nectar and pollen foods. One balsa-tree flower, for example, may contain a full 10 grams (0.3 ounce) of nectar, and one flower from a baobab tree has about 2,000 pollen-producing stamens. Some bat flowers also provide succulent petals or special food bodies to their visitors. Another striking adaptation is that the flowers are often placed on the main trunk or the big limbs of a tree (cauliflory); or, borne on thin, ropelike branches, they dangle beneath the crown (flagelliflory). The pagoda shape of the kapok tree serves the same purpose: facilitation of the bat’s approach. Characteristics of the flowers themselves include drab color, large size, sturdiness, bell-shape with wide mouth and, frequently, a powerful rancid or urinelike smell. The giant saguaro cactus and the century plant (Agave) are pollinated by bats, although not exclusively, and cup-and-saucer vine (Cobaea scandens) is the direct descendant of a bat-pollinated American plant. Calabash, candle tree, and areca palm also have bat-pollinated flowers.
Water
Although pollen grains can be made to germinate in aqueous sugar solutions, water alone in most cases has a disastrous effect on them. Accordingly, only a very few terrestrial plants, such as the bog asphodel of the Faroes, use rainwater as a means of pollen transport. Even in aquatic plants, water is seldom the true medium of pollen dispersal. Thus, the famous Podostemonaceae, plants that grow only on rocks in rushing water, flower in the dry season when the plants are exposed; pollination occurs with the aid of wind or insects or by selfing. Another aquatic plant, ribbon weed, sends its male and female flowers to the surface separately. There, the former transform themselves into minute sailboats, which are driven by the wind until they collide with the female flowers. In the Canadian waterweed, and also in pondweed (Potamogeton) and ditch grass (Ruppia), the pollen itself is dispersed on the water’s surface; it is, however, still water-repellent. True water dispersal (hydrophily), in which the pollen grains are wet by water, is found only in the hornworts and eelgrasses.
Additional Information
Pollination is very important. It leads to the creation of new seeds that grow into new plants.
But how does pollination work? Well, it all begins in the flower. Flowering plants have several different parts that are important in pollination. Flowers have male parts called stamens that produce a sticky powder called pollen. Flowers also have a female part called the pistil. The top of the pistil is called the stigma, and is often sticky. Seeds are made at the base of the pistil, in the ovule.
To be pollinated, pollen must be moved from a stamen to the stigma. When pollen from a plant's stamen is transferred to that same plant's stigma, it is called self-pollination. When pollen from a plant's stamen is transferred to a different plant's stigma, it is called cross-pollination. Cross-pollination produces stronger plants. The plants must be of the same species. For example, only pollen from a daisy can pollinate another daisy. Pollen from a rose or an apple tree would not work.
How Do Plants Get Pollinated?
Pollination occurs in several ways. People can transfer pollen from one flower to another, but most plants are pollinated without any help from people. Usually plants rely on animals or the wind to pollinate them.
When animals such as bees, butterflies, moths, flies, and hummingbirds pollinate plants, it's accidental. They are not trying to pollinate the plant. Usually they are at the plant to get food, the sticky pollen or a sweet nectar made at the base of the petals. When feeding, the animals accidentally rub against the stamens and get pollen stuck all over themselves. When they move to another flower to feed, some of the pollen can rub off onto this new plant's stigma.
Plants that are pollinated by animals often are brightly colored and have a strong smell to attract the animal pollinators.
Wind-pollinated FlowerAnother way plants are pollinated is by the wind. The wind picks up pollen from one plant and blows it onto another.
Plants that are pollinated by wind often have long stamens and pistils. Since they do not need to attract animal pollinators, they can be dully colored, unscented, and with small or no petals since no insect needs to land on them.
It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2260 2024-08-18 00:19:13
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2262) Easel
Gist
An easel is a stand or frame for supporting or displaying at an angle an artist's canvas, a blackboard, a china plate, etc. Also called masking frame. Photography. a frame, often with adjustable masks, used to hold photographic paper flat and control borders when printing enlargements.
Summary
Easel is a frame for supporting something (as an artist's canvas) Etymology. from Dutch ezel "a frame to hold an artist's canvas," literally, "donkey" Word Origin. An easel is a frame for holding up such things as an artist's painting or a chalkboard.
Artists use easels to hold the canvas or paper they're working on — not just to display finished works of art. If you travel to a scenic overlook, you might see an artist painting the view onto a canvas, propped up on an easel.
Generally, the word “furniture” describes items that make a space suitable for working or living. An easel that holds an artwork for production or display purposes likely fits this definition.
If you're an artist, you probably use an easel, a stand that holds the canvas you're painting. If an art gallery displays your painting in the window on a solid gold easel, you’re making a splash in the art world!
An easel is a tripod, with three long legs that connect together at the top and spread out wide at the floor, for stability. Artists use easels to hold the canvas or paper they’re working on — not just to display finished works of art.
If you travel to a scenic overlook, you might see an artist painting the view onto a canvas, propped up on an easel. Easels can display other things, too, like letters, posters, or signs.
An easel is a structure designed to support an artist's canvas. You'll also often find them being used for displaying a finished piece of artwork. Today, they're typically used to allow artists to paint while standing, and they hold the canvas up at an angle of about 20 degrees.
Whether or not an easel is considered furniture is largely a matter of personal opinion. Generally, the word “furniture” describes items that make a space suitable for working or living. An easel that holds an artwork for production or display purposes likely fits this definition.
Easels offer different benefits to different artists. Some artists that use easels find that their painting process is much freer. The distance between you and the easel allows for more freedom of movement. There won't be the restriction to making movements just from the wrist.
They have tripod legs, and are made from wood or aluminum. French-style plein air easels contain built-in drawers for painting supplies, and a shelf for holding a palette. Some can also carry canvases.
Did you know there's a donkey behind “easel”? This word for a frame supporting an artist's canvas comes from the Dutch word “ezel,” meaning an math or donkey. The Dutch called the easel a “donkey” because it, like a beast of burden, lugged the artist's canvas from one spot to another.
Details
An easel is an upright support used for displaying and/or fixing something resting upon it, at an angle of about 20° to the vertical. In particular, painters traditionally use an easel to support a painting while they work on it, normally standing up; easels are also sometimes used to display finished paintings. Artists' easels are still typically made of wood, in functional designs that have changed little for centuries, or even millennia, though new materials and designs exist. Easels are typically made from wood, aluminum or steel.
Easel painting is a term in art history for the type of midsize painting that would have been painted on an easel, as opposed to a fresco wall painting, a large altarpiece or other piece that would have been painted resting on a floor, a small cabinet painting, or a miniature created while sitting at a desk, though perhaps also on an angled support. It does not refer to the way the painting is meant to be displayed; most easel paintings are intended for display framed and hanging on a wall.
In a photographic darkroom, an easel is used to keep the photographic paper in a flat or upright (horizontal, big-size enlarging) position to the enlarger.
Etymology
The word easel is an old Germanic synonym for donkey (compare similar semantics). In various other languages, its equivalent is the only word for both the animal and the apparatus, such as Afrikaans: esel and earlier Dutch: ezel (the easel generally in full Dutch: schildersezel, "painter's donkey"), themselves cognates of the Latin: asinus (math).
History
Easels have been in use since the time of the ancient Egyptians. In the 1st century, Pliny the Elder made reference to a "large panel" placed upon an easel.
Design
There are three common designs for easels:
* A Frame designs are based on three legs. Variations include: crossbars to make the easel more stable; and an independent mechanism to allow for the vertical adjustment of the working plane without sacrificing the stability of the legs of the easel.
* H-Frame designs are based on right angles. All posts are generally parallel to each other with the base of the easel being rectangular. The main, front portion of the easel consists of two vertical posts with a horizontal crossbar support, giving the design the general shape of an 'H'. A variation uses additions that allow the easel's angle with respect to the ground to be adjusted.
* Multiple purpose designs incorporate improved tripod and H-frame features with extra multiple adjustment capabilities that include finite rotational, horizontal and vertical adjustment of the working plane.
Differences
An easel can be full height, designed for standing by itself on the floor. Shorter easels can be designed for use on a table.
* Artists' easels typically are fully adjustable to accommodate for different angles. Most have built-in anti-skid plates on the feet to prevent sliding. They are collapsible and overall very slim in stature to fit in small spaces around the studio. The simplest form of an artist's easel, a tripod, consists of three vertical posts joined at one end. A pivoting mechanism allows the centre-most post to pivot away from the other two, while the two non-pivoting posts have a horizontal cross member where the canvas is placed. A similar model can hold a blackboard, projection surface, placard, etc.
* Pochade boxes are a type of artists' easel that is mounted on top of a camera tripod. They include both a support for the painting, as well as a palette. They may or may not include a box for supplies.
* Paint stations are meant as more stationary consoles. These are usually equipped with various holsters, slots and supporting platforms to accommodate for buckets, brushes and canvas styles. Most of the components can be broken down for easy cleaning and storage.
* Children's easels are intended to be more durable. They are typically shorter than standard easels and usually come equipped with dry erase boards and/or chalkboards attached.
* Display easels are for display purposes and are meant to enhance the presentation of a painting.
* Facilitation easels are for capturing audience or participant input and are meant to involve the participants with the content.
* Darkroom easels keep photographic paper in a flat or upright (horizontal, big-size enlarging) position to the enlarger.
Additional Information
As Easel is a Stand on which a painting is supported while the artist works on it. The oldest representation of an easel is on an Egyptian relief of the Old Kingdom (c. 2700–c. 2150 bc).
It is a stand or frame for supporting or displaying at an angle an artist's canvas, a blackboard, a china plate, etc. Also called masking frame. Photography. a frame, often with adjustable masks, used to hold photographic paper flat and control borders when printing enlargements.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2261 2024-08-19 00:03:48
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2263) Cotton Bale
Gist
Cotton Bale is a large bundle or package prepared for shipping, storage, or sale, especially one tightly compressed and secured by wires, hoops, cords, or the like, and sometimes having a wrapping or covering: a bale of cotton; a bale of hay.
The most important parameters of a cotton bale are: Density (448 kg/m^3) Measurements of the bales (nominally 1.40 m X 0.53 m X 0.69 m) Weight (Varies, but 'statistical' bale weighs 480 lb).
The cotton bale is opened, and its fibres are raked mechanically to remove foreign matter (e.g., soil and seeds). A picker (picking machine) then wraps the fibres into a lap.
Summary
Ever wondered how much cotton you might need to make your Australian cotton products? In a normal season, Australia's cotton growers produce around 4 million bales of cotton, enough to clothe around 500 million people.
The lint from one 227kg bale of cotton can produce:
* 215 pairs of denim jeans
* 250 single bed sheets
* 750 shirts
* 1,200 t-shirts
* 3000 nappies
* 4,300 pairs of socks
* 680,000 cotton balls
* 2,100 pairs of boxer shorts
Details
A cotton bale is a standard-sized and weighted pack of compressed cotton lint after ginning. The dimensions and weight may vary with different cotton-producing countries.
Significance
A bale has an essential role from the farm to the factory. The cotton yield is calculated in terms of the number of bales. Bale is a standard packaging method for cotton to avoid various hassles in handling, packing, and transportation. The bales also protect the lint from foreign contamination and make them readily identifiable.
Cotton bale management system
Bale management encompasses the systematic procedures of categorizing, blending, and assessing bales based on fiber attributes, with the aim of achieving desired quality yarn production at an optimized cost. Cotton fibres differ in terms of staple length and other physical characteristics; this is an inherent feature. Bale management, also known as "bale mixing," is the process of analysing, classifying, and then blending fibres from various bales [which also includes the bales received from other stations] according to their fibre properties in order to create yarn of a specific quality at the most affordable price.
Standards:
Bale
A "bale of cotton" is also the standard trading unit for cotton on the wholesale national and international markets. Although different cotton-growing countries have their bale standards, for example, In the United States, cotton is usually measured at approximately 0.48 cubic meters (17 cu ft) and weighs 226.8 kilograms (500 pounds). In India, the standard bale size is 170 kg.
Parameters
The most important parameters of a cotton bale are:
* Density (448 kg/m^3)
* Measurements of the bales (nominally 1.40 m X 0.53 m X 0.69 m)
* Weight (Varies, but ‘statistical’ bale weighs 480 lb)
Advances in standardization are reducing the variation in weights, sizes, dimensions, and densities of cotton bales.
Candy
Candy is another trading unit. A candy weighs approximately 2.09 bales (356 kg). In India, ginned cotton is traded in terms of candy also which weighs 356 kg (355.62 kg).
Trash
When cotton is harvested and exposed to ginning, it carries more than 64% cottonseed, 2% waste and 34% fibrous matter (also known as lint). Lower trash percentage in cotton increases the recovery. Cotton bales are not pure cotton; they contain foreign contaminants, residual trash and leaf (and other non lint material) that have a direct impact on the recovery in yarn spinning.
Additional Information
Cotton, seed-hair fibre of several species of plants of the genus Gossypium, belonging to the hibiscus, or mallow, family (Malvaceae).
Cotton, one of the world’s leading agricultural crops, is plentiful and economically produced, making cotton products relatively inexpensive. The fibres can be made into a wide variety of fabrics ranging from lightweight voiles and laces to heavy sailcloths and thick-piled velveteens, suitable for a great variety of wearing apparel, home furnishings, and industrial uses. Cotton fabrics can be extremely durable and resistant to abrasion. Cotton accepts many dyes, is usually washable, and can be ironed at relatively high temperatures. It is comfortable to wear because it absorbs and releases moisture quickly. When warmth is desired, it can be napped, a process giving the fabric a downy surface. Various finishing processes have been developed to make cotton resistant to stains, water, and mildew; to increase resistance to wrinkling, thus reducing or eliminating the need for ironing; and to reduce shrinkage in laundering to not more than 1 percent. Nonwoven cotton, made by fusing or bonding the fibres together, is useful for making disposable products to be used as towels, polishing cloths, tea bags, tablecloths, bandages, and disposable uniforms and sheets for hospital and other medical uses.
Cotton fibre processing
Cotton fibres may be classified roughly into three large groups, based on staple length (average length of the fibres making up a sample or bale of cotton) and appearance. The first group includes the fine, lustrous fibres with staple length ranging from about 2.5 to 6.5 cm (about 1 to 2.5 inches) and includes types of the highest quality—such as Sea Island, Egyptian, and pima cottons. Least plentiful and most difficult to grow, long-staple cottons are costly and are used mainly for fine fabrics, yarns, and hosiery. The second group contains the standard medium-staple cotton, such as American Upland, with staple length from about 1.3 to 3.3 cm (0.5 to 1.3 inches). The third group includes the short-staple, coarse cottons, ranging from about 1 to 2.5 cm (0.5 to 1 inch) in length, used to make carpets and blankets, coarse and inexpensive fabrics, and blends with other fibres.
Most of the seeds (cottonseed) are separated from the fibres by a mechanical process called ginning. Ginned cotton is shipped in bales to a textile mill for yarn manufacturing. A traditional and still common processing method is ring spinning, by which the mass of cotton may be subjected to opening and cleaning, picking, carding, combing, drawing, roving, and spinning. The cotton bale is opened, and its fibres are raked mechanically to remove foreign matter (e.g., soil and seeds). A picker (picking machine) then wraps the fibres into a lap. A card (carding) machine brushes the loose fibres into rows that are joined as a soft sheet, or web, and forms them into loose untwisted rope known as card sliver. For higher-quality yarn, card sliver is put through a combing machine, which straightens the staple further and removes unwanted short lengths, or noils. In the drawing (drafting) stage, a series of variable-speed rollers attenuates and reduces the sliver to firm uniform strands of usable size. Thinner strands are produced by the roving (slubbing) process, in which the sliver is converted to roving by being pulled and slightly twisted. Finally, the roving is transferred to a spinning frame, where it is drawn further, twisted on a ring spinner, and wound on a bobbin as yarn.
Faster production methods include rotor spinning (a type of open-end spinning), in which fibres are detached from the card sliver and twisted, within a rotor, as they are joined to the end of the yarn. For the production of cotton blends, air-jet spinning may be used; in this high-speed method, air currents wrap loose fibres around a straight sliver core. Blends (composites) are made during yarn processing by joining drawn cotton with other staple fibres, such as polyester or casein.
The procedure for weaving cotton yarn into fabric is similar to that for other fibres. Cotton looms interlace the tense lengthwise yarns, called warp, with crosswise yarns called weft, or filling. Warp yarns often are treated chemically to prevent breaking during weaving.
Cultivation of the cotton plant
The various species of cotton grown as agricultural crops are native to most subtropical parts of the world and were domesticated independently multiple times. Cotton can be found as perennial treelike plants in tropical climates but is normally cultivated as a shrubby annual in temperate climates. Whereas it grows up to 6 metres (20 feet) high in the tropics, it characteristically ranges from 1 to 2 metres (3 to 6.5 feet) in height under cultivation. Within 80–100 days after planting, the plant develops white blossoms, which change to a reddish colour. The fertilized blossoms fall off after a few days and are replaced by small green triangular pods, called bolls, that mature after a period of 55–80 days. During this period the seeds and their attached hairs develop within the boll, which increases considerably in size. The seed hair, or cotton fibre, reaching a maximum length of about 6 cm (2.5 inches) in long-fibre varieties, is known as lint. Linters, fibres considerably shorter than the seed hair and more closely connected to the seed, come from a second growth beginning about 10 days after the first seed hairs begin to develop. When ripe, the boll bursts into a white, fluffy ball containing three to five cells, each having 7 to 10 seeds embedded in a mass of seed fibres. Two-thirds of the weight of the seed cotton (i.e., the seed with the adhering seed hair) consists of the seeds. The fibres are composed of about 87 to 90 percent cellulose (a carbohydrate plant substance), 5 to 8 percent water, and 4 to 6 percent natural impurities.
Although cotton can be grown between latitudes 30° N and 30° S, yield and fibre quality are considerably influenced by climatic conditions, and best qualities are obtained with high moisture levels resulting from rainfall or irrigation during the growing season and a dry, warm season during the picking period.
To avoid damage to the cotton by wind or rain, it is picked as soon as the bolls open, but since the bolls do not all reach maturity simultaneously, an optimum time is chosen for harvesting by mechanical means. Handpicking, carried out over a period of several days, allows selection of the mature and opened bolls, so that a higher yield is possible. Handpicking also produces considerably cleaner cotton; mechanical harvesters pick the bolls by suction, accumulating loose material, dust, and dirt, and cannot distinguish between good and discoloured cotton. A chemical defoliant is usually applied before mechanical picking to cause the plants to shed their leaves, thus encouraging more uniform ripening of the bolls.
Pests and diseases
Cotton is attacked by several hundred species of insects, including such harmful species as the boll weevil, pink bollworm, cotton leafworm, cotton fleahopper, cotton aphid, rapid plant bug, conchuela, southern green stinkbug, spider mites (red spiders), grasshoppers, thrips, and tarnished plant bugs. Limited control of damage by insect pests can be achieved by proper timing of planting and other cultural practices or by selective breeding of varieties having some resistance to insect damage. Chemical insecticides, which were first introduced in the early 1900s, require careful and selective use because of ecological considerations but appear to be the most effective and efficient means of control. Conventional cotton production requires more insecticides than any other major crop, and the production of organic cotton, which relies on nonsynthetic insecticides, has been increasing in many places worldwide. Additionally, genetically modified “Bt cotton” was developed to produce bacterial proteins that are toxic to herbivorous insects, ostensibly reducing the amount of pesticides needed. Glyphosate-resistant cotton, which can tolerate the herbicide glyphosate, was also developed through genetic engineering.
The boll weevil (Anthonomus grandis), the most serious cotton pest in the United States in the early 1900s, was finally controlled by appropriate cultivation methods and by the application of such insecticides as chlorinated hydrocarbons and organophosphates. A species of boll weevil resistant to chlorinated hydrocarbons was recorded in the late 1950s; this species is combatted effectively with a mixture of toxaphene and DDT (dichlorodiphenyltrichloroethane), which has been outlawed in the United States and some other countries, however. The pink bollworm (Pectinophora gossypiella), originally reported in India in 1842, has spread throughout the cotton-producing countries, causing average annual crop losses of up to 25 percent in, for example, India, Egypt, China, and Brazil. Controls and quarantines of affected areas have helped limit the spread of the insect, and eradication has been possible in a few relatively small areas with sufficiently strict controls. The bollworm (Heliothis zea, also known as the corn earworm) feeds on cotton and many other wild and cultivated plants. Properly timed insecticide application provides fairly effective control.
Cotton plants are subject to diseases caused by various pathogenic fungi, bacteria, and viruses and to damage by nematodes (parasitic worms) and physiological disturbances also classified as diseases. Losses have been estimated as high as 50 percent in some African countries and in Brazil. Because young seedlings are especially sensitive to attack by a complex of disease organisms, treatment of seeds before planting is common. Some varieties have been bred that are resistant to a bacterial disease called angular leaf spot. Soil fumigation moderately succeeded in combatting such fungus diseases as fusarium wilt, verticillium wilt, and Texas root rot, which are restricted to certain conditions of soil, rainfall, and general climate. The breeding of resistant varieties, however, has been more effective.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2262 2024-08-19 21:17:26
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2264) Particle Accelerator
Gist
An accelerator propels charged particles, such as protons or electrons, at high speeds, close to the speed of light. They are then smashed either onto a target or against other particles circulating in the opposite direction. By studying these collisions, physicists are able to probe the world of the infinitely small.
Summary
Particle accelerators are devices that speed up the particles that make up all matter in the universe and collide them together or into a target. This allows scientists to study those particles and the forces that shape them. Specifically, particle accelerators speed up charged particles. These are particles with a positive or negative electrical charge such as protons, atomic nuclei, and the electrons that orbit atomic nuclei. In some cases, these particles reach speeds close to the speed of light. When the particles then collide with targets or other particles, the collisions that result can release energy, produce nuclear reactions, scatter particles, and produce other particles, such as neutrons. This gives scientists a look at what holds atoms, atomic nuclei, and nucleons together, as well as the world of particles like the Higgs boson. These particles and forces are the subject of the Standard Model of Particle Physics. Scientists also get insights into the quantum physics that govern how the world behaves at incredibly small scales. In the quantum realm, the classical Newtonian physics that we live with every day is insufficient to explain particle interactions.
How do these machines accelerate particles? They inject particles into a “beamline.” This is a pipe held at very low air pressure in order to keep the environment free of air and dust that might disturb the particles as they travel though the accelerator. The particles injected into an accelerator are referred to as a “beam.” A series of electromagnets steers and focuses the beam of particles. In a linear accelerator or LINAC (pronounced line-ack or lin-ack), the particles shoot straight toward a fixed target. In a circular accelerator, the particles travel around a ring, constantly gaining speed. Circular accelerators can speed particles up in less overall space than a LINAC, but they tend to be more complex to build and operate. However, because the particles travel in a circle, circular accelerators create many more opportunities for particles to collide. Particles collide into each other or a target in a device called a particle detector. This device measures the particles’ speed, mass, and charge. This information allows scientists to determine what types of particles result from a collision.
Details
A particle accelerator is a machine that uses electromagnetic fields to propel charged particles to very high speeds and energies to contain them in well-defined beams. Large accelerators are used for fundamental research in particle physics. Accelerators are also used as synchrotron light sources for the study of condensed matter physics. Smaller particle accelerators are used in a wide variety of applications, including particle therapy for oncological purposes, radioisotope production for medical diagnostics, ion implanters for the manufacture of semiconductors, and accelerator mass spectrometers for measurements of rare isotopes such as radiocarbon.
Large accelerators include the Relativistic Heavy Ion Collider at Brookhaven National Laboratory in New York and the largest accelerator, the Large Hadron Collider near Geneva, Switzerland, operated by CERN. It is a collider accelerator, which can accelerate two beams of protons to an energy of 6.5 TeV and cause them to collide head-on, creating center-of-mass energies of 13 TeV. There are more than 30,000 accelerators in operation around the world.
There are two basic classes of accelerators: electrostatic and electrodynamic (or electromagnetic) accelerators. Electrostatic particle accelerators use static electric fields to accelerate particles. The most common type is the Van de Graaff generator. A small-scale example of this class is the cathode-ray tube in an ordinary old television set. The achievable kinetic energy for particles in these devices is determined by the accelerating voltage, which is limited by electrical breakdown. Electrodynamic or electromagnetic accelerators, on the other hand, use changing electromagnetic fields (either magnetic induction or oscillating radio frequency fields) to accelerate particles. Since in these types the particles can pass through the same accelerating field multiple times, the output energy is not limited by the strength of the accelerating field. This class, which was first developed in the 1920s, is the basis for most modern large-scale accelerators.
Rolf Widerøe, Gustav Ising, Leó Szilárd, Max Steenbeck, and Ernest Lawrence are considered pioneers of this field, having conceived and built the first operational linear particle accelerator, the betatron, as well as the cyclotron. Because the target of the particle beams of early accelerators was usually the atoms of a piece of matter, with the goal being to create collisions with their nuclei in order to investigate nuclear structure, accelerators were commonly referred to as atom smashers in the 20th century. The term persists despite the fact that many modern accelerators create collisions between two subatomic particles, rather than a particle and an atomic nucleus.
Uses
Beams of high-energy particles are useful for fundamental and applied research in the sciences and also in many technical and industrial fields unrelated to fundamental research. There are approximately 30,000 accelerators worldwide; of these, only about 1% are research machines with energies above 1 GeV, while about 44% are for radiotherapy, 41% for ion implantation, 9% for industrial processing and research, and 4% for biomedical and other low-energy research.
Particle physics
For the most basic inquiries into the dynamics and structure of matter, space, and time, physicists seek the simplest kinds of interactions at the highest possible energies. These typically entail particle energies of many GeV, and interactions of the simplest kinds of particles: leptons (e.g. electrons and positrons) and quarks for the matter, or photons and gluons for the field quanta. Since isolated quarks are experimentally unavailable due to color confinement, the simplest available experiments involve the interactions of, first, leptons with each other, and second, of leptons with nucleons, which are composed of quarks and gluons. To study the collisions of quarks with each other, scientists resort to collisions of nucleons, which at high energy may be usefully considered as essentially 2-body interactions of the quarks and gluons of which they are composed. This elementary particle physicists tend to use machines creating beams of electrons, positrons, protons, and antiprotons, interacting with each other or with the simplest nuclei (e.g., hydrogen or deuterium) at the highest possible energies, generally hundreds of GeV or more.
The largest and highest-energy particle accelerator used for elementary particle physics is the Large Hadron Collider (LHC) at CERN, operating since 2009.
Nuclear physics and isotope production
Nuclear physicists and cosmologists may use beams of bare atomic nuclei, stripped of electrons, to investigate the structure, interactions, and properties of the nuclei themselves, and of condensed matter at extremely high temperatures and densities, such as might have occurred in the first moments of the Big Bang. These investigations often involve collisions of heavy nuclei – of atoms like iron or gold – at energies of several GeV per nucleon. The largest such particle accelerator is the Relativistic Heavy Ion Collider (RHIC) at Brookhaven National Laboratory.
Particle accelerators can also produce proton beams, which can produce proton-rich medical or research isotopes as opposed to the neutron-rich ones made in fission reactors; however, recent work has shown how to make 99Mo, usually made in reactors, by accelerating isotopes of hydrogen, although this method still requires a reactor to produce tritium. An example of this type of machine is LANSCE at Los Alamos National Laboratory.
Synchrotron radiation
Electrons propagating through a magnetic field emit very bright and coherent photon beams via synchrotron radiation. It has numerous uses in the study of atomic structure, chemistry, condensed matter physics, biology, and technology. A large number of synchrotron light sources exist worldwide. Examples in the U.S. are SSRL at SLAC National Accelerator Laboratory, APS at Argonne National Laboratory, ALS at Lawrence Berkeley National Laboratory, and NSLS-II at Brookhaven National Laboratory. In Europe, there are MAX IV in Lund, Sweden, BESSY in Berlin, Germany, Diamond in Oxfordshire, UK, ESRF in Grenoble, France, the latter has been used to extract detailed 3-dimensional images of insects trapped in amber.
Free-electron lasers (FELs) are a special class of light sources based on synchrotron radiation that provides shorter pulses with higher temporal coherence. A specially designed FEL is the most brilliant source of x-rays in the observable universe. The most prominent examples are the LCLS in the U.S. and European XFEL in Germany. More attention is being drawn towards soft x-ray lasers, which together with pulse shortening opens up new methods for attosecond science. Apart from x-rays, FELs are used to emit terahertz light, e.g. FELIX in Nijmegen, Netherlands, TELBE in Dresden, Germany and NovoFEL in Novosibirsk, Russia.
Thus there is a great demand for electron accelerators of moderate (GeV) energy, high intensity and high beam quality to drive light sources.
Low-energy machines and particle therapy
Everyday examples of particle accelerators are cathode ray tubes found in television sets and X-ray generators. These low-energy accelerators use a single pair of electrodes with a DC voltage of a few thousand volts between them. In an X-ray generator, the target itself is one of the electrodes. A low-energy particle accelerator called an ion implanter is used in the manufacture of integrated circuits.
At lower energies, beams of accelerated nuclei are also used in medicine as particle therapy, for the treatment of cancer.
DC accelerator types capable of accelerating particles to speeds sufficient to cause nuclear reactions are math–Walton generators or voltage multipliers, which convert AC to high voltage DC, or Van de Graaff generators that use static electricity carried by belts.
Radiation sterilization of medical devices
Electron beam processing is commonly used for sterilization. Electron beams are an on-off technology that provide a much higher dose rate than gamma or X-rays emitted by radioisotopes like cobalt-60 (60Co) or caesium-137 (137Cs). Due to the higher dose rate, less exposure time is required and polymer degradation is reduced. Because electrons carry a charge, electron beams are less penetrating than both gamma and X-rays.
Additional Information
Particle accelerator, any device that produces a beam of fast-moving, electrically charged atomic or subatomic particles. Physicists use accelerators in fundamental research on the structure of nuclei, the nature of nuclear forces, and the properties of nuclei not found in nature, as in the transuranium elements and other unstable elements. Accelerators are also used for radioisotope production, industrial radiography, radiation therapy, sterilization of biological materials, and a certain form of radiocarbon dating. The largest accelerators are used in research on the fundamental interactions of the elementary subatomic particles.
Principles of particle acceleration
Particle accelerators exist in many shapes and sizes (even the ubiquitous television picture tube is in principle a particle accelerator), but the smallest accelerators share common elements with the larger devices. First, all accelerators must have a source that generates electrically charged particles—electrons in the case of the television tube and electrons, protons, and their antiparticles in the case of larger accelerators. All accelerators must have electric fields to accelerate the particles, and they must have magnetic fields to control the paths of the particles. Also, the particles must travel through a good vacuum—that is, in a container with as little residual air as possible, as in a television tube. Finally, all accelerators must have some means of detecting, counting, and measuring the particles after they have been accelerated through the vacuum.
Generating particles
Electrons and protons, the particles most commonly used in accelerators, are found in all materials, but for an accelerator the appropriate particles must be separated out. Electrons are usually produced in exactly the same way as in a television picture tube, in a device known as an electron “gun.” The gun contains a cathode (negative electrode) in a vacuum, which is heated so that electrons break away from the atoms in the cathode material. The emitted electrons, which are negatively charged, are attracted toward an anode (positive electrode), where they pass through a hole. The gun itself is in effect a simple accelerator, because the electrons move through an electric field, as described below. The voltage between the cathode and the anode in an electron gun is typically 50,000–150,000 volts, or 50–150 kilovolts (kV).
As with electrons, there are protons in all materials, but only the nuclei of hydrogen atoms consist of single protons, so hydrogen gas is the source of particles for proton accelerators. In this case the gas is ionized—the electrons and protons are separated in an electric field—and the protons escape through a hole. In large high-energy particle accelerators, protons are often produced initially in the form of negative hydrogen ions. These are hydrogen atoms with an extra electron, which are also formed when the gas, originally in the form of molecules of two atoms, is ionized. Negative hydrogen ions prove easier to handle in the initial stages of large accelerators. They are later passed through thin foils to strip off the electrons before the protons move to the final stage of acceleration.
The key feature of any particle accelerator is the accelerating electric field. The simplest example is a uniform static field between positive and negative electric potentials (voltages), much like the field that exists between the terminals of an electric battery. In such a field an electron, bearing a negative charge, feels a force that directs it toward the positive potential (akin to the positive terminal of the battery). This force accelerates the electron, and if there is nothing to impede the electron, its velocity and its energy will increase. Electrons moving toward a positive potential along a wire or even in air will collide with atoms and lose energy, but if the electrons pass through a vacuum, they will accelerate as they move toward the positive potential.
The difference in electric potential between the position where the electron begins moving through the field and the place where it leaves the field determines the energy that the electron acquires. The energy an electron gains in traveling through a potential difference of 1 volt is known as 1 electron volt (eV). This is a tiny amount of energy, equivalent to 1.6 × {10}^{-19} joule. A flying mosquito has about a trillion times this energy. However, in a television tube, electrons are accelerated through more than 10,000 volts, giving them energies above 10,000 eV, or 10 kiloelectron volts (keV). Many particle accelerators reach much higher energies, measured in megaelectron volts (MeV, or million eV), gigaelectron volts (GeV, or billion eV), or teraelectron volts (TeV, or trillion eV).
Some of the earliest designs for particle accelerators, such as the voltage multiplier and the Van de Graaff generator, used constant electric fields created by potentials up to a million volts. It is not easy to work with such high voltages, however. A more-practical alternative is to make repeated use of weaker electric fields set up by lower voltages. This is the principle involved in two common categories of modern particle accelerators—linear accelerators (or linacs) and cyclic accelerators (principally the cyclotron and the synchrotron). In a linear accelerator the particles pass once through a sequence of accelerating fields, whereas in a cyclic machine they are guided on a circular path many times through the same relatively small electric fields. In both cases the final energy of the particles depends on the cumulative effect of the fields, so that many small “pushes” add together to give the combined effect of one big “push.”
The repetitive structure of a linear accelerator naturally suggests the use of alternating rather than constant voltages to create the electric fields. A positively charged particle accelerated toward a negative potential, for example, will receive a renewed push if the potential becomes positive as the particle passes by. In practice the voltages must change very rapidly. For example, at an energy of 1 MeV a proton is already traveling at very high speeds—46 percent of the speed of light—so that it covers a distance of about 1.4 metres (4.6 feet) in 0.01 microsecond. (One microsecond is a millionth of a second.) This implies that in a repeated structure several metres long, the electric fields must alternate—that is, change direction—at a frequency of at least 100 million cycles per second, or 100 megahertz (MHz). Both linear and cyclic accelerators generally accelerate particles by using the alternating electric fields present in electromagnetic waves, typically at frequencies from 100 to 3,000 MHz—that is, ranging from radiowaves to microwaves.
An electromagnetic wave is in effect a combination of oscillating electric and magnetic fields vibrating at right angles to each other. The key with a particle accelerator is to set up the wave so that, when the particles arrive, the electric field is in the direction needed to accelerate the particles. This can be done with a standing wave—a combination of waves moving in opposite directions in an enclosed space, rather like sound waves vibrating in an organ pipe. Alternatively, for very fast-moving electrons, which travel very close to the speed of light (in other words, close to the speed of the wave itself), a traveling wave can be used for acceleration.
An important effect that comes into play in acceleration in an alternating electric field is that of “phase stability.” In one cycle of its oscillation, an alternating field passes from zero through a maximum value to zero again and then falls to a minimum before rising back to zero. This means that the field passes twice through the value appropriate for acceleration—for example, during the rise and fall through the maximum. If a particle whose velocity is increasing arrives too soon as the field rises, it will not experience as high a field as it should and so will not receive as big a push. However, when it reaches the next region of accelerating fields, it will arrive late and so will receive a higher field—in other words, too big a push. The net effect will be phase stability—that is, the particle will be kept in phase with the field in each accelerating region. Another effect will be a grouping of the particles in time, so that they will form a train of bunches rather than a continuous beam of particles.
Guiding particles
Magnetic fields also play an important role in particle accelerators, as they can change the direction of charged particles. This means that they can be used to “bend” particle beams around a circular path so that they pass repeatedly through the same accelerating regions. In the simplest case a charged particle moving in a direction at right angles to the direction of a uniform magnetic field feels a force at right angles both to the particle’s direction and to the field. The effect of this force is to make the particle move on a circular path, perpendicular to the field, until it leaves the region of magnetic force or another force acts upon it. This effect comes into play in cyclic accelerators such as cyclotrons and synchrotrons. In the cyclotron a large magnet is used to provide a constant field in which the particles spiral outward as they are fed energy and thereby accelerate on each circuit. In a synchrotron, by contrast, the particles move around a ring of constant radius, while the field generated by electromagnets around the ring is increased as the particles accelerate. The magnets with this “bending” function are dipoles—magnets with two poles, north and south, built with a C-shaped profile so that the particle beam can pass between the two poles.
A second important function of electromagnets in particle accelerators is to focus the particle beams in order to keep them as narrow and intense as possible. The simplest form of focusing magnet is a quadrupole, a magnet built with four poles (two norths and two souths) arranged opposite each other. This arrangement pushes particles toward the centre in one direction but allows them to spread in the perpendicular direction. A quadrupole designed to focus a beam horizontally, therefore, will let the beam go out of focus vertically. In order to provide proper focusing, quadrupole magnets must be used in pairs, each member arranged to have the opposite effect. More-complex magnets with larger numbers of poles—sextupoles and octupoles—are also used for more-sophisticated focusing.
As the energy of the circulating particles increases, the strength of the magnetic field guiding them is increased, which thus keeps the particles on the same path. A “pulse” of particles is injected into the ring and accelerated to the desired energy before it is extracted and delivered to experiments. Extraction is usually achieved by “kicker” magnets, electromagnets that switch on just long enough to “kick” the particles out of the synchrotron ring and along a beam line. The fields in the dipole magnets are then ramped down, and the machine is ready to receive its next pulse of particles.
Colliding particles
Most of the particle accelerators used in medicine and industry produce a beam of particles for a specific purpose—for example, for radiation therapy or ion implantation. This means that the particles are used once and then discarded. For many years the same was true for accelerators used in particle physics research. However, in the 1970s rings were developed in which two beams of particles circulate in opposite directions and collide on each circuit of the machine. A major advantage of such machines is that when two beams collide head-on, the energy of the particles goes directly into the energy of the interactions between them. This contrasts with what happens when an energetic beam collides with material at rest: in this case much of the energy is lost in setting the target material in motion, in accord with the principle of conservation of momentum.
Some colliding-beam machines have been built with two rings that cross at two or more positions, with beams of the same kind circulating in opposite directions. More common yet have been particle-antiparticle colliders. An antiparticle has opposite electric charge to its related particle. For example, an antielectron (or positron) has positive charge, while the electron has negative charge. This means that an electric field that accelerates an electron will decelerate a positron moving in the same direction as the electron. But if the positron is traveling through the field in the opposite direction, it will feel an opposite force and will be accelerated. Similarly, an electron moving though a magnetic field will be bent in one direction—left, say—while a positron moving the same way will be bent in the opposite direction—to the right. If, however, the positron moves through the magnetic field in the opposite direction to the electron, its path will still bend to the right, but along the same curve taken by the leftward-bending electron. Taken together, these effects mean that an antielectron can travel around a synchrotron ring guided by the same magnets and accelerated by the same electric fields that affect an electron traveling the opposite way. Many of the highest-energy colliding-beam machines have been particle-antiparticle colliders, as only one accelerator ring is needed.
As is pointed out above, the beam in a synchrotron is not a continuous stream of particles but is clustered into “bunches.” A bunch may be a few centimetres long and a tenth of a millimetre across, and it may contain about {10}^{12} particles—the actual numbers depending on the specific machine. However, this is not very dense; normal matter of similar dimensions contains about {10}^{23} atoms. So when particle beams—or, more accurately, particle bunches—cross in a colliding-beam machine, there is only a small chance that two particles will interact. In practice the bunches can continue around the ring and intersect again. To enable this repeated beam crossing, the vacuum in the rings of colliding-beam machines must be particularly good so that the particles can circulate for many hours without being lost through collisions with residual air molecules. The rings are therefore also referred to as storage rings, as the particle beams are in effect stored within them for several hours.
Detecting particles
Most uses of the beams from particle accelerators require some way of detecting what happens when the particles strike a target or another particle beam traveling in the opposite direction. In a television picture tube, the electrons shot from the electron gun strike special phosphors on the inside surface of the screen, and these emit light, which thereby re-creates the televised images. With particle accelerators similarly specialized detectors respond to scattered particles, but these detectors are usually designed to create electrical signals that can be transformed into computer data and analyzed by computer programs. Only electrically charged particles create electrical signals as they move through a material—for example, by exciting or ionizing the atoms—and can be detected directly. Neutral particles, such as neutrons or photons, must be detected indirectly through the behaviour of charged particles that they themselves set in motion.
There are a great variety of particle detectors, many of which are most useful in specific circumstances. Some, such as the familiar Geiger counter, simply count particles, whereas others are used, for example, to record the tracks of charged particles or to measure the velocity of a particle or the amount of energy it carries. Modern detectors vary in size and technology from small charge-coupled devices (CCDs) to large gas-filled chambers threaded with wires that sense the ionized trails created by charged particles.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2263 2024-08-20 16:34:15
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2265) Brake
Gist
Brake is the part of a vehicle that makes it go slower or stop.
Summary
brake, device for decreasing the speed of a body or for stopping its motion. Most brakes act on rotating mechanical elements and absorb kinetic energy either mechanically, hydrodynamically, or electrically.
Mechanical brakes are the most common; they dissipate kinetic energy in the form of heat generated by mechanical friction between a rotating metallic drum or disk and a stationary friction element brought into contact with it by mechanical, hydraulic, or pneumatic means. The friction elements for drum brakes may be bands or shoes (blocks with one concave surface); for disk brakes they are pads or rings. Friction materials may be organic, metallic, or ceramic; molded asbestos is commonly used.
Mechanical operation by means of rigid links is satisfactory for single brakes, but when several brakes are actuated from a single source, as on an automobile, it is difficult to obtain equal braking effectiveness on all wheels; for this reason, hydraulic actuation, with oil under the same pressure acting on all brakes, is preferable. The braking of railroad cars is effected by cast-iron shoes that bear directly on the circumference of the wheels and are activated by compressed air.
A hydrodynamic (fluid) brake has a rotor (rotating element) and a stator (stationary element) that resemble the impeller and runner in a hydraulic coupling. Resistance to rotation is created by fluid friction and circulation of the liquid (usually water) from a series of pockets in the rotor to a series of complementary pockets in the stator. Because the resistance to rotation—i.e., braking power—depends on the speed of the rotor, these brakes cannot completely stop a rotating member; however, if means for cooling the liquid are provided, they can dissipate large amounts of kinetic energy in a very effective manner.
Details
A brake is a mechanical device that inhibits motion by absorbing energy from a moving system. It is used for slowing or stopping a moving vehicle, wheel, axle, or to prevent its motion, most often accomplished by means of friction.
Background
Most brakes commonly use friction between two surfaces pressed together to convert the kinetic energy of the moving object into heat, though other methods of energy conversion may be employed. For example, regenerative braking converts much of the energy to electrical energy, which may be stored for later use. Other methods convert kinetic energy into potential energy in such stored forms as pressurized air or pressurized oil. Eddy current brakes use magnetic fields to convert kinetic energy into electric current in the brake disc, fin, or rail, which is converted into heat. Still other braking methods even transform kinetic energy into different forms, for example by transferring the energy to a rotating flywheel.
Brakes are generally applied to rotating axles or wheels, but may also take other forms such as the surface of a moving fluid (flaps deployed into water or air). Some vehicles use a combination of braking mechanisms, such as drag racing cars with both wheel brakes and a parachute, or airplanes with both wheel brakes and drag flaps raised into the air during landing.
Since kinetic energy increases quadratically with velocity
, an object moving at 10 m/s has 100 times as much energy as one of the same mass moving at 1 m/s, and consequently the theoretical braking distance, when braking at the traction limit, is up to 100 times as long. In practice, fast vehicles usually have significant air drag, and energy lost to air drag rises quickly with speed.Almost all wheeled vehicles have a brake of some sort. Even baggage carts and shopping carts may have them for use on a moving ramp. Most fixed-wing aircraft are fitted with wheel brakes on the undercarriage. Some aircraft also feature air brakes designed to reduce their speed in flight. Notable examples include gliders and some World War II-era aircraft, primarily some fighter aircraft and many dive bombers of the era. These allow the aircraft to maintain a safe speed in a steep descent. The Saab B 17 dive bomber and Vought F4U Corsair fighter used the deployed undercarriage as an air brake.
Friction brakes on automobiles store braking heat in the drum brake or disc brake while braking then conduct it to the air gradually. When traveling downhill some vehicles can use their engines to brake.
When the brake pedal of a modern vehicle with hydraulic brakes is pushed against the master cylinder, ultimately a piston pushes the brake pad against the brake disc which slows the wheel down. On the brake drum it is similar as the cylinder pushes the brake shoes against the drum which also slows the wheel down.
Types
Brakes may be broadly described as using friction, pumping, or electromagnetics. One brake may use several principles: for example, a pump may pass fluid through an orifice to create friction:
Frictional
Frictional brakes are most common and can be divided broadly into "shoe" or "pad" brakes, using an explicit wear surface, and hydrodynamic brakes, such as parachutes, which use friction in a working fluid and do not explicitly wear. Typically the term "friction brake" is used to mean pad/shoe brakes and excludes hydrodynamic brakes, even though hydrodynamic brakes use friction. Friction (pad/shoe) brakes are often rotating devices with a stationary pad and a rotating wear surface. Common configurations include shoes that contract to rub on the outside of a rotating drum, such as a band brake; a rotating drum with shoes that expand to rub the inside of a drum, commonly called a "drum brake", although other drum configurations are possible; and pads that pinch a rotating disc, commonly called a "disc brake". Other brake configurations are used, but less often. For example, PCC trolley brakes include a flat shoe which is clamped to the rail with an electromagnet; the Murphy brake pinches a rotating drum, and the Ausco Lambert disc brake uses a hollow disc (two parallel discs with a structural bridge) with shoes that sit between the disc surfaces and expand laterally.
A drum brake is a vehicle brake in which the friction is caused by a set of brake shoes that press against the inner surface of a rotating drum. The drum is connected to the rotating roadwheel hub.
Drum brakes generally can be found on older car and truck models. However, because of their low production cost, drum brake setups are also installed on the rear of some low-cost newer vehicles. Compared to modern disc brakes, drum brakes wear out faster due to their tendency to overheat.
The disc brake is a device for slowing or stopping the rotation of a road wheel. A brake disc (or rotor in U.S. English), usually made of cast iron or ceramic, is connected to the wheel or the axle. To stop the wheel, friction material in the form of brake pads (mounted in a device called a brake caliper) is forced mechanically, hydraulically, pneumatically or electromagnetically against both sides of the disc. Friction causes the disc and attached wheel to slow or stop.
Pumping
Pumping brakes are often used where a pump is already part of the machinery. For example, an internal-combustion piston motor can have the fuel supply stopped, and then internal pumping losses of the engine create some braking. Some engines use a valve override called a Jake brake to greatly increase pumping losses. Pumping brakes can dump energy as heat, or can be regenerative brakes that recharge a pressure reservoir called a hydraulic accumulator.
Electromagnetic
Electromagnetic brakes are likewise often used where an electric motor is already part of the machinery. For example, many hybrid gasoline/electric vehicles use the electric motor as a generator to charge electric batteries and also as a regenerative brake. Some diesel/electric railroad locomotives use the electric motors to generate electricity which is then sent to a resistor bank and dumped as heat. Some vehicles, such as some transit buses, do not already have an electric motor but use a secondary "retarder" brake that is effectively a generator with an internal short circuit. Related types of such a brake are eddy current brakes, and electro-mechanical brakes (which actually are magnetically driven friction brakes, but nowadays are often just called "electromagnetic brakes" as well).
Electromagnetic brakes slow an object through electromagnetic induction, which creates resistance and in turn either heat or electricity. Friction brakes apply pressure on two separate objects to slow the vehicle in a controlled manner.
Characteristics
Brakes are often described according to several characteristics including:
* Peak force – The peak force is the maximum decelerating effect that can be obtained. The peak force is often greater than the traction limit of the tires, in which case the brake can cause a wheel skid.
* Continuous power dissipation – Brakes typically get hot in use and fail when the temperature gets too high. The greatest amount of power (energy per unit time) that can be dissipated through the brake without failure is the continuous power dissipation. Continuous power dissipation often depends on e.g., the temperature and speed of ambient cooling air.
* Fade – As a brake heats, it may become less effective, called brake fade. Some designs are inherently prone to fade, while other designs are relatively immune. Further, use considerations, such as cooling, often have a big effect on fade.
* Smoothness – A brake that is grabby, pulses, has chatter, or otherwise exerts varying brake force may lead to skids. For example, railroad wheels have little traction, and friction brakes without an anti-skid mechanism often lead to skids, which increases maintenance costs and leads to a "thump thump" feeling for riders inside.
* Power – Brakes are often described as "powerful" when a small human application force leads to a braking force that is higher than typical for other brakes in the same class. This notion of "powerful" does not relate to continuous power dissipation, and may be confusing in that a brake may be "powerful" and brake strongly with a gentle brake application, yet have lower (worse) peak force than a less "powerful" brake.
* Pedal feel – Brake pedal feel encompasses subjective perception of brake power output as a function of pedal travel. Pedal travel is influenced by the fluid displacement of the brake and other factors.
* Drag – Brakes have varied amount of drag in the off-brake condition depending on design of the system to accommodate total system compliance and deformation that exists under braking with ability to retract friction material from the rubbing surface in the off-brake condition.
* Durability – Friction brakes have wear surfaces that must be renewed periodically. Wear surfaces include the brake shoes or pads, and also the brake disc or drum. There may be tradeoffs, for example, a wear surface that generates high peak force may also wear quickly.
* Weight – Brakes are often "added weight" in that they serve no other function. Further, brakes are often mounted on wheels, and unsprung weight can significantly hurt traction in some circumstances. "Weight" may mean the brake itself, or may include additional support structure.
* Noise – Brakes usually create some minor noise when applied, but often create squeal or grinding noises that are quite loud.
Foundation components
Foundation components are the brake-assembly components at the wheels of a vehicle, named for forming the basis of the rest of the brake system. These mechanical parts contained around the wheels are controlled by the air brake system.
The three types of foundation brake systems are “S” cam brakes, disc brakes and wedge brakes.
Brake boost
Most modern passenger vehicles, and light vans, use a vacuum assisted brake system that greatly increases the force applied to the vehicle's brakes by its operator. This additional force is supplied by the manifold vacuum generated by air flow being obstructed by the throttle on a running engine. This force is greatly reduced when the engine is running at fully open throttle, as the difference between ambient air pressure and manifold (absolute) air pressure is reduced, and therefore available vacuum is diminished. However, brakes are rarely applied at full throttle; the driver takes the right foot off the gas pedal and moves it to the brake pedal - unless left-foot braking is used.
Because of low vacuum at high RPM, reports of unintended acceleration are often accompanied by complaints of failed or weakened brakes, as the high-revving engine, having an open throttle, is unable to provide enough vacuum to power the brake booster. This problem is exacerbated in vehicles equipped with automatic transmissions as the vehicle will automatically downshift upon application of the brakes, thereby increasing the torque delivered to the driven-wheels in contact with the road surface.
Heavier road vehicles, as well as trains, usually boost brake power with compressed air, supplied by one or more compressors.
Noise
Although ideally a brake would convert all the kinetic energy into heat, in practice a significant amount may be converted into acoustic energy instead, contributing to noise pollution.
For road vehicles, the noise produced varies significantly with tire construction, road surface, and the magnitude of the deceleration. Noise can be caused by different things. These are signs that there may be issues with brakes wearing out over time.
Fires
Railway brake malfunctions can produce sparks and cause forest fires. In some very extreme cases, disc brakes can become red hot and set on fire. This happened in the Tuscan GP, when the Mercedes car, the W11 had its front carbon disc brakes almost bursting into flames, due to low ventilation and high usage. These fires can also occur on some Mercedes Sprinter vans, when the load adjusting sensor seizes up and the rear brakes have to compensate for the fronts.
Inefficiency
A significant amount of energy is always lost while braking, even with regenerative braking which is not perfectly efficient. Therefore, a good metric of efficient energy use while driving is to note how much one is braking. If the majority of deceleration is from unavoidable friction instead of braking, one is squeezing out most of the service from the vehicle. Minimizing brake use is one of the fuel economy-maximizing behaviors.
While energy is always lost during a brake event, a secondary factor that influences efficiency is "off-brake drag", or drag that occurs when the brake is not intentionally actuated. After a braking event, hydraulic pressure drops in the system, allowing the brake caliper pistons to retract. However, this retraction must accommodate all compliance in the system (under pressure) as well as thermal distortion of components like the brake disc or the brake system will drag until the contact with the disc, for example, knocks the pads and pistons back from the rubbing surface. During this time, there can be significant brake drag. This brake drag can lead to significant parasitic power loss, thus impacting fuel economy and overall vehicle performance.
History:
Early brake system
In the 1890s, Wooden block brakes became obsolete when Michelin brothers introduced rubber tires.
During the 1960s, some car manufacturers replaced drum brakes with disc brakes.
Electronic brake system
In 1966, the ABS was fitted in the Jensen FF grand tourer.
In 1978, Bosch and Mercedes updated their 1936 anti-lock brake system for the Mercedes S-Class. That ABS is a fully electronic, four-wheel and multi-channel system that later became standard.
In 2005, ESC — which automatically applies the brakes to avoid a loss of steering control — become compulsory for carriers of dangerous goods without data recorders in the Canadian province of Quebec.
Since 2017, numerous United Nations Economic Commission for Europe (UNECE) countries use Brake Assist System (BAS) a function of the braking system that deduces an emergency braking event from a characteristic of the driver's brake demand and under such conditions assist the driver to improve braking.
In July 2013 UNECE vehicle regulation 131 was enacted. This regulation defines Advanced Emergency Braking Systems (AEBS) for heavy vehicles to automatically detect a potential forward collision and activate the vehicle braking system.
On 23 January 2020 UNECE vehicle regulation 152 was enacted, defining Advanced Emergency Braking Systems for light vehicles.
From May 2022, in the European Union, by law, new vehicles will have advanced emergency-braking system.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2264 2024-08-20 21:45:06
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2266) Engine Oil / Motor Oil
Gist
Motor oil provides lubrication to the many moving parts of an engine, which helps to avoid damage and keep your engine running smoothly. Each time your engine runs, by-products from combustion are collected in your engine oil.
Motor oil is a lubricant used in internal combustion engines, which power cars, motorcycles, lawnmowers, engine-generators, and many other machines. In engines, there are parts which move against each other, and the friction between the parts wastes otherwise useful power by converting kinetic energy into heat.
Summary:
The prime function of engine oil is to lubricate the engine parts, which are in constant friction. It thus reduces friction which tends to increase wear & tear of engine parts.
Benefits
* Keeps engine clean on inside
* Keeps engine cool
* Prevents rusting of engine parts
* Less sludge build up
* Improves engine performance and fuel economy
* Increased life of the engine.
Details
Motor oil, engine oil, or engine lubricant is any one of various substances used for the lubrication of internal combustion engines. They typically consist of base oils enhanced with various additives, particularly antiwear additives, detergents, dispersants, and, for multi-grade oils, viscosity index improvers. The main function of motor oil is to reduce friction and wear on moving parts and to clean the engine from sludge (one of the functions of dispersants) and varnish (detergents). It also neutralizes acids that originate from fuel and from oxidation of the lubricant (detergents), improves the sealing of piston rings, and cools the engine by carrying heat away from moving parts.
In addition to the aforementioned basic constituents, almost all lubricating oils contain corrosion and oxidation inhibitors. Motor oil may be composed of only a lubricant base stock in the case of non-detergent oil, or a lubricant base stock plus additives to improve the oil's detergency, extreme pressure performance, and ability to inhibit corrosion of engine parts.
Motor oils are blended using base oils composed of petroleum-based hydrocarbons, polyalphaolefins (PAO), or their mixtures in various proportions, sometimes with up to 20% by weight of esters for better dissolution of additives.
History
On 6 September 1866, American John Ellis founded the Continuous Oil Refining Company. While studying the possible healing powers of crude oil, Dr. Ellis was disappointed to find no real medicinal value, but was intrigued by its potential lubricating properties. He eventually abandoned the medical practice to devote his time to the development of an all-petroleum, high-viscosity lubricant for steam engines – which at the time were using inefficient combinations of petroleum and animal and vegetable fats. He made his breakthrough when he developed an oil that worked effectively at high temperatures. This meant fewer gummed up valves and corroded cylinders.
Use
Motor oil is a lubricant used in internal combustion engines, which power cars, motorcycles, lawnmowers, engine-generators, and many other machines. In engines, there are parts which move against each other, and the friction between the parts wastes otherwise useful power by converting kinetic energy into heat. It also wears away those parts, which could lead to lower efficiency and degradation of the engine. Proper lubrication decreases fuel consumption, decreases wasted power, and increases engine longevity.
Lubricating oil creates a separating film between surfaces of adjacent moving parts to minimize direct contact between them, decreasing frictional heat and reducing wear, thus protecting the engine. In use, motor oil transfers heat through conduction as it flows through the engine. In an engine with a recirculating oil pump, this heat is transferred by means of airflow over the exterior surface of the oil pan, airflow through an oil cooler, and through oil gases evacuated by the positive crankcase ventilation (PCV) system. While modern recirculating pumps are typically provided in passenger cars and other engines of similar or larger in size, total-loss oiling is a design option that remains popular in small and miniature engines.
In petrol (gasoline) engines, the top piston ring can expose the motor oil to temperatures of 160 °C (320 °F). In diesel engines, the top ring can expose the oil to temperatures over 315 °C (600 °F). Motor oils with higher viscosity indices thin less at these higher temperatures.
Coating metal parts with oil also keeps them from being exposed to oxygen, inhibiting oxidation at elevated operating temperatures preventing rust or corrosion. Corrosion inhibitors may also be added to the motor oil. Many motor oils also have detergents and dispersants added to help keep the engine clean and minimize oil sludge build-up. The oil is able to trap soot from combustion in itself, rather than leaving it deposited on the internal surfaces. It is a combination of this and some singeing that turns used oil black after some running.
Rubbing of metal engine parts inevitably produces some microscopic metallic particles from the wearing of the surfaces. Such particles could circulate in the oil and grind against moving parts, causing wear. Because particles accumulate in the oil, it is typically circulated through an oil filter to remove harmful particles. An oil pump, a vane or gear pump powered by the engine, pumps the oil throughout the engine, including the oil filter. Oil filters can be a full flow or bypass type.
In the crankcase of a vehicle engine, motor oil lubricates rotating or sliding surfaces between the crankshaft journal bearings (main bearings and big-end bearings) and rods connecting the pistons to the crankshaft. The oil collects in an oil pan, or sump, at the bottom of the crankcase. In some small engines such as lawn mower engines, dippers on the bottoms of connecting rods dip into the oil at the bottom and splash it around the crankcase as needed to lubricate parts inside. In modern vehicle engines, the oil pump takes oil from the oil pan and sends it through the oil filter into oil galleries, from which the oil lubricates the main bearings holding the crankshaft up at the main journals and camshaft bearings operating the valves. In typical modern vehicles, oil pressure-fed from the oil galleries to the main bearings enters holes in the main journals of the crankshaft.
From these holes in the main journals, the oil moves through passageways inside the crankshaft to exit holes in the rod journals to lubricate the rod bearings and connecting rods. Some simpler designs relied on these rapidly moving parts to splash and lubricate the contacting surfaces between the piston rings and interior surfaces of the cylinders. However, in modern designs, there are also passageways through the rods which carry oil from the rod bearings to the rod-piston connections and lubricate the contacting surfaces between the piston rings and interior surfaces of the cylinders. This oil film also serves as a seal between the piston rings and cylinder walls to separate the combustion chamber in the cylinder head from the crankcase. The oil then drips back down into the oil pan.
Motor oil may also serve as a cooling agent. In some engines oil is sprayed through a nozzle inside the crankcase onto the piston to provide cooling of specific parts that undergo high-temperature strain. On the other hand, the thermal capacity of the oil pool has to be filled, i.e. the oil has to reach its designed temperature range before it can protect the engine under high load. This typically takes longer than heating the main cooling agent – water or mixtures thereof – up to its operating temperature. In order to inform the driver about the oil temperature, some older and most high-performance or racing engines feature an oil thermometer.
Continued operation of an internal combustion engine without adequate engine oil can cause damage to the engine, first by wear and tear, and in extreme cases by "engine seizure" where the lack of lubrication and cooling causes the engine to cease operation suddenly. Engine seizure can cause extensive damage to the engine mechanisms.
Non-vehicle motor oils
An example is lubricating oil for four-stroke or four-cycle internal combustion engines such as those used in portable electricity generators and "walk behind" lawn mowers. Another example is two-stroke oil for lubrication of two-stroke or two-cycle internal combustion engines found in snow blowers, chain saws, model airplanes, gasoline-powered gardening equipment like hedge trimmers, leaf blowers and soil cultivators. Often, these motors are not exposed to as wide of service temperature ranges as in vehicles, so these oils may be single viscosity oils.
In small two-stroke engines, the oil may be pre-mixed with the gasoline or fuel, often in a rich gasoline: oil ratio of 25:1, 40:1 or 50:1, and burned in use along with the gasoline. Larger two-stroke engines used in boats and motorcycles may have a more economical oil injection system rather than oil pre-mixed into the gasoline. The oil injection system is not used on small engines used in applications like snowblowers and trolling motors as the oil injection system is too expensive for small engines and would take up too much room on the equipment. The oil properties will vary according to the individual needs of these devices. Non-smoking two-stroke oils are composed of esters or polyglycols. Environmental legislation for leisure marine applications, especially in Europe, encouraged the use of ester-based two cycle oil.
Properties
Most motor oils are made from a heavier, thicker petroleum hydrocarbon base stock derived from crude oil, with additives to improve certain properties. The bulk of a typical motor oil consists of hydrocarbons with between 18 and 34 carbon atoms per molecule. One of the most important properties of motor oil in maintaining a lubricating film between moving parts is its viscosity. The viscosity of a liquid can be thought of as its "thickness" or a measure of its resistance to flow. The viscosity must be high enough to maintain a lubricating film, but low enough that the oil can flow around the engine parts under all conditions. The viscosity index is a measure of how much the oil's viscosity changes as temperature changes. A higher viscosity index indicates the viscosity changes less with temperature than a lower viscosity index.
Motor oil must be able to flow adequately at the lowest temperature it is expected to experience in order to minimize metal to metal contact between moving parts upon starting up the engine. The pour point defined first this property of motor oil, as defined by ASTM D97 as "...an index of the lowest temperature of its utility..." for a given application, but the cold-cranking simulator (CCS) and mini-rotary viscometer (MRV), are today the properties required in motor oil specs and define the Society of Automotive Engineers (SAE) classifications.
Oil is largely composed of hydrocarbons which can burn if ignited. Still another important property of motor oil is its flash point, the lowest temperature at which the oil gives off vapors which can ignite. It is dangerous for the oil in a motor to ignite and burn, so a high flash point is desirable. At a petroleum refinery, fractional distillation separates a motor oil fraction from other crude oil fractions, removing the more volatile components, and therefore increasing the oil's flash point (reducing its tendency to burn).
Another manipulated property of motor oil is its total base number (TBN), which is a measurement of the reserve alkalinity of an oil, meaning its ability to neutralize acids. The resulting quantity is determined as mg KOH/ (gram of lubricant). Analogously, total acid number (TAN) is the measure of a lubricant's acidity. Other tests include zinc, phosphorus, or sulfur content, and testing for excessive foaming.
The Noack volatility test (ASTM D-5800) determines the physical evaporation loss of lubricants in high temperature service. A maximum of 14% evaporation loss is allowable to meet API SL and ILSAC GF-3 specifications. Some automotive OEM oil specifications require lower than 10%.
Viscosity grades
Main article: SAE J300
The Society of Automotive Engineers (SAE) has established a numerical code system for grading motor oils according to their viscosity characteristics known as SAE J300. This standard is commonly used throughout the world, and standards organizations that do so include API and ACEA. The grades include single grades, such as SAE 30, and also multi-grades such as SAE 15W-30. A multi-grade consists of a winter grade specifying the viscosity at cold temperatures and a non-winter grade specifying the viscosity at operating temperatures. An engine oil using a polymeric viscosity index improver (VII) must be classified as multi-grade.
Breakdown of VIIs under shear is a concern in motorcycle applications, where the transmission may share lubricating oil with the motor. For this reason, motorcycle-specific oil is sometimes recommended. The necessity of higher-priced motorcycle-specific oil has also been challenged by at least one consumer organization.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2265 2024-08-21 16:25:07
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2267) Interview
Gist
Interviews almost always involve a spoken conversation between two or more parties, but can also happen between two persons who type their questions and answers. Interviews can be unstructured, free-wheeling, and open-ended conversations without a predetermined plan or prearranged questions.
Summary
An interview is a structured conversation where one participant asks questions, and the other provides answers. In common parlance, the word "interview" refers to a one-on-one conversation between an interviewer and an interviewee. The interviewer asks questions to which the interviewee responds, usually providing information. That information may be used or provided to other audiences immediately or later. This feature is common to many types of interviews – a job interview or interview with a witness to an event may have no other audience present at the time, but the answers will be later provided to others in the employment or investigative process. An interview may also transfer information in both directions.
Interviews usually take place face-to-face, in person, but the parties may instead be separated geographically, as in videoconferencing or telephone interviews. Interviews almost always involve a spoken conversation between two or more parties, but can also happen between two persons who type their questions and answers.
Interviews can be unstructured, free-wheeling, and open-ended conversations without a predetermined plan or prearranged questions. One form of unstructured interview is a focused interview in which the interviewer consciously and consistently guides the conversation so that the interviewee's responses do not stray from the main research topic or idea. Interviews can also be highly structured conversations in which specific questions occur in a specified order. They can follow diverse formats; for example, in a ladder interview, a respondent's answers typically guide subsequent interviews, with the object being to explore a respondent's subconscious motives. Typically the interviewer has some way of recording the information that is gleaned from the interviewee, often by keeping notes with a pencil and paper, or with a video or audio recorder.
The traditionally two-person interview format, sometimes called a one-on-one interview, permits direct questions and follow-ups, which enables an interviewer to better gauge the accuracy and relevance of responses. It is a flexible arrangement in the sense that subsequent questions can be tailored to clarify earlier answers. Further, it eliminates possible distortion due to other parties being present. Interviews have taken on an even more significant role, offering opportunities to showcase not just expertise, but adaptability and strategic thinking.
Contexts
Interviews can happen in a wide variety of contexts:
* Employment. A job interview is a formal consultation for evaluating the qualifications of the interviewee for a specific position. One type of job interview is a case interview in which the applicant is presented with a question or task or challenge, and asked to resolve the situation. Candidates may be treated to a mock interview as a training exercise to prepare the respondent to handle questions in the subsequent 'real' interview. A series of interviews may be arranged, with the first interview sometimes being a short screening interview, followed by more in-depth interviews, usually by company personnel who can ultimately hire the applicant. Technology has enabled new possibilities for interviewing; for example, video telephony has enabled interviewing applicants from afar which is becoming increasingly popular.
* Psychology. Psychologists use a variety of interviewing methods and techniques to try to understand and help their patients. In a psychiatric interview, a psychiatrist or psychologist or nurse asks a battery of questions to complete what is called a psychiatric assessment. Sometimes two people are interviewed by an interviewer, with one format being called couple interviews. Criminologists and detectives sometimes use cognitive interviews on eyewitnesses and victims to try to ascertain what can be recalled specifically from a crime scene, hopefully before the specific memories begin to fade in the mind.
* Marketing and Academic. In marketing research and academic research, interviews are used in a wide variety of ways as a method to do extensive personality tests. Interviews are the most used form of data collection in qualitative research. Interviews are used in marketing research as a tool that a firm may utilize to gain an understanding of how consumers think, or as a tool in the form of cognitive interviewing (or cognitive pretesting) for improving questionnaire design. Consumer research firms sometimes use computer-assisted telephone interviewing to randomly dial phone numbers to conduct highly structured telephone interviews, with scripted questions and responses entered directly into the computer.
* Journalism and other media. Typically, reporters covering a story in journalism conduct interviews over the phone and in person to gain information for subsequent publication. Reporters also interview government officials and political candidates for broadcast. In a talk show, a radio or television host interviews one or more people, with the topic usually chosen by the host, sometimes for entertainment, sometimes for informational purposes. Such interviews are often recorded.
* Other situations. Sometimes college representatives or alumni conduct college interviews with prospective students as a way of assessing a student's suitability while offering the student a chance to learn more about a college. Some services specialize in coaching people for interviews. Embassy officials may conduct interviews with applicants for student visas before approving their visa applications. Interviewing in legal contexts is often called interrogation. Debriefing is another kind of interview.
Details
Personality tests provide measures of such characteristics as feelings and emotional states, preoccupations, motivations, attitudes, and approaches to interpersonal relations. There is a diversity of approaches to personality assessment, and controversy surrounds many aspects of the widely used methods and techniques. These include such assessments as the interview, rating scales, self-reports, personality inventories, projective techniques, and behavioral observation.
The interview
In an interview the individual under assessment must be given considerable latitude in “telling his story.” Interviews have both verbal and nonverbal (e.g., gestural) components. The aim of the interview is to gather information, and the adequacy of the data gathered depends in large part on the questions asked by the interviewer. In an employment interview the focus of the interviewer is generally on the job candidate’s work experiences, general and specific attitudes, and occupational goals. In a diagnostic medical or psychiatric interview considerable attention would be paid to the patient’s physical health and to any symptoms of behavioral disorder that may have occurred over the years.
Two broad types of interview may be delineated. In the interview designed for use in research, face-to-face contact between an interviewer and interviewee is directed toward eliciting information that may be relevant to particular practical applications under general study or to those personality theories (or hypotheses) being investigated. Another type, the clinical interview, is focused on assessing the status of a particular individual (e.g., a psychiatric patient); such an interview is action-oriented (i.e., it may indicate appropriate treatment). Both research and clinical interviews frequently may be conducted to obtain an individual’s life history and biographical information (e.g., identifying facts, family relationships), but they differ in the uses to which the information is put.
Although it is not feasible to quantify all of the events occurring in an interview, personality researchers have devised ways of categorizing many aspects of the content of what a person has said. In this approach, called content analysis, the particular categories used depend upon the researchers’ interests and ingenuity, but the method of content analysis is quite general and involves the construction of a system of categories that, it is hoped, can be used reliably by an analyst or scorer. The categories may be straightforward (e.g., the number of words uttered by the interviewee during designated time periods), or they may rest on inferences (e.g., the degree of personal unhappiness the interviewee appears to express). The value of content analysis is that it provides the possibility of using frequencies of uttered response to describe verbal behaviour and defines behavioral variables for more-or-less precise study in experimental research. Content analysis has been used, for example, to gauge changes in attitude as they occur within a person with the passage of time. Changes in the frequency of hostile reference a neurotic makes toward his parents during a sequence of psychotherapeutic interviews, for example, may be detected and assessed, as may the changing self-evaluations of psychiatric hospital inmates in relation to the length of their hospitalization.
Sources of erroneous conclusions that may be drawn from face-to-face encounters stem from the complexity of the interview situation, the attitudes, fears, and expectations of the interviewee, and the interviewer’s manner and training. Research has been conducted to identify, control, and, if possible, eliminate these sources of interview invalidity and unreliability. By conducting more than one interview with the same interviewee and by using more than one interviewer to evaluate the subject’s behaviour, light can be shed on the reliability of the information derived and may reveal differences in influence among individual interviewers. Standardization of interview format tends to increase the reliability of the information gathered; for example, all interviewers may use the same set of questions. Such standardization, however, may restrict the scope of information elicited, and even a perfectly reliable (consistent) interview technique can lead to incorrect inferences.
Rating scales
The rating scale is one of the oldest and most versatile of assessment techniques. Rating scales present users with an item and ask them to select from a number of choices. The rating scale is similar in some respects to a multiple choice test, but its options represent degrees of a particular characteristic.
Rating scales are used by observers and also by individuals for self-reporting (see below Self-report tests). They permit convenient characterization of other people and their behaviour. Some observations do not lend themselves to quantification as readily as do simple counts of motor behaviour (such as the number of times a worker leaves his lathe to go to the restroom). It is difficult, for example, to quantify how charming an office receptionist is. In such cases, one may fall back on relatively subjective judgments, inferences, and relatively imprecise estimates, as in deciding how disrespectful a child is. The rating scale is one approach to securing such judgments. Rating scales present an observer with scalar dimensions along which those who are observed are to be placed. A teacher, for example, might be asked to rate students on the degree to which the behaviour of each reflects leadership capacity, shyness, or creativity. Peers might rate each other along dimensions such as friendliness, trustworthiness, and social skills. Several standardized, printed rating scales are available for describing the behaviour of psychiatric hospital patients. Relatively objective rating scales have also been devised for use with other groups.
A number of requirements should be met to maximize the usefulness of rating scales. One is that they be reliable: the ratings of the same person by different observers should be consistent. Other requirements are reduction of sources of inaccuracy in personality measurement; the so-called halo effect results in an observer’s rating someone favourably on a specific characteristic because the observer has a generally favourable reaction to the person being rated. One’s tendency to say only nice things about others or one’s proneness to think of all people as average (to use the midrange of scales) represents other methodological problems that arise when rating scales are used.
Self-report tests
The success that attended the use of convenient intelligence tests in providing reliable, quantitative (numerical) indexes of individual ability has stimulated interest in the possibility of devising similar tests for measuring personality. Procedures now available vary in the degree to which they achieve score reliability and convenience. These desirable attributes can be partly achieved by restricting in designated ways the kinds of responses a subject is free to make. Self-report instruments follow this strategy. For example, a test that restricts the subject to true-false answers is likely to be convenient to give and easy to score. So-called personality inventories (see below) tend to have these characteristics, in that they are relatively restrictive, can be scored objectively, and are convenient to administer. Other techniques (such as inkblot tests) for evaluating personality possess these characteristics to a lesser degree.
Self-report personality tests are used in clinical settings in making diagnoses, in deciding whether treatment is required, and in planning the treatment to be used. A second major use is as an aid in selecting employees, and a third is in psychological research. An example of the latter case would be where scores on a measure of test anxiety—that is, the feeling of tenseness and worry that people experience before an exam—might be used to divide people into groups according to how upset they get while taking exams. Researchers have investigated whether the more test-anxious students behave differently than the less anxious ones in an experimental situation.
Personality inventories
Among the most common of self-report tests are personality inventories. Their origins lie in the early history of personality measurement, when most tests were constructed on the basis of so-called face validity; that is, they simply appeared to be valid. Items were included simply because, in the fallible judgment of the person who constructed or devised the test, they were indicative of certain personality attributes. In other words, face validity need not be defined by careful, quantitative study; rather, it typically reflects one’s more-or-less imprecise, possibly erroneous, impressions. Personal judgment, even that of an expert, is no guarantee that a particular collection of test items will prove to be reliable and meaningful in actual practice.
A widely used early self-report inventory, the so-called Woodworth Personal Data Sheet, was developed during World War I to detect soldiers who were emotionally unfit for combat. Among its ostensibly face-valid items were these: Does the sight of blood make you sick or dizzy? Are you happy most of the time? Do you sometimes wish you had never been born? Recruits who answered these kinds of questions in a way that could be taken to mean that they suffered psychiatric disturbance were detained for further questioning and evaluation. Clearly, however, symptoms revealed by such answers are exhibited by many people who are relatively free of emotional disorder.
Rather than testing general knowledge or specific skills, personality inventories ask people questions about themselves. These questions may take a variety of forms. When taking such a test, the subject might have to decide whether each of a series of statements is accurate as a self-description or respond to a series of true-false questions about personal beliefs.
Several inventories require that each of a series of statements be placed on a rating scale in terms of the frequency or adequacy with which the statements are judged by the individual to reflect his tendencies and attitudes. Regardless of the way in which the subject responds, most inventories yield several scores, each intended to identify a distinctive aspect of personality.
One of these, the Minnesota Multiphasic Personality Inventory (MMPI), is probably the personality inventory in widest use in the English-speaking world. Also available in other languages, it consists in one version of 550 items (e.g., “I like tall women”) to which subjects are to respond “true,” “false,” or “cannot say.” Work on this inventory began in the 1930s, when its construction was motivated by the need for a practical, economical means of describing and predicting the behaviour of psychiatric patients. In its development efforts were made to achieve convenience in administration and scoring and to overcome many of the known defects of earlier personality inventories. Varied types of items were included and emphasis was placed on making these printed statements (presented either on small cards or in a booklet) intelligible even to persons with limited reading ability.
Most earlier inventories lacked subtlety; many people were able to fake or bias their answers since the items presented were easily seen to reflect gross disturbances; indeed, in many of these inventories maladaptive tendencies would be reflected in either all true or all false answers. Perhaps the most significant methodological advance to be found in the MMPI was the attempt on the part of its developers to measure tendencies to respond, rather than actual behaviour, and to rely but little on assumptions of face validity. The true-false item “I hear strange voices all the time” has face validity for most people in that to answer “true” to it seems to provide a strong indication of abnormal hallucinatory experiences. But some psychiatric patients who “hear strange voices” can still appreciate the socially undesirable implications of a “true” answer and may therefore try to conceal their abnormality by answering “false.” A major difficulty in placing great reliance on face validity in test construction is that the subject may be as aware of the significance of certain responses as is the test constructor and thus may be able to mislead the tester. Nevertheless, the person who hears strange voices and yet answers the item “false” clearly is responding to something—the answer still is a reflection of personality, even though it may not be the aspect of personality to which the item seems to refer; thus, careful study of responses beyond their mere face validity often proves to be profitable.
Much study has been given to the ways in which response sets and test-taking attitudes influence behaviour on the MMPI and other personality measures. The response set called acquiescence, for example, refers to one’s tendency to respond with “true” or “yes” answers to questionnaire items regardless of what the item content is. It is conceivable that two people might be quite similar in all respects except for their tendency toward acquiescence. This difference in response set can lead to misleadingly different scores on personality tests. One person might be a “yea-sayer” (someone who tends to answer true to test items); another might be a “nay-sayer”; a third individual might not have a pronounced acquiescence tendency in either direction.
Acquiescence is not the only response set; there are other test-taking attitudes that are capable of influencing personality profiles. One of these, already suggested by the example of the person who hears strange voices, is social desirability. A person who has convulsions might say “false” to the item “I have convulsions” because he believes that others will think less of him if they know he has convulsions. The intrusive potentially deceiving effects of the subjects’ response sets and test-taking attitudes on scores derived from personality measures can sometimes be circumvented by varying the content and wording of test items. Nevertheless, users of questionnaires have not yet completely solved problems of bias such as those arising from response sets. Indeed, many of these problems first received widespread attention in research on the MMPI, and research on this and similar inventories has significantly advanced understanding of the whole discipline of personality testing.
Attributes of the MMPI
The MMPI as originally published consists of nine clinical scales (or sets of items), each scale having been found in practice to discriminate a particular clinical group, such as people suffering from schizophrenia, depression, or paranoia (see mental disorder). Each of these scales (or others produced later) was developed by determining patterns of response to the inventory that were observed to be distinctive of groups of individuals who had been psychiatrically classified by other means (e.g., by long-term observation). The responses of apparently normal subjects were compared with those of hospital patients with a particular psychiatric diagnosis—for example, with symptoms of schizophrenia. Items to which the greatest percentage of “normals” gave answers that differed from those more typically given by patients came to constitute each clinical scale.
In addition to the nine clinical scales and many specially developed scales, there are four so-called control scales on the inventory. One of these is simply the number of items placed by the subject in the “cannot say” category. The L (or lie) scale was devised to measure the tendency of the test taker to attribute socially desirable attributes to himself. In response to “I get angry sometimes” he should tend to mark false; extreme L scorers in the other direction appear to be too good, too virtuous. Another so-called F scale was included to provide a reflection of the subjects’ carelessness and confusion in taking the inventory (e.g., “Everything tastes the same” tends to be answered true by careless or confused people). More subtle than either the L or F scales is what is called the K scale. Its construction was based on the observation that some persons tend to exaggerate their symptoms because of excessive openness and frankness and may obtain high scores on the clinical scales; others may exhibit unusually low scores because of defensiveness. On the K-scale item “I think nearly anyone would tell a lie to keep out of trouble,” the defensive person is apt to answer false, giving the same response to “I certainly feel useless at times.” The K scale was designed to reduce these biasing factors; by weighting clinical-scale scores with K scores, the distorting effect of test-taking defensiveness may be reduced.
In general, it has been found that the greater the number and magnitude of one’s unusually high scores on the MMPI, the more likely it is that one is in need of psychiatric attention. Most professionals who use the device refuse to make assumptions about the factualness of the subject’s answers and about his personal interpretations of the meanings of the items. Their approach does not depend heavily on theoretical predilections and hypotheses. For this reason the inventory has proved particularly popular with those who have strong doubts about the eventual validity that many theoretical formulations will show in connection with personality measurement after they have been tested through painstaking research. The MMPI also appeals to those who demand firm experimental evidence that any personality assessment method can make valid discriminations among individuals.
In recent years there has been growing interest in actuarial personality description—that is, in personality description based on traits shared in common by groups of people. Actuarial description studies yield rules by which persons may be classified according to their personal attributes as revealed by their behaviour (on tests, for example). Computer programs are now available for diagnosing such disorders as hysteria, schizophrenia, and paranoia on the basis of typical group profiles of MMPI responses. Computerized methods for integrating large amounts of personal data are not limited to this inventory and are applicable to other inventories, personality tests (e.g., inkblots), and life-history information. Computerized classification of MMPI profiles, however, has been explored most intensively.
Comparison of the MMPI and CPI
The MMPI has been considered in some detail here because of its wide usage and because it illustrates a number of important problems confronting those who attempt to assess personality characteristics. Many other omnibus personality inventories are also used in applied settings and in research. The California Psychological Inventory (CPI), for example, is keyed for several personality variables that include sociability, self-control, flexibility, and tolerance. Unlike the MMPI, it was developed specifically for use with “normal” groups of people. Whereas the judgments of experts (usually psychiatric workers) were used in categorizing subjects given the MMPI during the early item-writing phase of its development, nominations by peers (such as respondents or friends) of the subjects were relied upon in work with the CPI. Its technical development has been evaluated by test authorities to be of high order, in part because its developers profited from lessons learned in the construction and use of the MMPI. It also provides measures of response sets and has been subjected to considerable research study.
From time to time, most personality inventories are revised for a variety of reasons, including the need to take account of cultural and social changes and to improve them. For example, a revision of the CPI was published in 1987. In the revision, the inventory itself was modified to improve clarity, update content, and delete items that might be objectionable to some respondents. Because the item pool remained largely unchanged, data from the original samples were used in computing norms and in evaluating reliability and validity for new scales and new composite scores. The descriptions of high and low scorers on each scale have been refined and sharpened, and correlations of scale scores with other personality tests have been reported.
Other self-report techniques
Beyond personality inventories, there are other self-report approaches to personality measurement available for research and applied purposes. Mention was made earlier of the use of rating scales. The rating-scale technique permits quantification of an individual’s reactions to himself, to others, and, in fact, to any object or concept in terms of a standard set of semantic (word) polarities such as “hot-cold” or “good-bad.” It is a general method for assessing the meanings of these semantic concepts to individuals.
Another method of self-report called the Q-sort is devised for problems similar to those for which rating scales are used. In a Q-sort a person is given a set of sentences, phrases, or words (usually presented individually on cards) and is asked to use them to describe himself (as he thinks he is or as he would like to be) or someone else. This description is carried out by having the subject sort the items on the cards in terms of their degree of relevance so that they can be distributed along what amounts to a rating scale. Examples of descriptive items that might be included in a Q-sort are “worries a lot,” “works hard,” and “is cheerful.”
Typical paper-and-pencil instruments such as personality inventories involve verbal stimuli (words) intended to call forth designated types of responses from the individual. There are clearly stated ground rules under which he makes his responses. Paper-and-pencil devices are relatively easy and economical to administer and can be scored accurately and reliably by relatively inexperienced clerical workers. They are generally regarded by professional personality evaluators as especially valuable assessment tools in screening large numbers of people, as in military or industrial personnel selection. Assessment specialists do not assume that self-reports are accurate indicators of personality traits. They are accepted, rather, as samples of behaviour for which validity in predicting one’s everyday activities or traits must be established empirically (i.e., by direct observation or experiment). Paper-and-pencil techniques have moved from their early stage of assumed (face) validity to more advanced notions in which improvements in conceptualization and methodology are clearly recognized as basic to the determination of empirical validity.
Projective techniques
One group of assessment specialists believes that the more freedom people have in picking their responses, the more meaningful the description and classification that can be obtained. Because personality inventories do not permit much freedom of choice, some researchers and clinicians prefer to use projective techniques, in which a person is shown ambiguous stimuli (such as shapes or pictures) and asked to interpret them in some way. (Such stimuli allow relative freedom in projecting one’s own interests and feelings into them, reacting in any way that seems appropriate.) Projective techniques are believed to be sensitive to unconscious dimensions of personality. Defense mechanisms, latent impulses, and anxieties have all been inferred from data gathered in projective situations.
Personality inventories and projective techniques do have some elements in common; inkblots, for example, are ambiguous, but so also are many of the statements on inventories such as the MMPI. These techniques differ in that the subject is given substantially free rein in responding to projective stimuli rather than merely answering true or false, for example. Another similarity between projective and questionnaire or inventory approaches is that all involve the use of relatively standardized testing situations.
While projective techniques are often lumped together as one general methodology, in actual practice there are several approaches to assessment from a projective point of view. Although projective techniques share the common characteristic that they permit the subject wide latitude in responding, they still may be distinguished broadly as follows: (1) associative techniques, in which the subject is asked to react to words, to inkblots, or to other stimuli with the first associated thoughts that come to mind; (2) construction techniques, in which the subject is asked to create something—for example, make up a story or draw a self-portrait; (3) completion techniques, in which the subject is asked to finish a partially developed stimulus, such as adding the last words to an incomplete sentence; (4) choice or ordering techniques, in which the subject is asked to choose from among or to give some orderly sequence to stimuli—for example, to choose from or arrange a set of pictures or inkblots; (5) expressive techniques, in which the subject is asked to use free expression in some manner, such as in finger painting.
Hidden personality defense mechanisms, latent emotional impulses, and inner anxieties all have been attributed to test takers by making theoretical inferences from data gathered as they responded in projective situations. While projective stimuli are ambiguous, they are usually administered under fairly standardized conditions. Quantitative (numerical) measures can be derived from subjects’ responses to them. These include the number of responses one makes to a series of inkblots and the number of responses to the blots in which the subject perceives what seem to him to be moving animals.
The Rorschach Inkblot Test
The Rorschach inkblots were developed by a Swiss psychiatrist, Hermann Rorschach, in an effort to reduce the time required in psychiatric diagnosis. His test consists of 10 cards, half of which are in colour and half in black and white. The test is administered by showing the subject the 10 blots one at a time; the subject’s task is to describe what he sees in the blots or what they remind him of. The subject is usually told that the inkblots are not a test of the kind he took in school and that there are no right or wrong answers.
Rorschach’s work was stimulated by his interest in the relationship between perception and personality. He held that a person’s perceptual responses to inkblots could serve as clues to basic personality tendencies. Despite Rorschach’s original claims for the validity of his test, subsequent negative research findings have led many users of projective techniques to become dubious about the role assigned the inkblots in delineating relationships between perception and personality. In recent years, emphasis has tended to shift to the analysis of nuances of the subject’s social behaviour during the test and to the content of his verbal responses to the examiner—whether, for example, he seeks to obtain the assistance of the examiner in “solving” the inkblots presented to him, sees “angry lions” or “meek lambs” in the inkblots, or is apologetic or combative about his responses.
Over the years, considerable research has been carried out on Rorschach’s inkblots; important statistical problems in analyzing data gathered with projective techniques have been identified, and researchers have continued in their largely unsuccessful efforts to overcome them. There is a vast experimental literature to suggest that the Rorschach technique lacks empirical validity. Recently, researchers have sought to put the Rorschach on a sounder psychometric (mental testing) basis. New comprehensive scoring systems have been developed, and there have been improvements in standardization and norms. These developments have injected new life into the Rorschach as a psychometric instrument.
A similar method, the Holtzman Inkblot Test, has been developed in an effort to eliminate some of the statistical problems that beset the Rorschach test. It involves the administration of a series of 45 inkblots, the subject being permitted to make only one response per card. The Holtzman has the desirable feature that it provides an alternate series of 45 additional cards for use in retesting the same person.
Research with the Rorschach and Holtzman has proceeded in a number of directions; many studies have compared psychiatric patients and other groups of special interest (delinquents, underachieving students) with ostensibly normal people. Some investigators have sought to derive indexes or predictions of future behaviour from responses to inkblots and have checked, for example, to see if anxiety and hostility (as inferred from content analyses of verbal responses) are related to favourable or unfavourable response to psychotherapy. A sizable area of exploration concerns the effects of special conditions (e.g., experimentally induced anxiety or hostility) on the inkblot perceptions reported by the subject and the content of his speech.
Thematic Apperception Test (TAT)
There are other personality assessment devices, which, like the Rorschach, are based on the idea that an individual will project something of himself into his description of an ambiguous stimulus.
The TAT, for example, presents the subject with pictures of persons engaged in a variety of activities (e.g., someone with a violin). While the pictures leave much to one’s imagination, they are more highly specific, organized visual stimuli than are inkblots. The test consists of 30 black and white pictures and one blank card (to test imagination under very limited stimulation). The cards are presented to the subject one at a time, and he is asked to make up a story that describes each picture and that indicates the events that led to the scene and the events that will grow out of it. He is also asked to describe the thoughts and feelings of the persons in his story.
Although some content-analysis scoring systems have been developed for the TAT, attempts to score it in a standardized quantitative fashion tend to be limited to research and have been fewer than has been the case for the Rorschach. This is especially the state of affairs in applied settings in which the test is often used as a basis for conducting a kind of clinical interview; the pictures are used to elicit a sample of verbal behaviour on the basis of which inferences are drawn by the clinician.
In one popular approach, interpretation of a TAT story usually begins with an effort to determine who is the hero (i.e., to identify the character with whom the subject seems to have identified himself). The content of the stories is often analyzed in terms of a so-called need-press system. Needs are defined as the internal motivations of the hero. Press refers to environmental forces that may facilitate or interfere with the satisfaction of needs (e.g., in the story the hero may be physically attacked, frustrated by poverty, or suffer the effects of rumours being spread about him). In assessing the importance or strength of a particular inferred need or press for the individual who takes the test, special attention is given to signs of its pervasiveness and consistency in different stories. Analysis of the test may depend considerably on the subjective, personal characteristics of the evaluator, who usually seeks to interpret the subjects’ behaviour in the testing situation; the characteristics of his utterances; the emotional tone of the stories; the kinds of fantasies he offers; the outcomes of the stories; and the conscious and unconscious needs speculatively inferred from the stories.
Word-association techniques
The list of projective approaches to personality assessment is long, one of the most venerable being the so-called word-association test. Jung used associations to groups of related words as a basis for inferring personality traits (e.g., the inferiority “complex”). Administering a word-association test is relatively uncomplicated; a list of words is presented one at a time to the subject who is asked to respond with the first word or idea that comes to mind. Many of the stimulus words may appear to be emotionally neutral (e.g., building, first, tree); of special interest are words that tend to elicit personalized reactions (e.g., mother, hit, love). The amount of time the subject takes before beginning each response and the response itself are used in efforts to analyze a word association test. The idiosyncratic, or unusual, nature of one’s word-association responses may be gauged by comparing them to standard published tables of the specific associations given by large groups of other people.
Sentence-completion techniques
The sentence-comple-tion technique may be considered a logical extension of word-association methods. In administering a sentence-completion test, the evaluator presents the subject with a series of partial sentences that he is asked to finish in his own words (e.g., “I feel upset when . . . ”; “What burns me up is . . . ”). Users of sentence-completion methods in assessing personality typically analyze them in terms of what they judge to be recurring attitudes, conflicts, and motives reflected in them. Such analyses, like those of TAT, contain a subjective element.
Behavioral assessment
Objective observation of a subject’s behaviour is a technique that falls in the category of behavioral assessment. A variety of assessments could be considered, for example, in the case of a seven-year-old boy who, according to his teacher, is doing poorly in his schoolwork and, according to his parents, is difficult to manage at home and does not get along with other children. The following types of assessment might be considered: (1) a measure of the boy’s general intelligence, which might help explain his poor schoolwork; (2) an interview with him to provide insights into his view of his problem; (3) personality tests, which might reveal trends that are related to his inadequate social relationships; (4) observations of his activities and response patterns in school; (5) observations of his behaviour in a specially created situation, such as a playroom with many interesting toys and games; (6) an interview with his parents, since the boy’s poor behaviour in school may by symptomatic of problems at home; and (7) direct observation of his behaviour at home.
Making all of these assessments would be a major undertaking. Because of the variety of data that are potentially available, the assessor must decide which types of information are most feasible and desirable under a given set of circumstances. In most cases, the clinician is interested in both subjective and objective information. Subjective information includes what clients think about, the emotions they experience, and their worries and preoccupations. Interviews, personality inventories, and projective techniques provide indications of subjective experience, although considerable clinical judgment is needed to infer what is going on within the client from test responses. Objective information includes the person’s observable behaviour and usually does not require the assessor to draw complex inferences about such topics as attitudes toward parents, unconscious wishes, and deep-seated conflicts. Such objective information is measured by behavioral assessment. It is often used to identify behavioral problems, which are then treated in some appropriate way. Behavioral observations are used to get information that cannot be obtained by other means. Examples of such observations include the frequency of a particular type of response, such as physical attacks on others or observations by ward attendants of certain behaviours of psychiatric patients. In either case, observational data must meet the same standards of reliability as data obtained by more formal measures.
The value of behavioral assessment depends on the behaviours selected for observation. For example, if the goal of assessment is to detect a tendency toward depression, the responses recorded should be those that are relevant to that tendency, such as degrees of smiling, motor activity, and talking.
A type of behavioral assessment called baseline observations is becoming increasingly popular. These are recordings of response frequencies in particular situations before any treatment or intervention has been made. They can be used in several ways. Observations might be made simply to describe a person’s response repertoire at a given time. For example, the number of aggressive responses made by children of different ages might be recorded. Such observations also provide a baseline for judging the effectiveness of behaviour modification techniques. A similar set of observations, made after behaviour modification procedures have been used, could be compared with the baseline measurement as a way of determining how well the therapy worked.
Behavioral observations can be treated in different ways. One of these is to keep track of the frequency with which people make designated responses during a given period of time (e.g., the number of times a psychiatric patient makes his own bed or the number of times a child asks for help in a novel situation). Another approach involves asking raters to support their judgments of others by citing specific behaviour (critical incidents); a shop foreman, for example, may rate a worker as depressed by citing incidents when the worker burst into tears. Critical incidents not only add validity to ordinary ratings, but they also suggest behavioral details that might be promising predictors of success on the job, response to psychiatric treatment, or level of academic achievement.
Behavioral observations are widely made in interviews and in a variety of workaday settings. Employers, supervisors, and teachers—either formally or informally—make use of behavioral observations in making decisions about people for whom they have responsibility. Unfortunately the subject may know he is being studied or evaluated and, therefore, may behave atypically (e.g., by working harder than usual or by growing tense). The observer may be a source of error by being biased in favour of or against the subject. Disinterested observers clearly are to be preferred (other things being equal) for research and clinical purposes. The greater the care taken to control such contributions to error, the greater the likelihood that observations will prove to be reliable.
Cognitive assessment
The types of thoughts experienced by individuals are reflective of their personalities. Just as it is important to know what people do and how their behaviour affects others, it is also necessary to assess the thoughts that may lie behind the behaviour. Cognitive assessment provides information about thoughts that precede, accompany, and follow maladaptive behaviour. It also provides information about the effects of procedures that are intended to modify both how subjects think about a problem and how they behave.
Cognitive assessment can be carried out in a variety of ways. For example, questionnaires have been developed to sample people’s thoughts after an upsetting event. Beepers (electronic pagers) have been used to signal subjects to record their thoughts at certain times of the day. There are also questionnaires to assess the directions people give themselves while working on a task and their theories about why things happen as they do.
The assessment of thoughts and ideas is a relatively new development. It has received impetus from the growing evidence that thought processes and the content of thoughts are related to emotions and behaviour. Cognitive assessment provides information about adaptive and maladaptive aspects of people’s thoughts and the role their thoughts play in the processes of planning, making decisions, and interpreting reality.
Bodily assessment
Bodily responses may reveal a person’s feelings and motivations, and clinicians pay particular attention to these nonverbal messages. Bodily functions may also reflect motivations and concerns, and some clinicians also pay attention to these. Sophisticated devices have been developed to measure such physiological changes as pupil dilation, blood pressure, and electrical skin responses under specific conditions. These changes are related to periodic ratings of mood and to other physiological states that provide measures of stability and change within the individual. Technological advances are making it possible to monitor an individual’s physiological state on a continuous basis. Sweat, heartbeat, blood volume, substances in the bloodstream, and blood pressure can all be recorded and correlated with the presence or absence of certain psychological conditions such as stress.
Personal facts
One type of information that is sometimes overlooked because of its very simplicity consists of the subject’s life history and present status. Much of this information may be gathered through direct interviews with a subject or with an informant through questionnaires and through searches of records and archives. The information might also be gathered by examining the subject’s personal documents (e.g., letters, autobiographies) and medical, educational, or psychiatric case histories. The information might concern the individual’s social and occupational history, his cultural background, his present economic status, and his past and present physical characteristics. Life-history data can provide clues to the precursors and correlates of present behaviour. This information may help the investigator avoid needlessly speculative or complex hypotheses about the causation of personality traits when simple explanations might be superior. Failure on the part of a personality evaluator to be aware of the fact that someone had spent two years during World War II in a concentration camp could result in misleading inferences and conjectures about the subject’s present behaviour.
Reliability and validity of assessment methods
Assessment, whether it is carried out with interviews, behavioral observations, physiological measures, or tests, is intended to permit the evaluator to make meaningful, valid, and reliable statements about individuals. What makes John Doe tick? What makes Mary Doe the unique individual that she is? Whether these questions can be answered depends upon the reliability and validity of the assessment methods used. The fact that a test is intended to measure a particular attribute is in no way a guarantee that it really accomplishes this goal. Assessment techniques must themselves be assessed.
Evaluation techniques
Personality instruments measure samples of behaviour. Their evaluation involves primarily the determination of reliability and validity. Reliability often refers to consistency of scores obtained by the same persons when retested. Validity provides a check on how well the test fulfills its function. The determination of validity usually requires independent, external criteria of whatever the test is designed to measure. An objective of research in personality measurement is to delineate the conditions under which the methods do or do not make trustworthy descriptive and predictive contributions. One approach to this problem is to compare groups of people known through careful observation to differ in a particular way. It is helpful to consider, for example, whether the MMPI or TAT discriminates significantly between those who show progress in psychotherapy and those who do not, whether they distinguish between law violators of record and apparent nonviolators. Experimental investigations that systematically vary the conditions under which subjects perform also make contributions.
Although much progress has been made in efforts to measure personality, all available instruments and methods have defects and limitations that must be borne in mind when using them; responses to tests or interview questions, for example, often are easily controlled or manipulated by the subject and thus are readily “fakeable.” Some tests, while useful as group screening devices, exhibit only limited predictive value in individual cases, yielding frequent (sometimes tragic) errors. These caveats are especially poignant when significant decisions about people are made on the basis of their personality measures. Institutionalization or discharge, and hiring or firing, are weighty personal matters and can wreak great injustice when based on faulty assessment. In addition, many personality assessment techniques require the probing of private areas of the individual’s thought and action. Those who seek to measure personality for descriptive and predictive reasons must concern themselves with the ethical and legal implications of their work.
A major methodological stumbling block in the way of establishing the validity of any method of personality measurement is that there always is an element of subjective judgment in selecting or formulating criteria against which measures may be validated. This is not so serious a problem when popular, socially valued, fairly obvious criteria are available that permit ready comparisons between such groups as convicted criminals and ostensible noncriminals, or psychiatric hospital patients and noninstitutionalized individuals. Many personality characteristics, however, cannot be validated in such directly observable ways (e.g., inner, private experiences such as anxiety or depression). When such straightforward empirical validation of an untested measure hopefully designed to measure any personality attribute is not possible, efforts at establishing a less impressive kind of validity (so-called construct validity) may be pursued. A construct is a theoretical statement concerning some underlying, unobservable aspect of an individual’s characteristics or of his internal state. (“Intelligence,” for example, is a construct; one cannot hold “it” in one’s hand, or weigh “it,” or put “it” in a bag, or even look at “it.”) Constructs thus refer to private events inferred or imagined to contribute to the shaping of specific public events (observed behaviour). The explanatory value of any construct has been considered by some theorists to represent its validity. Construct validity, therefore, refers to evidence that endorses the usefulness of a theoretical conception of personality. A test designed to measure an unobservable construct (such as “intelligence” or “need to achieve”) is said to accrue construct validity if it usefully predicts the kinds of empirical criteria one would expect it to—e.g., achievement in academic subjects.
The degree to which a measure of personality is empirically related to or predictive of any aspect of behaviour observed independently of that measure contributes to its validity in general. A most desirable step in establishing the usefulness of a measure is called cross-validation. The mere fact that one research study yields positive evidence of validity is no guarantee that the measure will work as well the next time; indeed, often it does not. It is thus important to conduct additional, cross-validation studies to establish the stability of the results obtained in the first investigation. Failure to cross-validate is viewed by most testing authorities as a serious omission in the validation process. Evidence for the validity of a full test should not be sought from the same sample of people that was used for the initial selection of individual test items. Clearly this will tend to exaggerate the effect of traits that are unique to that particular sample of people and can lead to spuriously high (unrealistic) estimates of validity that will not be borne out when other people are studied. Cross-validation studies permit assessment of the amount of “shrinkage” in empirical effectiveness when a new sample of subjects is employed. When evidence of validity holds up under cross-validation, confidence in the general usefulness of test norms and research findings is enhanced. Establishment of reliability, validity, and cross-validation are major steps in determining the usefulness of any psychological test (including personality measures).
Clinical versus statistical prediction
Another measure of assessment research has to do with the role of the assessor himself as an evaluator and predictor of the behaviour of others. In most applied settings he subjectively (even intuitively) weighs, evaluates, and interprets the various assessment data that are available. How successful he is in carrying out his interpretive task is critical, as is knowledge of the kinds of conditions under which he is effective in processing such diverse data as impressions gathered in an interview, test scores, and life-history data. The typical clinician usually does not use a statistical formula that weighs and combines test scores and other data at his disposal. Rather, he integrates the data using impressions and hunches based on his past clinical experience and on his understanding of psychological theory and research. The result of this interpretive process usually includes some form of personality description of the person under study and specific predictions or advice for that person.
The degree of success an assessor has when he responds to the diverse information that may be available about a particular person is the subject of research that has been carried out on the issue of clinical versus statistical prediction. It is reasonable to ask whether a clinician will do as good a job in predicting behaviour as does a statistical formula or “cookbook”—i.e., a manual that provides the empirical, statistically predictive aspects of test responses or scores based on the study of large numbers of people.
An example would be a book or table of typical intelligence test norms (typical scores) used to predict how well children perform in school. Another book might offer specific personality diagnoses (e.g., neurotic or psychotic) based on scores such as those yielded by the different scales of the MMPI. Many issues must be settled before the deceptively simple question of clinical versus statistical prediction can be answered definitively.
When statistical prediction formulas (well-supported by research) are available for combining clinical information, however, experimental evidence clearly indicates that they will be more valid and less time-consuming than will a clinician (who may be subject to human error in trying to simultaneously consider and weigh all of the factors in a given case). The clinician’s chief contributions to diagnosis and prediction are in situations for which satisfactory formulas and quantified information (e.g., test scores) are not available. A clinician’s work is especially important when evaluations are required for rare and idiosyncratic personality characteristics that have escaped rigorous, systematic empirical study. The greatest confidence results when both statistical and subjective clinical methods simultaneously converge (agree) in the solution of specific clinical problems.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2266 2024-08-22 00:04:27
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2268) Caster
Gist
Essentially, a caster is a wheeled device that is mounted to the bottom of each chair leg and allows the chair to easily move and roll. The basic components of any caster include the mount, stem and wheel. There may be additional parts depending on the type of caster and its intended use.
Caster causes a wheel to align with the direction of travel, and can be accomplished either by caster displacement or caster angle. Caster displacement moves the steering axis ahead of the axis of wheel rotation, as with the front wheels of a shopping cart. Caster angle moves the steering axis from vertical.
Summary
Casters are useful for many different tasks, but no one caster is the best choice for all applications. Many things come into consideration such as the floor type, environmental conditions, load capacities, and even mounting preference. In many of these considerations, you will want to think about what the right caster material is for your unique job. There can be a lot to think about and consider, but the knowledgeable and dedicated team at Douglas Equipment has the know how to help you make the right decision.
What Type of Wheel Material Do You Need?
Casters need wheels, and the choice of wheel material is one of the biggest decisions when picking the right caster for the task at hand.
There are many different wheel materials to choose from, and some suppliers have wheel materials specially designed for their products that are not available anywhere else. With this wide variety, it is easy to find a caster wheel material to satisfy any requirements you have. Here are a few of the most common types of wheel material available, including some information on their properties:
* Metal: With the highest capacity and tensile strength, these wheels are popular for high heat applications. For heavy applications metal wheels, including steel and cast iron, are one of the most popular options. They provide easy rolling, but do not offer floor protection on soft flooring. Load capacities can be very high with these wheels.
* Rubber: Another very common material, these long wearing wheels are widely used on industrial equipment and can be molded onto iron, aluminum or plastic centres. This application is called Mold-on rubber and provides the soft tread of rubber with the hard backing of the wheel centre.
* Polyurethane: Carrying higher loads than rubber, and also outlasting it, they offer protection for your floor and quiet operation. Polyurethane is liquid cast onto cast iron, aluminum or forged steel centres.
* Nylon/Plastic: For easy rolling, chemical resistance and high capacity these casters can’t be beat. The plastic composition allows these to be used where other wheel materials would be worn away by harsh chemicals. They include Nylon, Phenolic or Polyolefin materials and can have very high load capacities.
* Pneumatic/Solid/Semi: These wheels work well on rough and uneven surfaces and provide the best cushioning in these terrains. Often offering larger wheel diameters for easier, rolling these are the preferred wheel type of outdoor applications on soft surfaces such as grass. They turn quietly and protect softer floors and outdoor surfaces.
Details
A caster (or castor) is an undriven wheel that is designed to be attached to the bottom of a larger object (the "vehicle") to enable that object to be moved.
Casters are used in numerous applications, including shopping carts, office chairs, toy wagons, hospital beds, and material handling equipment. High capacity, heavy duty casters are used in many industrial applications, such as platform trucks, carts, assemblies, and tow lines in plants.
Types
Casters may be fixed to roll along a straight line path, or mounted on a pivot or pintle such that the wheel will automatically align itself to the direction of travel.
Rigid casters
A basic, rigid caster consists of a wheel mounted to a stationary fork. The orientation of the fork, which is fixed relative to the vehicle, is determined when the caster is mounted to the vehicle. An example of this is the wheels found at the rear of a shopping cart in North America. Rigid casters tend to restrict vehicle motion so that the vehicle travels along a straight line.
Swivel casters
Like the simpler rigid caster, a swivel caster incorporates a wheel mounted to a fork, but an additional swivel joint above the fork allows the fork to freely rotate about 360°, thus enabling the wheel to roll in any direction. This makes it possible to easily move the vehicle in any direction without changing its orientation. Swivel casters are sometimes attached to handles so that an operator can manually set their orientation. The improved swivel caster was invented in 1920 by Seibert Chesnutt, US Patent 1341630, which was easily manufactured by stamping, and incorporated ball bearings for longer life. Basic swivel casters were in evidence in Charles Darwin's famous "office chair" as early as the 1840s.
Additionally, a swivel caster typically must include a small amount of offset distance between the center axis of the vertical shaft and the center axis of the caster wheel. When the caster is moved and the wheel is not facing the correct direction, the offset will cause the wheel assembly to rotate around the axis of the vertical shaft to follow behind the direction of movement. If there is no offset, the wheel will not rotate if not facing the correct direction, either preventing motion or dragging across the ground.
When in motion along a straight line, a swivel caster will tend to automatically align to, and rotate parallel to the direction of travel. This can be seen on a shopping cart when the front casters align parallel to the rear casters when traveling down an aisle. A consequence of this is that the vehicle naturally tends to travel in a straight direction. Precise steering is not required because the casters tend to maintain straight motion. This is also true during vehicle turns. The caster rotates perpendicular to the turning radius and provides a smooth turn. This can be seen on a shopping cart as the front wheels rotate at different velocities, with different turning radius depending on how tight a turn is made.
The angle of, and distance between the wheel axles and swivel joint can be adjusted for different types of caster performance.
Industrial casters
Industrial casters are heavy duty casters that are designed to carry heavy loads, in some cases up to thirty thousand pounds. An Industrial caster may have either a swivel or rigid caster design. Industrial casters typically have a flat top plate that has four bolt holes to ensure a sturdy connection between the top plate and the load. They are used in a variety of applications including dolly carts, assembly turntables, heavy duty storage racks, holding bins, tow lines, maintenance equipment, and material handling mechanisms.
In early manufacturing, industrial caster bodies were typically fabricated from three separate, stamped metal parts, which were welded to the top plate. Today, many industrial caster bodies are made by laser cutting the body from a single metal blank and then using a press brake to shape the legs to the required ninety degree angle, thus producing a mechanically stronger device.
Various factors affect industrial caster performance. For example, larger wheel diameters and widths provide higher weight capacity by distributing the load's weight across a larger wheel surface area. Also, harder wheel materials (e.g., cast iron, high profile polyurethane) are less sensitive to and tend to not track dirt and debris on floors.
Braking and locking casters
Common inexpensive casters may include a brake feature, which prevents the wheel from turning. This is commonly achieved using a lever that presses a brake cam against the wheel. However a swivel caster is still able to move around slightly, in a small circle rotating around offset distance between the vertical shaft and the center of the locked wheel.
A more complex type of swivel caster, sometimes called a total lock caster, has an additional rotational lock on the vertical shaft so that neither shaft swiveling nor wheel rotation can occur, thus providing very rigid support. It is possible to use these two locks together or separately. If the vertical shaft is locked but the wheel can still turn, the caster becomes a directional caster, but one which may be locked to roll in one direction along any horizontal axis.
In some cases it is useful to be able to brake or lock all casters at the same time, without having to walk around to individually engage a mechanism on each one. This may be accomplished using a central lock mechanism engaged by a rigid ring encircling each swivel caster, slightly above the wheel, that lowers and presses down on the wheel, preventing both wheel and swivel rotation. An alternative method is the central lock caster, which has a rotating cam in the center of each vertical caster shaft, leading down to a braking mechanism in the bottom of each caster.
Kingpinless casters
A Kingpinless caster has an inner raceway, an outer raceway which is attached to the vehicle, and ball bearings between the raceways. This mechanism has no kingpin, hence the name kingpinless. The absence of a kingpin eliminates most causes of swivel caster failure[citation needed] and reduces or eliminates shimmy after use. They offer capacity and durability comparable to units having sealed precision ball or tapered bearings[citation needed], and are a practical alternative to traditional swivel casters in high-impact situations.
Caster flutter
One major disadvantage of casters is flutter. A common example of caster flutter is on a supermarket shopping cart, when one caster rapidly swings side-to-side. This oscillation, which is also known as shimmy, occurs naturally at certain speeds, and is similar to speed wobble that occurs in other wheeled vehicles. The speed at which caster flutter occurs is based on the weight borne by the caster and the distance between the wheel axle and steering axis. This distance is known as trailing distance, and increasing this distance can eliminate flutter at moderate speeds. Generally, flutter occurs at high speeds.
What makes flutter dangerous is that it can cause a vehicle to suddenly move in an unwanted direction. Flutter occurs when the caster is not in full contact with the ground and therefore its orientation is uncontrollable. As the caster regains full contact with the ground, it can be in any orientation. This can cause the vehicle to suddenly move in the direction that the caster is pointed. At slower speeds, the caster’s ability to swivel can correct the direction and can continue travel in the desired direction. But at high speeds this can be dangerous as the wheel may not be able to swivel quickly enough and the vehicle may lurch in any direction.
Electric and racing wheelchair designers are very concerned with flutter because the chair must be safe for riders. Increasing trailing distance can increase stability at higher speeds for wheelchair racing, but may create flutter at lower speeds for everyday use. Unfortunately, the more trail the caster has, the more space the caster requires to swivel. Therefore, in order to accommodate this extra swivel space, lengthening of frame or extending the footrests may be required. This tends to make the chair more cumbersome.
Caster flutter can be controlled by adding dampers or increasing the friction of the swivel joints. This can be accomplished by adding washers to the swivel joint. The friction increases as the weight on the front of the chair increases. Anytime the caster begins to flutter, it slows the chair and shifts weight to the front wheels. There are several online anti-flutter kits for retrofitting wheelchair casters in this manner. Other methods of reducing caster flutter include increasing swivel lead, using heavier grease, reducing the mass of the wheel, or increasing friction with the ground by changing materials.
Casters are also stopped completely using caster cups.
Ergonomic designs
Ergonomic casters are designed with consideration for the operating environment and the task to be performed so that any injurious effects on the operator are minimized. Long-term repetitive actions involving resisting casters can contribute to strain injuries. Improper specifications can also contribute to reduced service life of casters.
Many parameters play a role in how well the caster performs. Parameters such as tire hardness, tread width and shape, the length of the trailing offset (the 'caster') and wheel diameter all affect the effort required to start the platform moving. Harder wheels will make the caster easier to roll by reducing deformation resistance. A less inflated tire offers more deformation resistance and thus more effort is required to move the attached platform. Turning effort is affected by the amount of caster and by the wheel diameter.
Enhancements to traditional caster design include toe guards, track wipers, reinforced legs, steering tubes, swivel locks and brakes, all implemented in an effort to reduce operator injuries in the workplace.
Wheel diameter, wheel width, and tandem wheels
The diameter of a caster wheel affects how easily the caster moves over particulate, rough or irregular surfaces. Large diameter caster wheels are able to bridge gaps like that between the floor and an elevator car. However, the larger the diameter of a caster wheel, the higher the caster support arm must be. Either the base of a low-hanging object must be lifted higher above the wheels, or the casters must hang out to the sides straddling the low-hanging supported object. While rotating around the vertical shaft, swivel caster wheels sweep out a space. Larger wheels require more of this space.
Load capacity may be increased by using wider wheels with more ground contact area. However, when rotating a wide swivel caster in-place, the center part of the wheel-to-ground contact patch rotates slower than the regions further out to the sides. This difference in rotation speed across the base of the wheel contact patch causes wide wheels to resist rotation around the swivel, and this resistance increases as weight loading increases.
An alternative way to increase load capacity while limiting swivel-rotation resistance is to use multiple narrow wheels in tandem on the same wheel axis. Each wheel has a comparatively narrower ground contact patch than a single wide wheel, so there is less resistance to turning in place on the swivel.
Other related wheels
There are four main classifications of wheels:
* A standard wheel has a center rotating hub (or bearing) and a compliant material on its outer side.
* A caster is a wheel mounted to a fork, with an optional, additional offset steering joint.
* An omnidirectional wheel (Mecanum wheel, Omni wheel, or Swedish wheel) is made of a large central hub with many additional smaller wheels mounted along the perimeter such that their axes are perpendicular to the central wheel. The central wheel can rotate around its axis like traditional wheels, but the smaller wheels can also enable movement perpendicular to the central axis.
* A spherical wheel is omnidirectional and is generally a spherical ball mounted inside a restraining fixture. An example is a ball transfer unit.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2267 2024-08-22 21:12:58
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2269) Sandalwood
Gist
Sandalwood is a class of woods from trees in the genus Santalum. The woods are heavy, yellow, and fine-grained, and, unlike many other aromatic woods, they retain their fragrance for decades. Sandalwood oil is extracted from the woods.
Summary
Sandalwood, (genus Santalum), genus of about 25 species of semiparasitic plants of the family Santalaceae, especially the fragrant wood of the true, or white, sandalwood, Santalum album. The group is distributed throughout southeastern Asia, Australia, and islands of the South Pacific.
True sandalwood
A true sandalwood tree grows to a height of about 10 metres (33 feet); has leathery leaves in pairs, each opposite the other on the branch; and is partially parasitic on the roots of other tree species. Both tree and roots contain a yellow aromatic oil, called sandalwood oil, the odour of which persists for years in such articles as ornamental boxes, furniture, and fans made of the white sapwood. The oil is obtained by steam distillation of the wood and is used in perfumes, soaps, candles, incense, and folk medicines. Powdered sandalwood is used in the paste applied to make Brahman caste marks and in sachets for scenting clothes.
Sandalwood trees have been cultivated since antiquity for their yellowish heartwood, which plays a major role in many funeral ceremonies and religious rites. The trees are slow-growing, usually taking about 30 years for the heartwood to reach an economically useful thickness.
Other Species
Quandong (S. acuminatum), noted for its edible nut, and plumbush (S. lanceolatum) are both fairly common trees in Australia. Bitter quandong (S. murrayanum) is found in shrublands in southern Australia.
Several members of the genus are listed as endangered in the International Union for Conservation of Nature and Natural Resources (IUCN) Red List of Threatened Species, including Polynesian sandalwood (S. insulare), lanai sandalwood (S. freycinetianum) and ‘iliahi (S. pyrularium) of Hawaii, and yasi (S. yasi) of Fiji and Tonga. The Hawaiian S. involutum and S. macgregorii of Papua New Guinea are both critically endangered. The Chile sandalwood (S. fernandezianum) is an extinct species last documented alive in Chile in 1908. Habitat loss and overharvesting for the wood are the chief threats to these plants.
So-called red sandalwood is obtained from the reddish-coloured wood of Pterocarpus santalinus, a Southeast Asian tree of the pea family (Fabaceae). This species may have been the source of the sandalwood used in King Solomon’s Temple.
Details
Sandalwood is a class of woods from trees in the genus Santalum. The woods are heavy, yellow, and fine-grained, and, unlike many other aromatic woods, they retain their fragrance for decades. Sandalwood oil is extracted from the woods. Sandalwood is often cited as one of the most expensive woods in the world. Both the wood and the oil produce a distinctive fragrance that has been highly valued for centuries. Consequently, some species of these slow-growing trees have suffered over-harvesting in the past.
Nomenclature
The nomenclature and the taxonomy of the genus are derived from this species' historical and widespread use. Etymologically it is ultimately derived from Sanskrit Chandana (čandana), meaning "wood for burning incense" and related to candrah, "shining, glowing" and the Latin candere, to shine or glow. It arrived in English via Late Greek, Medieval Latin and Old French in the 14th or 15th century.
True sandalwoods
Sandalwoods are medium-sized hemiparasitic trees, and part of the same botanical family as European mistletoe. Sandalwood is indigenous to the tropical belt of the peninsular India, Malay Archipelago and northern Australia. The main distribution is in the drier tropical regions of India and the Indonesian islands of Timor and Sumba. It spread to other regions through the incense trade route by the vast Indian and Arab mercantile networks and the Chinese maritime trade routes until the sixteenth century CE. The sandalwood of peninsular India and Malay Archipelago supported most consumption in East Asia and West Asia during the time of the incense trade route before the commercialization of Australian sandalwood (Santalum spicatum) in sandalwood plantations in Australia and China, although sandalwood album (Santalum album) is still considered to have the best and original quality in terms of religion and alternative medicine. Santalum spicatum is marketed as the notable members of this group today by merchants because of its stable sources; others in the genus also have fragrant wood. These are found in India, Nepal, Bangladesh, Pakistan, Sri Lanka, Australia, Indonesia, Hawaii, and other Pacific Islands.
* S. album is a threatened species native to dry tropical regions of Indonesia (Java and the Lesser Sunda Islands), the Philippines, and Western Australia. It was one of the plants exploited by Austronesian arboriculture and it was introduced by Austronesian sailors to East Asia, Mainland Southeast Asia and South Asia during the ancient spice trade, becoming naturalized in South India by at least 1300 BCE. In India, the principal sandal tracts are most parts of Karnataka and adjoining districts of Maharashtra, Tamil Nadu, Kerala and Andhra Pradesh. Although sandalwood trees in India, Pakistan, and Nepal are government-owned and their harvest is controlled, many trees are illegally cut down. Sandalwood oil prices had risen to $3000 per liter by 2017.
* S. ellipticum, S. freycinetianum, and S. paniculatum, the Hawaiian sandalwood (ʻiliahi), were also used and considered high quality. These three species were exploited between 1790 and 1825 before the supply of trees ran out (a fourth species, S. haleakalae, occurs only in subalpine areas and was never exported). Although S. freycinetianum and S. paniculatum are relatively common today, they have not regained their former abundance or size, and S. ellipticum remains rare.
* S. yasi, a sandalwood from Fiji and Tonga.
* S. spicatum is used by aromatherapists and perfumers. The oil concentration differs considerably from other Santalum species. In the 1840s, sandalwood was Western Australia's biggest export earner. Oil was distilled for the first time in 1875, and by the turn of the 20th century, production of Australian sandalwood oil was intermittent. However, in the late 1990s, Western Australian sandalwood oil enjoyed a revival and by 2009 had peaked at more than 20,000 kg (44,000 lb) per year – much of which went to the fragrance industries in Europe. Although overall production has decreased, by 2011, a significant percentage of its production was heading to the chewing tobacco industry in India alongside Indian sandalwood – the chewing tobacco market being the largest market for both oils in 2012.
* Other species: Commercially, various other species, not belonging to Santalum species, are also used as sandalwood.
Unrelated plants
Various unrelated plants with scented wood and also referred to as sandalwood, but not in the true sandalwood genus:
Adenanthera pavonina – sandalwood tree, red or false red sandalwood
Baphia nitida – camwood, also known as African sandalwood
Eremophila mitchellii – sandalwood; false sandalwood (also sandalbox)
Myoporum platycarpum – sandalwood; false sandalwood
Myoporum sandwicense – false sandalwood
Osyris lanceolata – African sandalwood
Osyris tenuifolia – east African sandalwood
Pterocarpus santalinus – false red sandalwood growing in southern Indian regions
Production
Producing commercially valuable sandalwood with high levels of fragrance oils requires Indian sandalwood (S. album) trees to be a minimum of 15 years old – the yield, quality and volume are still to be clearly understood. Yield of oil tends to vary depending on the age and location of the tree; usually, the older trees yield the highest oil content and quality. India continues to produce a superior quality of Santalum Album, with FP Aromatics being the largest exporter. Australia is the largest producer of S. album, with the majority grown around Kununurra, in the far north of the state by Quintis (formerly Tropical Forestry Services), which in 2017 controlled around 80% of the world's supply of Indian sandalwood, and Santanol. India used to be the world's biggest producer, but it has been overtaken by Australia in the 21st century. Over-exploitation is partly to blame for the decline. However, ethical plantations in India are on the rise, and India is expected to increase its supply manyfold by 2030, owing to favourable weather conditions and competitive pricing.
Australian sandalwood (S. spicatum) is grown in commercial plantations throughout the wheatbelt of Western Australia, where it has been an important part of the economy since colonial times. As of 2020 WA has the largest plantation resource in the world.
Sandalwood is expensive compared to other types of woods. To maximize profit, sandalwood is harvested by removing the entire tree instead of felling at the trunk near ground level. This way wood from the stump and root, which possesses high levels of sandalwood oil, can also be processed and sold.
Australian sandalwood is mostly harvested and sold in log form, graded for heartwood content. The species is unique in that the white sapwood does not require removal before distilling the oil. The logs are either processed to distill the essential oil, or made into powders for making incense. Indian sandalwood, used mainly for oil extraction, does require removal of the sapwood prior to distillation. As of 2020, Australian Sandalwood oil sells for around US$1,500 per 1 kilogram (2.2 lb), while Indian Sandalwood oil, due to its higher alpha santalol content, is priced at about US$2,500 per kg.
Sandalwood is often cited as one of the most expensive woods in the world, along with African blackwood, pink ivory, agarwood and ebony.
Sandalwood has historically been an important tree in the development of the political economy of the Pacific. Prior to colonization in the region, the sandalwood tree was a marker of status, rank and beauty. It then became an important part of the Pacific trade during the colonial period, as it was one of the few resources the West was able to successfully trade with Chinese merchants. This western trade began to put pressure on the production of sandalwood in the region.
Tonga, a Polynesian kingdom in the Oceania region, saw a severe depletion of its sandalwood tree (locally known as “‘ahi”) due a disruption of the social hierarchy, known as “fahu”, which led to heightened local competition and eventually an over harvest. Nearly all of the sandalwood resources were depleted over the span of two years.
Tongan people have a unique social dynamic referred to as “fahu.” On the one hand, the kinship system of fahu is able to ensure biodiversity and sustainability in contemporary Tonga. But on the other hand, a principal factor in the over harvest of the ‘ahi tree was the result of the defensive actions of farmers defying fahu customs. As sandalwood became valuable in the market, lower-ranking family members began to harvest the trees without permission, encouraging many farmers to harvest their trees defensively and thus leading to over harvest.
In 2007, Mike Evans published a scholarly report on Tongan sandalwood overharvest and the socio-environmental implications of resource commodification and privatized land tenure. Evan’s concluded that “whatever the short-term ecological benefits of enforcing privatized land tenure, because private property not only fragments social ties by allowing an individual to deny others, it has the potential to fragment the regional ecology as well.”
Uses:
Fragrance
Sandalwood oil has a distinctive soft, warm, smooth, creamy, and milky precious-wood scent. Its quality and scent profile is greatly influenced by the age of the tree, location and the skill of the distiller. It imparts a long-lasting, woody base to perfumes from the oriental, woody, fougère, and chypre families, as well as a fixative to floral and citrus fragrances. When used in smaller proportions in a perfume, it acts as a fixative, enhancing the longevity of other, more volatile, materials in the composite. Sandalwood is also a key ingredient in the "floriental" (floral-ambery) fragrance family – when combined with white florals such as jasmine, ylang ylang, gardenia, plumeria, orange blossom, tuberose, lily of the valley, etc. Its also acts as a versatile base that blends well with other woody scents like patchouli and cedar.
Sandalwood oil in India is widely used in the cosmetic industry. The main source of true sandalwood, S. album, is a protected species, and demand for it cannot be met. Many species of plants are traded as "sandalwood". The genus Santalum has more than 19 species. Traders often accept oil from closely related species, as well as from unrelated plants such as West Indian sandalwood (Amyris balsamifera) in the family Rutaceae or naughty sandalwood (Myoporum sandwicense, Myoporaceae). However, most woods from these alternative sources lose their aroma within a few months or years.
Isobornyl cyclohexanol is a synthetic fragrance chemical produced as an alternative to the natural product.
Sandalwood's main components are the two isomers of santalol (about 75%). It is used in aromatherapy, in scented candles and to prepare soaps.
Idols/sculptures
Sandalwood lends itself well to carving and has thus, traditionally, been a wood of choice for statues and sculptures of Hindu gods.
Technology
Due to its low fluorescence and optimal refractive index, sandalwood oil is often employed as an immersion oil within ultraviolet and fluorescence microscopy.
Food
Aboriginal Australians eat the seed kernels, nuts, and fruit of local sandalwoods, such as the quandong (S. acuminatum). Early Europeans in Australia used quandong in cooking damper by infusing it with its leaves, and in making jams, pies, and chutneys from the fruit. In Scandinavia, pulverised bark from red sandalwood (Pterocarpus soyauxii) is used - with other tropical spices - when marinating anchovies and some types of pickled herring such as matjes, sprat, and certain types of traditional spegesild, inducing a reddish colour and slightly perfumed flavour.
Present-day chefs have begun experimenting in using the nut as a substitute for macadamia nuts or a bush food substitute for almonds, hazelnuts, and others in Southeast Asian-styled cuisine. The oil is also used as a flavour component in different food items, including candy, ice cream, baked food, puddings, alcoholic and nonalcoholic beverages, and gelatin. The flavouring is used at levels below 10 ppm, the highest possible level for use in food products being 90 ppm.
Distillation
Oil is extracted from Sandalwood through distillation. Many different methods are used, including steam distillation, water distillation, CO2 extraction, and solvent extractions. Steam distillation is the most common method used by sandalwood companies. It occurs in a four-step process, incorporating boiling, steaming, condensation, and separation. Water is heated to high temperatures (60–100 °C or 140–212 °F) and is then passed through the wood. The oil is very tightly bound within the cellular structure of the wood, but can be released by the high heat of the steam. The mixture of steam and oil is then cooled and separated so that the essential oil can be collected. This process is much longer than any other essential oil's distillation, taking 14 to 36 hours to complete, but generally produces much higher quality oil. Water, or hydro, distillation is the more traditional method of sandalwood extraction which involves soaking the wood in water and then boiling it until the oil is released. This method is not used as much anymore because of the high costs and time associated with heating large quantities of water.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2268 2024-08-23 00:10:33
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2270) Eucalyptus Oil
Gist
Today, oil from the eucalyptus tree (Eucalyptus globulus) appears in many over-the-counter cough and cold products to relieve congestion. Eucalyptus oil is also used in creams and ointments to relieve muscle and joint pain, and in some mouthwashes.
Studies suggest that eucalyptus oil and extract may help strengthen the skin's natural moisture barrier. I Like many other oils, it helps trap water in the skin, which can help prevent and relieve dryness as well as related symptoms, like flaking and irritation.
Eucalyptus is a key ingredient in some topical analgesics. These are pain relievers you apply directly to your skin, such as sprays, creams, or salves. While it's not the main painkiller, eucalyptus oil works by bringing a cold or warm sensation that takes your mind off the pain.
Summary:
Mosquito Repellent
The EPA’s list of effective, safe insect repellents is a short one, for both chemical and natural methods. A special kind of eucalyptus oil makes the cut. Oil of lemon eucalyptus (OLE) has a chemical called PMD that shoos away mosquitoes and other bugs. But don’t use it on children under 3. OLE has a different chemical makeup from lemon eucalyptus oil, although their names are similar.
Clear Stuffy Nose
Research suggests that the oil fights respiratory infections by killing bacteria, viruses, and fungi. This is why you can find it in saline nasal wash. It also causes the tiny hair-like filaments in your lungs (called cilia) that sweep out mucus and debris from your airways to move faster. This can also fight infections.
Ease Arthritis Pain
Eucalyptus is a key ingredient in some topical analgesics. These are pain relievers you apply directly to your skin, such as sprays, creams, or salves. While it’s not the main painkiller, eucalyptus oil works by bringing a cold or warm sensation that takes your mind off the pain.
Post-Surgery Painkiller
In one clinical trial, people who breathed in eucalyptus oil after knee replacement surgery felt less pain and had lower blood pressure. Researchers think this may be due to something in the oil called 1,8-cineole. It may make your sense of smell work with your nervous system to lower your blood pressure.
Calm Pre-Op Nerves
Eucalyptus oil not only can help with pain post-op, but it also may help keep you calm before surgery, too. Researchers measured the effect on anxiety of breathing in essential oils in people about to have surgery. Before their operations, they smelled different oils for 5 minutes. The 1,8-cineole in eucalyptus oil worked so well that researchers suggested it may be useful for entire procedures.
Polish Off Plaque
Wondering if herbal toothpaste works as well as the standard stuff? Possibly. One small study compared a natural toothpaste containing eucalyptus with a standard toothpaste. Researchers tested both kinds on 30 people with gingivitis (a common, mild gum disease that causes swelling and redness) and plaque buildup (the sticky film that coats your teeth when you don’t brush enough). Both toothpastes worked equally well to lessen these problems.
Chew Away Dental Problems
Brushing isn’t the only way to tap the power of eucalyptus oil for a healthy smile. Chewing gum that has it as an ingredient can take down dental culprits like plaque, gingivitis, and bleeding, too. Some dentists say chewing sugar-free gum is good for stimulating your salivary glands and keeping your mouth moist. Just remember, it’s not a replacement for brushing and flossing.
Household Grime Fighter
Eucalyptus can do more than look pretty and smell divine. The oil is handy around the house, too. It’s the active ingredient in more than 30 cleaning products approved by the EWG, a nonprofit environmental research group. In one study, it removed bacteria including E.coli from steel surfaces.
Lose Head Lice
Take this, lice. A treatment of eucalyptus and tea tree oil did twice as well in a clinical trial as the old standby, pyrethrin. Not only did it kill 100% of lice and eggs, but it did it in only one dose. Other treatments needed several. Tests on skin revealed no irritation for adults or children, too.
Run Off Rodents
Are rats scurrying just a little too close for comfort? Keep them away with a eucalyptus oil solution. Spray it regularly in places where you see them. Many of the chemicals in it -- especially 1,8-cineole -- deal a powerful punch to pests. It’s kinder to the environment than harsh chemicals, too.
Suppresses Oral Herpes
Eucalyptus oil shows promise as a defense against HSV-1, or oral herpes. In one lab study, it outperformed the standard herpes medication, acyclovir. The 1,8-cineole chemical in the oil shuts down virus particles and may block them from entering cells. In lab tests, eucalyptus oil was able to curb the spread of the virus by more than 96%.
Don’t Take It by Mouth
Though eucalyptus oil has many benefits, the undiluted form can be highly toxic if you take it by mouth. Just 2-3 milliliters can trigger dizziness, drowsiness, and loss of muscle control. Five milliliters or more can lead to nervous system shutdown and even coma. Symptoms show up between 30 minutes to 4 hours after exposure. A small number of people have had epileptic-like seizures within a few minutes of inhaling eucalyptus oil.
Details
Originally native to Australia, eucalyptus trees are now grown all over the world and used for their medicinal properties. Their healing power comes from eucalyptus oil, which is made from the tree’s oval-shaped leaves.
The leaves are dried, crushed, and distilled to release the essential oil. After the oil has been extracted, it must be diluted before it can be used as medicine. Here are nine benefits of eucalyptus oil.
1. Silence a cough
For many years, eucalyptus oil has been used to relieve coughing. Today, some over-the-counter cough medications have eucalyptus oil as one of their active ingredients. Vicks VapoRub, for example, contains about 1.2 percent eucalyptus oil along with other cough suppressant ingredients.
The popular rub is applied to the chest and throat to relieve cough symptoms from the common cold or flu.
2. Clear your chest
Are you coughing but nothing is coming up? Eucalyptus oil can not only silence a cough, it can also help you get the mucus out of your chest.
Inhaling vapor made with the essential oil can loosen mucus so that when you do cough, it’s expelled. Using a rub containing eucalyptus oil will produce the same effect.
3. Keep the bugs away
Mosquitoes and other biting insects carry diseases that can be dangerous to our health. Avoiding their bites is our best defense. DEET sprays are the most popular repellants, but they’re made with strong chemicals.
As an effective alternative for those who aren’t able to use DEET, many manufacturers make a botanical compound to repel the pests. Brands such as Repel and Off! use oil of lemon eucalyptus to keep the pests away.
4. Disinfect wounds
The Australian aborigines used eucalyptus leaves to treat wounds and prevent infection. Today the diluted oil may still be used on the skin to fight inflammation and promote healing. You can purchase creams or ointments that contain eucalyptus oil. These products may be used on minor burns or other injuries that can be treated at home.
5. Breathe easy
Respiratory conditions such as asthma and sinusitis may be helped by inhaling steam with added eucalyptus oil. The oil reacts with mucous membranes, not only reducing mucus but helping loosen it so that you can cough it up.
It’s also possible that eucalyptus blocks asthma symptoms. On the other hand, for people who are allergic to eucalyptus, it may worsen their asthma. More research is needed to determine how eucalyptus affects people with asthma.
6. Control blood sugar
Eucalyptus oil has potential as a treatment for diabetes. Although we don’t know much at this time, experts believe that it may play a role in lowering blood sugar in people with diabetes.
Researchers haven’t yet figured out how the essential oil works. However, until more is known, the scientific community recommends careful blood sugar monitoring for people using diabetes medication with eucalyptus oil.
7. Soothe cold sores
The anti-inflammatory properties of eucalyptus can ease symptoms of herpes. Applying eucalyptus oil to a cold sore may reduce pain and speed up the healing process.
You can buy over-the-counter balms and ointments for cold sores that use a blend of essential oils, including eucalyptus, as part of their active ingredient list.
8. Freshen breath
Mint isn’t the only weapon against stinky breath. Because of its antibacterial properties, eucalyptus oil can be used to fight the germs that cause unfortunate mouth odor. Some mouthwashes and toothpastes contain the essential oil as an active ingredient.
It’s possible that eucalyptus products may also help prevent plaque buildup on the teeth and gums by attacking the bacteria that cause tooth decay.
9. Ease joint pain
Research suggests that eucalyptus oil eases joint pain. In fact, many popular over-the- counter creams and ointments used to soothe pain from conditions like osteoarthritis and rheumatoid arthritis contain this essential oil.
Eucalyptus oil helps to reduce pain and inflammation associated with many conditions. It may also be helpful to people experiencing back pain or those recovering from a joint or muscle injury. Talk to your doctor about if it may be right for you.
Additional Information
Eucalyptus oil is the generic name for distilled oil from the leaf of Eucalyptus, a genus of the plant family Myrtaceae native to Australia and cultivated worldwide. Eucalyptus oil has a history of wide application, as a pharmaceutical, antiseptic, repellent, flavouring, fragrance and industrial uses. The leaves of selected Eucalyptus species are steam distilled to extract eucalyptus oil.
Types and production
Eucalyptus oils in the trade are categorized into three broad types according to their composition and main end-use: medicinal, perfumery and industrial. The most prevalent is the standard cineole-based "oil of eucalyptus", a colourless mobile liquid (yellow with age) with a penetrating, camphoraceous, woody-sweet scent.
China produces about 75% of the world trade, but most of this is derived from the cineole fractions of camphor laurel rather than being true eucalyptus oil. Significant producers of true eucalyptus include South Africa, Portugal, Spain, Brazil, Australia, Chile, and Eswatini.
Global production is dominated by Eucalyptus globulus. However, Eucalyptus kochii and Eucalyptus polybractea have the highest cineole content, ranging from 80 to 95%. The British Pharmacopoeia states that the oil must have a minimum cineole content of 70% if it is pharmaceutical grade. Rectification is used to bring lower grade oils up to the high cineole standard required. In 1991, global annual production was estimated at 3,000 tonnes for the medicinal eucalyptus oil with another 1,500 tonnes for the main perfumery oil (produced from Eucalyptus citriodora). The eucalyptus genus also produces non-cineole oils, including piperitone, phellandrene, citral, methyl cinnamate and geranyl acetate.
Uses:
Herbal medicine
Eucalyptus oil is a common ingredient in decongestant formulations. The European Medicines Agency Committee on Herbal Medicinal Products concluded that traditional medicines based on eucalyptus oil can be used for treating cough associated with the common cold, and to relieve symptoms of localized muscle pain.
Repellent and biopesticide
Cineole-based eucalyptus oil is used as an insect repellent and biopesticide. In the U.S., eucalyptus oil was first registered in 1948 as an insecticide and miticide.
Flavouring and fragrance
Eucalyptus oil is used in flavouring. Cineole-based eucalyptus oil is used as a flavouring at low levels (0.002%) in various products, including baked goods, confectionery, meat products and beverages. Eucalyptus oil has antimicrobial activity against a broad range of foodborne human pathogens and food spoilage microorganisms. Non-cineole peppermint gum, strawberry gum and lemon ironbark are also used as flavouring. Eucalyptus oil is also used as a fragrance component to impart a fresh and clean aroma in soaps, detergents, lotions, and perfumes. It is known for its pungent, intoxicating scent. Due to its cleansing properties, eucalyptus oil is found in mouthrinses to freshen breath.
Industrial
Research shows that cineole-based eucalyptus oil (5% of mixture) prevents the separation problem with ethanol and petrol fuel blends. Eucalyptus oil also has a respectable octane rating, and can be used as a fuel in its own right. However, production costs are currently too high for the oil to be economically viable as a fuel.
Phellandrene- and piperitone-based eucalyptus oils have been used in mining to separate sulfide minerals via flotation.
Cleaning
Eucalyptus oil is used in household cleaning applications. It is commonly used in commercial laundry products such as wool wash liquid. It is used as a solvent for removing grease and sticky residue.
Safety and toxicity
If consumed internally at low dosage as a flavouring component or in pharmaceutical products at the recommended rate, cineole-based 'oil of eucalyptus' is safe for adults. However, systemic toxicity can result from ingestion or topical application at higher than recommended doses. In Australia, eucalyptus oil is one of the many essential oils that have been increasingly causing cases of poisoning, mostly of children. There were 2,049 reported cases in New South Wales between 2014 and 2018, accounting for 46.4% of essential oil poisoning incidents.
The probable lethal dose of pure eucalyptus oil for an adult is in the range of 0.05 mL to 0.5 mL/per kg of body weight. Because of their high body-surface-area-to-mass ratio, children are more vulnerable to poisons absorbed transdermally. Severe poisoning has occurred in children after ingestion of 4 mL to 5 mL of eucalyptus oil.
Eucalyptus oil has also been shown to be dangerous to domestic cats, causing an unstable gait, excessive drooling, and other symptoms of ill health.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2269 2024-08-23 22:34:02
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2271) Olive Oil
Gist
Olive oil comes from the olive fruit and contains monounsaturated fatty acids. Fatty acids in olive oil seem to decrease cholesterol levels and have anti-inflammatory effects. Olive oil is commonly used in foods. As medicine, people most commonly use olive oil for heart disease, diabetes, and high blood pressure.
Moderation is key to healthy olive oil intake. The Food and Drug Administration recommends daily consumption of just 1 1/2 tablespoons of olive oil to reduce the risk of heart disease. If you are already eating a balanced diet that includes olive oil, drinking it straight won't provide any health benefits.
Summary
Olive oil is a liquid fat obtained by pressing whole olives, the fruit of Olea europaea, a traditional tree crop of the Mediterranean Basin, and extracting the oil.
It is commonly used in cooking for frying foods or as a salad dressing. It can also be found in some cosmetics, pharmaceuticals, soaps, and fuels for traditional oil lamps. It also has additional uses in some religions. The olive is one of three core food plants in Mediterranean cuisine, together with wheat and grapes. Olive trees have been grown around the Mediterranean since the 8th millennium BC.
Spain is the world's largest producer, manufacturing almost half of the world's olive oil. Other large producers are Italy, Greece, Portugal, Tunisia, Turkey and Morocco.
The composition of olive oil varies with the cultivar, altitude, time of harvest, and extraction process. It consists mainly of oleic acid (up to 83%), with smaller amounts of other fatty acids including linoleic acid (up to 21%) and palmitic acid (up to 20%). Extra virgin olive oil is required to have no more than 0.8% free acidity, and is considered to have favorable flavor characteristics.
Varieties
There are many olive cultivars, each with a particular flavor, texture, and shelf life that make them more or less suitable for different applications, such as direct human consumption on bread or in salads, indirect consumption in domestic cooking or catering, or industrial uses such as animal feed or engineering applications. During the stages of maturity, olive fruit changes colour from green to violet, and then black. Olive oil taste characteristics depend on the stage of ripeness at which olive fruits are collected.
Details
Olive oil may offer several health benefits, such as antioxidants, healthy fats, and anti-inflammatory properties, among others.
1. Olive oil is rich in healthy monounsaturated fats
Olive oil is the natural oil extracted from olives, the fruit of the olive tree.
About 13.8% of the oil is saturated fat, whereas 10.5% is polyunsaturated, such as omega-6 and omega-3 fatty acids.
However, olive oil’s predominant fatty acid is oleic acid, a monounsaturated fat that makes up 71% of the total oil content.
Studies suggest that oleic acid reduces inflammation and oxidative stress, and may even have beneficial effects on genes linked to cancer.
Monounsaturated fats are also quite resistant to high heat, making extra virgin olive oil a healthy choice for cooking.
2. Olive oil contains large amounts of antioxidants
Extra virgin olive oil contains modest amounts of vitamins.
For example, 1 tablespoon (tbsp) contains 13%Trusted Source of the Daily Value (DV) for vitamin E and 7% of the DV for vitamin K.
But olive oil is also loaded with powerful antioxidants that are biologically active. These may help reduce your risk of chronic diseases that affect your cardiovascular and central nervous system.
Antioxidants also fight inflammation and help protect blood cholesterol from oxidation — two benefits that may lower your risk of heart disease.
3. Olive oil has strong anti-inflammatory properties
Chronic inflammation is thought to be a leading driver of diseases, such as:
* cancer
* heart disease
* metabolic syndrome
* type 2 diabetes
* Alzheimer’s disease
* arthritis
* obesity
Extra-virgin olive oil may help reduce inflammation, which may be one of the main reasons for its health benefits.
The antioxidants mediate the main anti-inflammatory effects. Key among them is oleocanthal, which has been shown to work similarly to ibuprofen, a nonsteroidal anti-inflammatory drug.
Research also suggests that oleic acid, the main fatty acid in olive oil, can reduce levels of certain inflammatory markers, such as C-reactive protein (CRP).
4. Olive oil may help prevent strokes
A stroke is caused by a disturbance of blood flow to your brain, either due to a blood clot or bleeding.
It’s the second most common cause of death, according to the World Health Organization (WHO)Trusted Source.
The relationship between olive oil and stroke risk has been studied extensively, but the results are mixed.
For example, a 2014 review of studies on 841,000 people found that olive oil was the only source of monounsaturated fat associated with a reduced risk of stroke and heart disease.
However, a 2020 meta-analysis found no significant link between olive oil intake and stroke risk.
If you think you may be at risk of stroke, speak with a healthcare professional. They could recommend dietary and lifestyle changes for you.
5. Olive oil is protective against heart disease
Heart disease is the most common cause of death in the world, according to the WHO.
Observational studies conducted a few decades ago showed that heart disease is less common in Mediterranean countries.
This led to extensive research on the Mediterranean diet, which has now been shown to significantly reduce heart disease risk.
Extra virgin olive oil is one of the key ingredients in this diet, but the research on its benefits for heart disease is mixed.
For example, a 2018 review suggests it may help lower inflammation and increase HDL (good) cholesterol. The authors note it may also lower other blood lipids, but not as much as other plant oils.
On the other hand, a 2022 meta-analysis found that each additional 10 grams of olive oil consumed daily had minimal effects on blood lipids.
Olive oil has also been shown to lower blood pressure, which is one of the strongest risk factors for heart disease and premature death.
If you have heart disease, a family history of heart disease, or any other risk factor, you may want to consider including extra virgin olive oil in your diet.
6. Olive oil is not associated with weight gain and obesity
Eating excessive amounts of calories may lead to weight gain, and fats are high in calories.
However, numerous studies have linked the Mediterranean diet, rich in olive oil, with favorable effects on body weight.
A 2018 review also found that diets high in olive oil helped promote weight loss more than diets low in olive oil.
However, it’s important to note that consuming excessive amounts of any food could lead to weight gain, and olive oil is no exception.
If you’re unsure about how much olive oil to consume, speak with a registered dietitian. They could provide dietary recommendations specific to you.
7. Olive oil may fight Alzheimer’s disease
Alzheimer’s disease is one of the most common neurodegenerative conditions in the world.
One of its key features is the buildup of beta-amyloid plaques inside your brain cells, which may lead to a decline in cognition and memory loss.
A 2024 review found that olive oil may reduce the risk of developing Alzheimer’s disease and cognitive impairment. It may do this by reducing beta-amyloid plaques, neuroinflammation, and oxidative stress.
Keep in mind more research is needed to fully determine the impact of olive oil on Alzheimer’s disease.
8. Olive oil may reduce type 2 diabetes risk
Olive oil may help protect against type 2 diabetes.
A 2019 study found that people with prediabetes who took 55 mL of oleanolic acid-enriched olive oil each day were 55% less likely to develop diabetes than participants in the control group.
A 2017 meta-analysis also found that olive oil supplementation significantly helped reduce blood sugar levels and fasting plasma glucose in people with type 2 diabetes.
9. The antioxidants in olive oil have anticancer properties
Cancer is one of the most common causes of death in the world, according to the WHO.
People in Mediterranean countries have a lower risk of some cancers. Experts believe the Mediterranean diet — which includes olive oil - may be the reason.
A large 2022 meta-analysis found that people who consumed the highest amount of olive oil were 31% less likely to develop cancer.
This may be due to the antioxidants in olive oil, which may help reduce oxidative damage caused by free radicals, a leading driver of cancer.
Despite the positive outlook, more research is needed to determine the exact role of olive oil on cancer.
10. Olive oil can help treat rheumatoid arthritis
Rheumatoid arthritis is an autoimmune disease characterized by deformed and painful joints.
Although the exact cause is not well understood, it involves your immune system attacking healthy cells by mistake.
A 2023 study found that olive oil was linked with lower inflammatory markers and disease severity in people with rheumatoid arthritis, especially for more severe disease activity.
The researchers also found that olive oil helped decrease CRP levels, which may play a role in inflammation and disease progression.
However, limited research supports the effect of olive oil on rheumatoid arthritis.
A healthcare professional may recommend other natural remedies as part of your treatment plan.
11. Olive oil has antibacterial properties
Olive oil contains compounds that may inhibit or kill harmful bacteria.
One of these is Helicobacter pylori (H. pylori), a bacterium that lives in your stomach and may causeTrusted Source stomach ulcers and stomach cancer.
A 2022 animal study found that extra virgin olive oil may help fight against certain strains of this bacterium.
That said, more research on humans is needed to support olive oil’s role in fighting bacteria and infections. There are other, better-studied ways of treating H. pylori.
Make sure to get extra virgin olive oil
Buying extra virgin olive oil may provide more health benefits than refined olive oil.
Extra virgin olive oil retains some of the antioxidants and bioactive compounds from the olives, whereas refined olive oil loses much of the olive’s nutrients.
It’s also important to carefully read the labels and ingredient lists before buying a product. Many oils that read “extra virgin” on the label have been diluted with other refined oils.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2270 2024-08-24 18:03:30
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2272) Castor Oil
Gist
The only FDA-approved health use for castor oil is as a natural laxative to relieve temporary constipation. Its ricinoleic acid attaches to a receptor in your intestines.
Castor oil may be a good moisturizer for the skin, including the face, though no research suggests it can help reduce symptoms of any skin conditions like acne. However, always test a small skin area first to make sure you're not allergic, and always dilute it in a carrier oil like olive oil.
Castor oil does not have any whitening properties as such, however, combined with lemon essential oil, you will regain their natural colour as well as a good moisturiser! Mix 1 drop of lemon essential oil, 1 drop of castor oil and 1 drop of argan oil.
Summary
Castor oil has various uses in medicine, industry, and pharmaceuticals. It is found in food, medication, and skin care and is also used as an industrial lubricant and biodiesel component.
Castor oil, made from the Ricinus communis plant’s seeds, has been used for thousands of years. A heating process deactivates its toxic enzyme, ricin, making it safe to use.
In ancient Egypt, castor oil was used as fuel and for medicinal purposes like treating eye irritation and inducing labor in pregnancy.
Here are 4 potential benefits and uses of castor oil. We also cover its use as a hair treatment and precautions to consider.
1. A powerful laxative
Castor oil is well-known for its use as a natural laxative and is approved by the Food and Drug Administration (FDA) for this purpose.
It works quickly by stimulating muscle movement in the intestines, making it effective for temporary constipation relief or bowel cleansing before medical procedures. However, using too much castor oil can have negative side effects like abdominal cramping and diarrhea.
While it can be useful in treating occasional constipation, it should not be used for long-term health concerns without consulting a healthcare professional first, as misusing it can lead to dangerous complications.
2. A natural moisturizer
Castor oil is rich in ricinoleic acid, a monounsaturated fatty acid known for its moisturizing properties. It can be used alone or with other oils as a natural alternative to store-bought moisturizers.
Unlike commercial products, it contains no harmful additives and is suitable for the face and body. However, it may cause allergic reactions in some individuals, so always dilute it with a carrier oil like coconut oil before using it, and do a small skin patch test first before using it on larger skin areas.
3. May promote wound healing
Castor oil can help promote wound healing by creating a moist environment and preventing drying out.
For example, Venelex, a common ointment used in clinical settings, combines castor oil and Peru balsam, a balm derived from the Myroxylon balsamum tree, to treat wounds.
Additionally, ricinoleic acid, the main fatty acid found in castor oil, may help reduce skin inflammation, support healing, and aid in pain reduction in people with wounds.
Keep in mind that castor oil topical wound treatments contain a combination of ingredients, not just castor oil. You should not apply castor oil to any wound without checking with a healthcare professional first.
4. May be helpful for cleaning and storing dentures
A number of bacteria and fungi, including Candida fungi, commonly grow on dentures. This can create oral concerns if dentures aren’t properly cleaned and stored.
Candida species, like C. albicans, are especially problematic for people who wear dentures because they easily adhere to denture surfaces and mouth tissues.
An overgrowth of Candida fungi can lead to a condition called denture stomatitis, an infection that leads to inflammation, redness, and irritation in the mouth.
However, some research suggests that cleaning dentures with castor oil may help reduce the risk of developing denture stomatitis because castor oil can help kill bacteria and fungi.
Can castor oil support hair growth and scalp health?
Many people use castor oil as a natural hair treatment. This is because castor oil has moisturizing properties, which could help lubricate the hair shaft, increasing flexibility and decreasing the chance of breakage.
Even though some people regularly use castor oil as part of their hair care routine, there’s no scientific evidence that castor oil helps promote hair health, stimulates hair growth, or reduces hair loss.
The same goes for using castor oil on your eyelashes or for treating dandruff. Some people use castor oil for eyelash growth, but no scientific research has shown this is actually effective.
In fact, castor oil could lead to a condition called acute hair felting in people with long hair, which causes the hair to become twisted and tangled, resembling a hard bird’s nest. Typically, this can’t be treated, and the hair must be cut off.
Even though this condition is rare, people with long hair should be cautious when using castor oil as a hair
treatment.
Details
Castor oil is a vegetable oil pressed from castor beans, the seeds of the plant Ricinus communis. The seeds are 40 to 60 percent oil. It is a colourless or pale yellow liquid with a distinct taste and odor. Its boiling point is 313 °C (595 °F) and its density is 0.961 g/{cm}^3. It includes a mixture of triglycerides in which about 90 percent of fatty acids are ricinoleates. Oleic acid and linoleic acid are the other significant components.
Some 270,000–360,000 tonnes (600–800 million pounds) of castor oil are produced annually for a variety of uses. Castor oil and its derivatives are used in the manufacturing of soaps, lubricants, hydraulic and brake fluids, paints, dyes, coatings, inks, cold-resistant plastics, waxes and polishes, nylon, and perfumes.
Etymology
The name probably comes from a confusion between the Ricinus plant that produces it and another plant, the Vitex agnus-castus. An alternative etymology, though, suggests that it was used as a replacement for castoreum.
History
Use of castor oil as a laxative is attested to in the c. 1550 BCE Ebers Papyrus, and was in use several centuries earlier. Midwifery manuals from the 19th century recommended castor oil and 10 drops of laudanum for relieving "false pains."
Composition
Castor oil is well known as a source of ricinoleic acid, a monounsaturated, 18-carbon fatty acid. Among fatty acids, ricinoleic acid is unusual in that it has a hydroxyl functional group on the 12th carbon atom. This functional group causes ricinoleic acid (and castor oil) to be more polar than most fats. The chemical reactivity of the alcohol group also allows chemical derivatization that is not possible with most other seed oils.
Because of its ricinoleic acid content, castor oil is a valuable chemical in feedstocks, commanding a higher price than other seed oils. As an example, in July 2007, Indian castor oil sold for about US$0.90/kg ($0.41/lb), whereas U.S. soybean, sunflower, and canola oils sold for about $0.30/kg ($0.14/lb).
Human uses
Castor oil has been used orally to relieve constipation or to evacuate the bowel before intestinal surgery. The laxative effect of castor oil is attributed to ricinoleic acid, which is produced by hydrolysis in the small intestine. Use of castor oil for simple constipation is medically discouraged because it may cause violent diarrhea.
Food and preservative
In the food industry, food-grade castor oil is used in food additives, flavorings, candy (e.g., polyglycerol polyricinoleate in chocolate), as a mold inhibitor, and in packaging. Polyoxyethylated castor oil (e.g., Kolliphor EL) is also used in the food industries. In India, Pakistan, and Nepal, food grains are preserved by the application of castor oil. It stops rice, wheat, and pulses from rotting. For example, the legume pigeon pea is commonly available coated in oil for extended storage.
Emollient
Castor oil has been used in cosmetic products included in creams and as a moisturizer. It is often combined with zinc oxide to form an emollient and astringent, zinc and castor oil cream, which is commonly used to treat infants for nappy rash.
Alternative medicine
According to the American Cancer Society, "available scientific evidence does not support claims that castor oil on the skin cures cancer or any other disease."
Childbirth
There is no high-quality research proving that ingestion of castor oil results in cervical ripening or induction of labor; there is, however, evidence that taking it causes nausea and diarrhea. A systematic review of "three trials, involving 233 women, found there has not been enough research done to show the effects of castor oil on ripening the cervix or inducing labour or compare it to other methods of induction. The review found that all women who took castor oil by mouth felt nauseous. More research is needed into the effects of castor oil to induce labour." Castor oil is still used for labor induction in environments where modern drugs are not available; a review of pharmacologic, mechanical, and "complementary" methods of labor induction published in 2024 by the American Journal of Obstetrics and Gynecology stated that castor oil's physiological effect is poorly understood but "given gastrointestinal symptomatology, a prostaglandin mediation has been suggested but not confirmed." According to Drugs in Pregnancy and Lactation: A Reference Guide to Fetal and Neonatal Risk (2008), castor oil should not be ingested or used topically by pre-term pregnant women. There is no data on the potential toxicity of castor oil for nursing mothers.
Punishment
Since children commonly strongly dislike the taste of castor oil, some parents punished children with a dose of it. Physicians recommended against the practice because they did not want medicines associated with punishment.
Use in torture
A heavy dose of castor oil could be used as a humiliating punishment for adults. Colonial officials used it in the British Raj (India) to deal with recalcitrant servants. Belgian military officials prescribed heavy doses of castor oil in Belgian Congo as a punishment for being too sick to work. Castor oil was also a tool of punishment favored by the Falangist and later Francoist Spain during and following the Spanish Civil War. Its use as a form of gendered violence to repress women was especially prominent. This began during the war where Nationalist forces would specifically target Republican-aligned women, both troops and civilians, who lived in Republican-controlled areas. The forced drinking of castor oil occurred alongside sexual assault, math, torture and murder of these women. Its most notorious use as punishment came in Fascist Italy under Benito Mussolini. It was a favorite tool used by the Blackshirts to intimidate and humiliate their opponents. Political dissidents were force-fed large quantities of castor oil by fascist squads so as to induce bouts of extreme diarrhea in the victims. This technique was said to have been originated by Gabriele D'Annunzio or Italo Balbo. This form of torture was potentially deadly, as the administration of the castor oil was often combined with nightstick beatings, especially to the rear, so that the resulting diarrhea would not only lead to dangerous dehydration but also infect the open wounds from the beatings. However, even those victims who survived had to bear the humiliation of the laxative effects resulting from excessive consumption of the oil.
Additional Information
Castor oil is a natural vegetable oil that has been used for centuries for its soothing and nourishing properties. This pure oil is loaded with nutrients, including fatty acids, minerals and vitamins. It can be used in various ways, offering several benefits for the skin and hair. In this blog post, we'll look at the many valuable uses of castor oil and provide some simple cosmetic recipes you can make at home.
What Is Castor Oil?
Castor oil is a clear yellow oil obtained by cold pressing the seeds of the castor bean plant, which is native to Ethiopia as well as many other tropical regions. It has a thick consistency and neutral scent.
Castor oil is a multi-purpose vegetable oil. It is well known for its use as a natural laxative but is also used in foods and medications, as an industrial lubricant and in cosmetic products for the skin and hair. It’s commonly used in cold process soaps too thanks to its ability to improve the lather, as well as its skin conditioning properties.
This natural oil contains high amounts of vitamins and essential fatty acids, including omega-3, vitamin E, omega-6 and ricinoleic acid. This is why castor oil is such an excellent cosmetic ingredient and can easily be used to create effective skin and hair care products.
What Are the Benefits of Castor Oil?
Below are eight amazing benefits of castor oil for the skin and hair.
1. Nourishes and Protects the Skin
Castor oil is incredibly gentle and soothing — so much so that it can even be used on babies. This natural ingredient is a great protector of dry or damaged skin. Its high-fat content helps shield the skin against bacteria while also acting as a barrier to prevent moisture loss. As castor oil is packed with the powerful antioxidant ricinoleic acid, it protects the skin from free radical damage too.
2. Makes an Amazing Natural Moisturiser
Castor oil is a natural emollient, which means it does an excellent job of hydrating and conditioning the skin when mixed with other suitable carrier oils. This oil helps maintain the skin’s barrier function and is a popular ingredient in moisturising cosmetics, giving the skin a significant moisture boost while improving its texture and overall appearance. Use castor oil in creams, lotions and massage blends for a luxurious skin-soothing feel.
3. Adds Strength and Shine to Hair
This versatile oil isn’t only good for the skin — it’s also a fantastic ingredient in hair care products. One ideal use for castor oil is as a hair conditioner for incredible softness and shine. It can also be used as hair or scalp oil to soothe dry skin.
4. Boosts Brows and Lashes
Many people swear by using castor oil for brow and eyelash growth. Although no scientific studies have proven that castor oil aids hair growth, applying a small amount to your lashes and eyebrows can condition and thicken the hairs to improve their appearance.
5. Reduces the Appearance of Wrinkles
Thanks to its moisturising and protective properties, castor oil can improve the suppleness and flexibility of the skin. The essential fatty acids it contains can also boost cell renewal, reducing the appearance of fine lines and wrinkles. Castor oil is a brilliant addition to your skincare routine and will help you maintain a natural, youthful glow.
6. High in Nutrients
The nutrients and fatty acids in castor oil offer many hair and skin-boosting benefits, making it a versatile ingredient with a wide range of cosmetic uses. As well as vitamin E, omega-6 and ricinoleic acid, castor oil also contains omega-3 and omega-9 fatty acids and several other minerals and proteins. This vitamin-rich formula is what gives castor oil its intense moisturising properties.
7. Conditions the Cuticles
Did you know that castor oil isn’t just for your face? It also makes a great moisturiser for your hands and nails, nourishing and conditioning your cuticles for extra strength and shine. Dab a little on your nail beds before your next manicure to prevent breakage.
8. Smooths Out Your Hairstyle
If you struggle with flyaways and frizzy hair, castor oil could be the hair product you’ve been waiting for. Try applying a small amount to your hairline for a smooth finish, or use it to tame fuzzy ends for a beautiful polished look. As castor oil has a thick consistency, you may prefer to mix it with a thinner carrier oil for easier application. Try jojoba oil for extra softness and shine.
What Skin Type Is Castor Oil Good For?
Castor oil is particularly effective on dry, damaged or ageing skin, and it's also suitable for fighting breakouts. As this natural vegetable oil is quite thick, some people may find that it clogs their pores, but using it in small percentages as part of a blend will help prevent this.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2271 2024-08-25 00:01:51
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2273) Nail Polish
Gist
Nail polish (also known as nail varnish in British English or nail enamel) is a lacquer that can be applied to the human fingernails or toenails to decorate and protect the nail plates.
Men would apply polish to their nails to make them look shiny and clean. However, it wasn't long before women were also using nail polish, with the beauty trend typically taken up by men and women of the aristocracy because clean, fresh hands symbolised wealth and status.
Details
Nail polish (also known as nail varnish in British English or nail enamel) is a lacquer that can be applied to the human fingernails or toenails to decorate and protect the nail plates. The formula has been revised repeatedly to enhance its decorative properties, to be safer for the consumer to use, and to suppress cracking or peeling. Nail polish consists of a mix of an organic polymer and several other components that give it colors and textures. Nail polishes come in all color shades and play a significant part in manicures and pedicures.
History
Nail polish originated in China and dates back to 3000 BCE. Around 600 BCE, during the Zhou dynasty, the royal house preferred the colors gold and silver. However, red and black eventually replaced these metallic colors as royal favorites. During the Ming dynasty, nail polish was often made from a mixture that included beeswax, egg whites, gelatin, vegetable dyes, and gum arabic.
In Egypt, the lower classes wore pale colors of nail polish, whereas high society painted their nails a reddish brown with henna. Mummified pharaohs also had their nails painted with henna.
In Europe, Frederick S. N. Douglas, while traveling in Greece in 1810–1812, noticed that the Greek women used to paint their nails "dingy pink", which he understood as an ancient custom. Early nail polish formulas were created using basic ingredients such as lavender oil, carmine, oxide tin, and bergamot oil. It was more common to polish nails with tinted powders and creams, finishing off by buffing the nail until left shiny. One type of polishing product sold around this time was Graf's Hyglo nail polish paste.
In Victorian era culture it was generally considered improper for women to adorn themselves with either makeup or nail coloring, since natural appearances were considered more chaste and pure. In the 1920s, however, women began to wear color in new makeups and nail products, partly in rebellion to such prim customs of their recent past.[citation needed] In 1920s France, a big pioneer of nail polish was the hairstylist Antoine de Paris, whose cosmetic company produced some of the first modern polishes, and he himself shocked the newspapers by wearing each nail painted a different color.
Since the 1920s, nail colors progressed from French manicures and standard reds to various palettes of color choices, usually coordinated with the fashion industry's clothing colors for the season. By the 1940s the whole nail was painted; before that, it was fashionable to leave the tips and a half-moon on the nail bed bare.
Ingredients
Modern nail polish consists predominately of a film-forming polymer dissolved in a volatile organic solvent. The most common polymer is nitrocellulose, although the more expensive cellulose acetates such as CAB are claimed to give better performance. In gel nail varnish, the polymer is usually some sort of acrylate copolymer. The solvents are commonly butyl acetate or ethyl acetate. Low levels of various additives are included to give the desired finish:
* Plasticizers to yield non-brittle films. diethylphthalate, dibutylphthalate and camphor are typical.
* Dyes and pigments. Representative compounds include chromium oxide greens, chromium hydroxide, ferric ferrocyanide, stannic oxide, titanium dioxide, iron oxide, carmine, ultramarine, and manganese violet.
* Opalescent pigments. The glittery/shimmer look in the color can be conferred by mica, bismuth oxychloride, natural pearls, and aluminum powder.
* Adhesive polymers ensure that the nitrocellulose adheres to the nail's surface. One modifier used is tosylamide-formaldehyde resin.
* Thickening agents are added to maintain the sparkling particles in suspension while in the bottle. A typical thickener is stearalkonium hectorite. Thickening agents exhibit thixotropy, their solutions are viscous when still but free-flowing when agitated. This duality is convenient for easily applying the freshly shaken mixture to give a film that quickly rigidifies.
* Ultraviolet stabilizers resist color changes when the dry film is exposed to sunlight. A typical stabilizer is benzophenone-1.
Types:
Base coat
This type of nail polish is a clear, milky-colored, or opaque pink polish formula that is used specifically before applying nail polish to the nail. Its function is to strengthen nails, restore moisture to the nail, and help polish adhere to the nail. It prevents staining and extends the lifespan of the manicure. Some base coats are marketed as "ridge fillers", and can create a smooth surface, de-emphasizing the ridges that can appear on unbuffed nails. Some base coats, called "peel off base coats", allow the user to peel off their nail polish without using a remover.
Top coat
This type of nail polish is a clear colored polish formula that is used specifically after applying nail polish to the nail. It forms a hardened barrier for the nail that can prevent chipping, scratching and peeling. Many topcoats are marketed as "quick-drying." Topcoats can help the underlying colored polish dry quickly as well. It gives the polish a more finished and desired look and may help to keep the polish on longer.
Gel
Gel polish is a long-lasting variety of nail polish made up of a type of methacrylate polymer. It is painted on the nail similar to traditional nail polish, but does not dry. Instead it is cured under an ultraviolet lamp or ultraviolet LED. While regular nail polish formulas typically last two to seven days without chipping, gel polish can last as long as two weeks with proper application and home care. Gel polish can be more difficult to remove than regular nail polish. It is usually removed by soaking the nails in pure acetone (the solvent used in most nail polish removers) for five to fifteen minutes, depending on the formula.
In fashion
Traditionally, nail polish started in clear, white, red, pink, purple, and black. Nail polish can be found in a diverse variety of colors and shades. Beyond solid colors, nail polish has also developed an array of other designs, such as crackled, glitter, flake, speckled, iridescent, and holographic. Rhinestones or other decorative art are also often applied to nail polish. Some polish is advertised to induce nail growth, make nails stronger, prevent nails from breaking, cracking, or splitting, and even to stop nail biting.
French manicure
French manicures are designed to resemble natural nails, and are characterized by natural pink or unaided base nails with white tips. French manicures were one of the first popular and well-known color schemes. French manicures may have originated in the eighteenth-century in Paris but were most popular in the 1920s and 1930s. However, the traditional French manicures were much different from what we know today. They were generally red, while leaving a round crescent shape at the area near the cuticle blank to enhance the lunula of the nail, known now as a half-moon manicure.
With the modern French manicure, trends involving painting different colors for the tips of the nails instead of the white. French tip nails can be made with stickers and stencils. It is still typically done by hand through painting with polish or gel, or sculptured with acrylic.
Nail art
Nail art is a creative way to paint, decorate, enhance, and embellish nails. Social media has expanded to a nail art culture by allowing users to share pictures of their nail art. Women's Wear Daily reports nail polish sales hit a record US$768 million in the United States in 2012, a 32% gain over 2011. Several new polishes and related products came on to the market in the 2020s as part of the explosion of nail art, such as nail stickers (either made of nail polish or plastic), stencils, magnetic nail polish, nail pens, glitter and sequin topcoats, nail caviar (micro beads), nail polish marketed for men, scented nail polish, and color changing nail polish (some which change hue when exposed to sunshine, and ranges which change hue in response to heat).
Western world
Nail polish in the Western world was more frequently worn by women, going in and out of acceptability depending upon moral customs of the day. It is less common for men to wear nail polish, and can be seen as a divergence from traditional gender norms. Colored and clear polishes can be used to protect nails from breakage, impart a well-groomed sheen, or express oneself artistically. Professional baseball players, especially catchers, may wear nail polish on the field.
Finishes
There are 18 principal nail polish finishes:
* Shimmer
* Micro-shimmer
* Micro-glitter
* Glitter
* Frost
* Lustre
* Creme
* Iridescent
* Opalescent
* Matte (a formula of nail polish, or a topper placed on top of a coat of normal nail polish, that has a matte finish when dried)
* Duochrome
* Jelly or translucent (clear nailpolish with a tint, usually a natural or neon colour)
* Magnetic (nail polish with metallic particles that react to specially shaped magnets for nail art)
* Crackled (a topper placed on a coat of nail polish, which crackles on top of said coat)
* Glass-flecked
* Holographic (glitter nail polish that reflects all colours when light is shone on them)
* Prismatic micro-glitter or shimmer
* Fluorescent (Glow-in-the-Dark, Neon)
Nail polish remover
Nail polish remover is an organic solvent that may also include oils, scents, and coloring. Nail polish remover packages may include individual felt pads soaked in remover, a bottle of liquid remover used with a cotton ball or cotton pad, or a foam-filled container into which one inserts a finger and twists it until the polish comes off. The choice of remover type depends on the user's preference, and often the price or quality of the remover.
The most common remover is acetone. Acetone can also remove artificial nails made of acrylic or cured gel.
An alternative nail polish remover is ethyl acetate, which often also contains isopropyl alcohol. Ethyl acetate is usually the original solvent for nail polish itself.
Acetonitrile has been used as a nail polish remover, but it is more toxic than the aforementioned options. It has been banned in the European Economic Area for use in cosmetics since 17 March 2000.
Health concerns
The health risks associated with nail polish are disputed. According to the U.S. Department of Health and Human Services, "The amount of chemicals used in animal studies is probably a couple of hundred times higher than what you would be exposed to from using nail polish every week or so. So the chances of any individual phthalate producing such harm [in humans] is very slim." A more serious health risk is faced by professional nail technicians, who perform manicures over a workstation, known as a nail table, on which the client's hands rest – directly below the technician's breathing zone. In 2009, Susan Reutman, an epidemiologist with the U.S. National Institute for Occupational Safety and Health's Division of Applied Research and Technology, announced a federal effort to evaluate the effectiveness of downdraft vented nail tables (VNTs) in removing potential nail polish chemical and dust exposures from the technician's work area. These ventilation systems have potential to reduce worker exposure to chemicals by at least 50%. Many nail technicians will often wear masks to cover their mouth and nose from inhaling any of the harsh dust or chemicals from the nail products.
According to Reutman, a growing body of scientific literature suggests that some inhaled and absorbed organic solvents found in nail salons such as glycol ethers and carbon disulfide may have adverse effects on reproductive health. These effects may including birth defects, low birth weight, miscarriage, and preterm birth.
Nail polish formulations may include ingredients that are toxic or affect other health problems. One controversial family of ingredient are phthalates, which are implicated as endocrine disruptors and linked to problems in the endocrine system and increased risk of diabetes. Manufacturers have been pressured by consumer groups to reduce or to eliminate potentially-toxic ingredients, and in September 2006, several companies agreed to phase out dibutyl phthalates. There are no universal consumer safety standards for nail polish, however, and while formaldehyde has been eliminated from some nail polish brands, others still use it.
Regulation and environmental concerns
The U.S. city of San Francisco enacted a city ordinance, publicly identifying establishments that use nail polishes free of the "toxic trio" of dibutyl phthalate, toluene, and formaldehyde.
Nail polish is considered a hazardous waste by some regulatory bodies such as the Los Angeles Department of Public Works. Many countries have strict restrictions on sending nail polish by mail. The "toxic trio" are currently being phased out, but there are still components of nail polish that could cause environmental concern. Leaking out of the bottle into the soil could cause contamination in ground water. Chromium(III) oxide green and Prussian blue are common in nail polish and have shown evidence of going through chemical degradation, which could have a detrimental effect on health.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2272 2024-08-25 22:24:02
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2274) Soft Drink
Gist
Bottled soft drinks are a class of nonalcoholic beverage that contain water, nutritive or nonnutritive sweeteners, acids, flavors, colors, emulsifiers, preservatives, and various other compounds that are added for their functional properties.
Summary
A soft drink, any of a class of nonalcoholic beverages, usually but not necessarily carbonated, normally containing a natural or artificial sweetening agent, edible acids, natural or artificial flavours, and sometimes juice. Natural flavours are derived from fruits, nuts, berries, roots, herbs, and other plant sources. Coffee, tea, milk, cocoa, and undiluted fruit and vegetable juices are not considered soft drinks.
The term soft drink was originated to distinguish the flavoured drinks from hard liquor, or distilled spirits. Soft drinks were recommended as a substitute in the effort to change the hard-drinking habits of early Americans. Indeed, health concerns of modern consumers led to new categories of soft drinks emphasizing low calorie count, low sodium content, no caffeine, and “all natural” ingredients.
There are many specialty soft drinks. Mineral waters are very popular in Europe and Latin America. Kava, made from roots of a bushy shrub, Piper methysticum, is consumed by the people of Fiji and other Pacific islands. In Cuba people enjoy a carbonated cane juice; its flavour comes from unrefined syrup. In tropical areas, where diets frequently lack sufficient protein, soft drinks containing soybean flour have been marketed. In Egypt carob (locust bean) extract is used. In Brazil a soft drink is made using maté as a base. The whey obtained from making buffalo cheese is carbonated and consumed as a soft drink in North Africa. Some eastern Europeans enjoy a drink prepared from fermented stale bread. Honey and orange juice go into a popular drink of Israel.
History of soft drinks
The first marketed soft drinks appeared in the 17th century as a mixture of water and lemon juice sweetened with honey. In 1676 the Compagnie de Limonadiers was formed in Paris and granted a monopoly for the sale of its products. Vendors carried tanks on their backs from which they dispensed cups of lemonade.
Carbonated beverages and waters were developed from European attempts in the 17th century to imitate the popular and naturally effervescent waters of famous springs, with primary interest in their reputed therapeutic values. The effervescent feature of the waters was recognized early as most important. Flemish scientist Jan Baptista van Helmont first used the term gas in his reference to the carbon dioxide content. French physician Gabriel Venel referred to aerated water, confusing the gas with ordinary air. British scientist Joseph Black named the gaseous constituent fixed air.
Robert Boyle, an Anglo-Irish philosopher and scientist who helped found modern chemistry, published his Short Memoirs for the Natural Experimental History of Mineral Waters in 1685. It included sections on examining mineral springs, on the properties of the water, on its effects upon the human body, and, lastly, “of the imitation of natural medicinal waters by chymical and other artificial wayes.”
Numerous reports of experiments and investigations were included in the Philosophical Transactions of the Royal Society of London in the late 1700s, including the studies of Stephen Hales, Joseph Black, David Macbride, William Brownrigg, Henry Cavendish, and Thomas Lane.
English clergyman and scientist Joseph Priestley is nicknamed “the father of the soft drinks industry” for his experiments on gas obtained from the fermenting vats of a brewery. In 1772 he demonstrated a small carbonating apparatus to the College of Physicians in London, suggesting that, with the aid of a pump, water might be more highly impregnated with fixed air. French chemist Antoine-Laurent Lavoisier made the same suggestion in 1773.
To Thomas Henry, an apothecary in Manchester, England, is attributed the first production of carbonated water, which he made in 12-gallon barrels using an apparatus based on Priestley’s design. Swiss jeweler Jacob Schweppe read the papers of Priestley and Lavoisier and determined to make a similar device. By 1794 he was selling his highly carbonated artificial mineral waters to his friends in Geneva; later he started a business in London.
At first, bottled waters were used medicinally, as evidenced in a letter written by English industrialist Matthew Boulton to philosopher Erasmus Darwin in 1794:
J. Schweppe prepares his mineral waters of three sorts. No. 1 is for common drinking with your dinner. No. 2 is for nephritick patients and No. 3 contains the most alkali given only in more violent cases.
By about 1820, improvements in manufacturing processes allowed a much greater output, and bottled water became popular. Mineral salts and flavours were added—ginger about 1820, lemon in the 1830s, tonic in 1858. In 1886 John Pemberton, a pharmacist in Atlanta, Georgia, invented Coca-Cola, the first cola drink.
Production
All ingredients used in soft drinks must be of high purity and food grade to obtain a quality beverage. These include the water, carbon dioxide, sugar, acids, juices, and flavours.
Water
Although water is most often taken from a safe municipal supply, it usually is processed further to ensure uniformity of the finished product; the amount of impurities in the municipal supply may vary from time to time. In some bottling plants the water-treatment equipment may simply consist of a sand filter to remove minute solid matter and activated carbon purifier to remove colour, chlorine, and other tastes or odours. In most plants, however, water is treated by a process known as superchlorination and coagulation. There the water is exposed for two hours to a high concentration of chlorine and to a flocculant, which removes organisms such as algae and bacteria; it then passes through a sand filter and activated carbon.
Carbon dioxide and carbonation
Carbon dioxide gas gives the beverage its sparkle and tangy taste and prevents spoilage. It is supplied to the soft drink manufacturer in either solid form (dry ice) or liquid form maintained under approximately 1,200 pounds per square inch (84 kilograms per square centimetre) pressure in heavy steel containers. Lightweight steel containers are used when the liquid carbon dioxide is held under refrigeration. In that case, the internal pressure is about 325 pounds per square inch.
Carbonation (of either the water or the finished beverage mixture) is effected by chilling the liquid and cascading it in thin layers over a series of plates in an enclosure containing carbon dioxide gas under pressure. The amount of gas the water will absorb increases as the pressure is increased and the temperature is decreased.
Flavouring syrup
Flavouring syrup is normally a concentrated solution of a sweetener (sugar or artificial), an acidulant for tartness, flavouring, and a preservative when necessary. The flavouring syrup is made in two steps. First, a “simple syrup” is prepared by making a solution of water and sugar. This simple sugar solution can be treated with carbon and filtered if the sugar quality is poor. All of the other ingredients are then added in a precise order to make up what is called a “finished syrup.”
Finishing
There are two methods for producing a finished product from the flavouring syrup. In the first, the syrup is diluted with water and the product then cooled, carbonated, and bottled. In the second, the maker measures a precise amount of syrup into each bottle, then fills it with carbonated water. In either case, the sugar content (51–60 percent in the syrup) is reduced to 8–13 percent in the finished beverage. Thus, a 12-ounce soft drink may contain more than 40 grams of sugar.
The blending of syrups and mixing with plain or carbonated water, the container washing, and container filling are all done almost entirely by automatic machinery. Returnable bottles are washed in hot alkali solutions for a minimum of five minutes, then rinsed thoroughly. Single-service or “one-trip” containers are generally air-rinsed or rinsed with potable water before filling. Automatic fillers can service hundreds of containers per minute.
Pasteurizing noncarbonated beverages
Noncarbonated beverages require ingredients and techniques similar to those for carbonated beverages. However, since they lack the protection against spoilage afforded by carbonation, these are usually pasteurized, either in bulk, by continuous flash pasteurization prior to filling, or in the bottle.
Powdered soft drinks
These are made by blending the flavouring material with dry acids, gums, artificial colour, etc. If the sweetener has been included, the consumer need only add the proper amount of plain or carbonated water.
Iced soft drinks
The first iced soft drink consisted of a cup of ice covered with a flavoured syrup. Sophisticated dispensing machines now blend measured quantities of syrup with carbonated or plain water to make the finished beverage. To obtain the soft ice, or slush, the machine reduces the beverage temperature to between −5 and −2 °C (22 and 28 °F).
Packaging and vending
Soft drinks are packaged in glass or plastic bottles, tin-free steel, aluminum, or plastic cans, treated cardboard cartons, foil pouches, or in large stainless steel containers.
Vending of soft drinks had its modest beginning with the use of ice coolers in the early 20th century. Nowadays, most drinks are cooled by electric refrigeration for consumption on the premises. Vending machines dispense soft drinks in cups, cans, or bottles, and restaurants, bars, and hotels use dispensing guns to handle large volume. There are two methods of vending soft drinks in cups. In the “pre-mix” system, the finished beverage is prepared by the soft drink manufacturer and filled into five- or 10-gallon stainless steel tanks. The tanks of beverage are attached to the vending machine where the beverage is cooled and dispensed. In the “post-mix” system the vending machine has its own water and carbon dioxide supply. The water is carbonated as required and is mixed with flavoured syrup as it is dispensed into the cup.
Health and regulatory issues
The regular consumption of soft drinks has been associated with multiple chronic health conditions. These increased risks are largely due to the added ingredients in soft drinks, especially sugar. Indeed, some sugar-sweetened soft drinks contain 40 grams of sugar or more per 12-ounce serving, which exceeds the recommended daily sugar intake for adults. According to the American Heart Association, women should consume no more than 25 grams of added sugar per day and men 38 grams per day. The consumption of just one to two servings of sugar-sweetened soft drinks daily significantly increases the risk of metabolic syndrome and type 2 diabetes. In addition, both men and women who drink sugar-sweetened beverages are at increased risk of coronary heart disease and premature death; for each sugary beverage a person consumes, the risk of death from cardiovascular disease increases by about 10 percent. Diet soft drinks can also be problematic for health: daily consumption of two or more diet soft drinks, specifically those that are artificially sweetened, increases the risk of heart disease and stroke in women.
In children and adults, long-term consumption of soft drinks is linked to weight gain, obesity, and tooth decay. Sugar-free soft drinks also have been associated with dental erosion. The detrimental effects to teeth are related to soft drink acidity, sugar content, and the presence of certain chemicals, such as chelators, which demineralize teeth.
Concerns about the negative health effects of soft drinks have given rise to debate about legally restricting their consumption through soda bans, increased soda taxes, and other regulatory measures. In January 2014 Mexico became one of the first countries to impose a nationwide revenue-raising tax on soft drinks containing added sugar. Later that year Berkeley, California, became the first city in the United States in which voters unanimously approved a tax on sugary drinks. In 2015 a ban on the sale of caffeinated soft drinks to children went into effect in the Vologda region of Russia. That same year authorities in San Francisco approved a measure that would require soft drink manufacturers to add health warnings to soft drink labels, similar to the health warnings displayed on labels for alcohol and tobacco products.
Despite the known health risks of soft drink consumption, many regulatory measures failed. In 2013 in New York City, for example, a proposal to ban the sale of oversize soft drinks (larger than 16 ounces) was defeated in court. The American Beverage Association, which led the challenge against the plan, claimed that the city’s health board overstepped the boundaries of its control over public health when it approved the proposal.
Details
A soft drink is any water-based flavored drink, usually but not necessarily carbonated, and typically including added sweetener. Flavors used can be natural or artificial. The sweetener may be a sugar, high-fructose corn syrup, fruit juice, a sugar substitute (in the case of diet sodas), or some combination of these. Soft drinks may also contain caffeine, colorings, preservatives and other ingredients.
Soft drinks are called "soft" in contrast with "hard" alcoholic drinks. Small amounts of alcohol may be present in a soft drink, but the alcohol content must be less than 0.5% of the total volume of the drink in many countries and localities if the drink is to be considered non-alcoholic. Types of soft drinks include lemon-lime drinks, orange soda, cola, grape soda, cream soda, ginger ale and root beer.
Soft drinks may be served cold, over ice cubes, or at room temperature. They are available in many container formats, including cans, glass bottles, and plastic bottles. Containers come in a variety of sizes, ranging from small bottles to large multi-liter containers. Soft drinks are widely available at fast food restaurants, movie theaters, convenience stores, casual-dining restaurants, dedicated soda stores, vending machines and bars from soda fountain machines.
Within a decade of the invention of carbonated water by Joseph Priestley in 1767, inventors in Britain and in Europe had used his concept to produce the drink in greater quantities. One such inventor, J. J. Schweppe, formed Schweppes in 1783 and began selling the world's first bottled soft drink. Soft drink brands founded in the 19th century include R. White's Lemonade in 1845, Dr Pepper in 1885 and Coca-Cola in 1886. Subsequent brands include Pepsi, Irn-Bru, Sprite, Fanta, 7 Up and RC Cola.
Terminology
The term "soft drink" is a category in the beverage industry, and is broadly used in product labeling and on restaurant menus, generally a euphemistic term meaning non-alcoholic. However, in many countries such drinks are more commonly referred to by regional names, including pop, cool drink, fizzy drink, cola, soda, or soda pop. Other lesser used terms include carbonated drink, fizzy juice, lolly water, seltzer, coke, tonic, and mineral. Due to the high sugar content in typical soft drinks, they may also be called sugary drinks.
In the United States, the 2003 Harvard Dialect Survey tracked the usage of the nine most common names. Over half of the survey respondents preferred the term "soda", which was dominant in the Northeastern United States, California, and the areas surrounding Milwaukee and St. Louis. The term "pop", which was preferred by 25% of the respondents, was most popular in the Midwest and Pacific Northwest, while the genericized trademark "coke", used by 12% of the respondents, was most popular in the Southern United States. The term "tonic" is distinctive to eastern Massachusetts, although usage is declining.
In the English-speaking parts of Canada, the term "pop" is prevalent, but "soft drink" is the most common English term used in Montreal.
In the United Kingdom and Ireland, the term "fizzy drink" is common. "Pop" and "fizzy pop" are used in Northern England, South Wales, and the Midlands while "mineral" is used in Ireland. In Scotland, "fizzy juice" or even simply "juice" is colloquially encountered, as is "ginger". In Australia and New Zealand, "soft drink" or "fizzy drink" is typically used. In South African English, "cool drink" is any soft drink.
In other languages, various names are used: descriptive names as "non-alcoholic beverages", equivalents of "soda water", or generalized prototypical names. For example, the Bohemian variant of the Czech language (but not Moravian dialects) uses "limonáda" for all such beverages, not only for those from lemons. Similarly, the Slovak language uses "malinovka" (= "raspberry water") for all such beverages, not only for raspberry ones.
History
The origins of soft drinks lie in the development of fruit-flavored drinks. In the medieval Middle East, a variety of fruit-flavored soft drinks were widely drunk, such as sharbat, and were often sweetened with ingredients such as sugar, syrup and honey. Other common ingredients included lemon, apple, pomegranate, tamarind, jujube, sumac, musk, mint and ice. Middle Eastern drinks later became popular in medieval Europe, where the word "syrup" was derived from Arabic. In Tudor England, 'water imperial' was widely drunk; it was a sweetened drink with lemon flavor and containing cream of tartar. 'Manays Cryste' was a sweetened cordial flavored with rosewater, violets or cinnamon.
Another early type of soft drink was lemonade, made of water and lemon juice sweetened with honey, but without carbonated water. The Compagnie des Limonadiers of Paris was granted a monopoly for the sale of lemonade soft drinks in 1676. Vendors carried tanks of lemonade on their backs and dispensed cups of the soft drink to Parisians.
Carbonated drinks
Carbonated drinks or fizzy drinks are beverages that consist mainly of carbonated water. The dissolution of carbon dioxide (CO2) in a liquid, gives rise to effervescence or fizz. Carbon dioxide is only weakly soluble in water; therefore, it separates into a gas when the pressure is released. The process usually involves injecting carbon dioxide under high pressure. When the pressure is removed, the carbon dioxide is released from the solution as small bubbles, which causes the solution to become effervescent, or fizzy.
Carbonated beverages are prepared by mixing flavored syrup with carbonated water. Carbonation levels range up to 5 volumes of CO2 per liquid volume. Ginger ale, colas, and related drinks are carbonated with 3.5 volumes. Other drinks, often fruity ones, are carbonated less.
In the late 18th century, scientists made important progress in replicating naturally carbonated mineral waters. In 1767, Englishman Joseph Priestley first discovered a method of infusing water with carbon dioxide to make carbonated water when he suspended a bowl of distilled water above a beer vat at a local brewery in Leeds, England. His invention of carbonated water (later known as soda water, for the use of soda powders in its commercial manufacture) is the major and defining component of most soft drinks.
Priestley found that water treated in this manner had a pleasant taste, and he offered it to his friends as a refreshing drink. In 1772, Priestley published a paper entitled Impregnating Water with Fixed Air in which he describes dripping oil of vitriol (or sulfuric acid as it is now called) onto chalk to produce carbon dioxide gas and encouraging the gas to dissolve into an agitated bowl of water.
Another Englishman, John Mervin Nooth, improved Priestley's design and sold his apparatus for commercial use in pharmacies. Swedish chemist Torbern Bergman invented a generating apparatus that made carbonated water from chalk by the use of sulfuric acid. Bergman's apparatus allowed imitation mineral water to be produced in large amounts. Swedish chemist Jöns Jacob Berzelius started to add flavors (spices, juices, and wine) to carbonated water in the late eighteenth century. Thomas Henry, an apothecary from Manchester, was the first to sell artificial mineral water to the general public for medicinal purposes, beginning in the 1770s. His recipe for 'Bewley's Mephitic Julep' consisted of 3 drachms of fossil alkali to a quart of water, and the manufacture had to 'throw in streams of fixed air until all the alkaline taste is destroyed'.
Johann Jacob Schweppe developed a process to manufacture bottled carbonated mineral water. He founded the Schweppes Company in Geneva in 1783 to sell carbonated water, and relocated his business to London in 1792. His drink soon gained in popularity; among his newfound patrons was Erasmus Darwin. In 1843, the Schweppes company commercialized Malvern Water at the Holywell Spring in the Malvern Hills, and received a royal warrant from King William IV.
It was not long before flavoring was combined with carbonated water. The earliest reference to carbonated ginger beer is in a Practical Treatise on Brewing. published in 1809. The drinking of either natural or artificial mineral water was considered at the time to be a healthy practice, and was promoted by advocates of temperance. Pharmacists selling mineral waters began to add herbs and chemicals to unflavored mineral water. They used birch bark (see birch beer), dandelion, sarsaparilla root, fruit extracts, and other substances.
Phosphate soda
A variant of soda in the United States called "phosphate soda" appeared in the late 1870s. It became one of the most popular soda fountain drinks from 1900 through the 1930s, with the lemon or orange phosphate being the most basic. The drink consists of 1 US fl oz (30 ml) fruit syrup, 1/2 teaspoon of phosphoric acid, and enough carbonated water and ice to fill a glass. This drink was commonly served in pharmacies.
Mass market and industrialization
Soft drinks soon outgrew their origins in the medical world and became a widely consumed product, available cheaply for the masses. By the 1840s, there were more than fifty soft drink manufacturers in London, an increase from just ten in the 1820s. Carbonated lemonade was widely available in British refreshment stalls in 1833, and in 1845, R. White's Lemonade went on sale in the UK. For the Great Exhibition of 1851 held at Hyde Park in London, Schweppes was designated the official drink supplier and sold over a million bottles of lemonade, ginger beer, Seltzer water and soda-water. There was a Schweppes soda water fountain, situated directly at the entrance to the exhibition.
Mixer drinks became popular in the second half of the century. Tonic water was originally quinine added to water as a prophylactic against malaria and was consumed by British officials stationed in the tropical areas of South Asia and Africa. As the quinine powder was so bitter people began mixing the powder with soda and sugar, and a basic tonic water was created. The first commercial tonic water was produced in 1858. The mixed drink gin and tonic also originated in British colonial India, when the British population would mix their medicinal quinine tonic with gin.
The Codd-neck bottle invented in 1872 provided an effective seal, preventing the soft drinks from going 'flat'.
A persistent problem in the soft drinks industry was the lack of an effective sealing of the bottles. Carbonated drink bottles are under great pressure from the gas, so inventors tried to find the best way to prevent the carbon dioxide or bubbles from escaping. The bottles could also explode if the pressure was too great. Hiram Codd devised a patented bottling machine while working at a small mineral water works in the Caledonian Road, Islington, in London in 1870. His Codd-neck bottle was designed to enclose a marble and a rubber washer in the neck. The bottles were filled upside down, and pressure of the gas in the bottle forced the marble against the washer, sealing in the carbonation. The bottle was pinched into a special shape to provide a chamber into which the marble was pushed to open the bottle. This prevented the marble from blocking the neck as the drink was poured. R. White's, by now the biggest soft drinks company in London and south-east England, featured a wide range of drinks on their price list in 1887, all of which were sold in Codd's glass bottles, with choices including strawberry soda, raspberry soda, cherryade and cream soda.
In 1892, the "Crown Cork Bottle Seal" was patented by William Painter, a Baltimore, Maryland machine shop operator. It was the first bottle top to successfully keep the bubbles in the bottle. In 1899, the first patent was issued for a glass-blowing machine for the automatic production of glass bottles. Earlier glass bottles had all been hand-blown. Four years later, the new bottle-blowing machine was in operation. It was first operated by Michael Owens, an employee of Libby Glass Company. Within a few years, glass bottle production increased from 1,400 bottles a day to about 58,000 bottles a day.
In America, soda fountains were initially more popular, and many Americans would frequent the soda fountain daily. Beginning in 1806, Yale University chemistry professor Benjamin Silliman sold soda waters in New Haven, Connecticut. He used a Nooth apparatus to produce his waters. Businessmen in Philadelphia and New York City also began selling soda water in the early 19th century. In the 1830s, John Matthews of New York City and John Lippincott of Philadelphia began manufacturing soda fountains. Both men were successful and built large factories for fabricating fountains. Due to problems in the U.S. glass industry, bottled drinks remained a small portion of the market throughout much of the 19th century. (However, they were known in England. In The Tenant of Wildfell Hall, published in 1848, the caddish Huntingdon, recovering from months of debauchery, wakes at noon and gulps a bottle of soda-water.)
In the early 20th century, sales of bottled soda increased greatly around the world, and in the second half of the 20th century, canned soft drinks became an important share of the market. During the 1920s, "Home-Paks" were invented. "Home-Paks" are the familiar six-pack cartons made from cardboard. Vending machines also began to appear in the 1920s. Since then, soft drink vending machines have become increasingly popular. Both hot and cold drinks are sold in these self-service machines throughout the world.
Consumption
Per capita consumption of soda varies considerably around the world. As of 2014, the top consuming countries per capita were Argentina, the United States, Chile, and Mexico. Developed countries in Europe and elsewhere in the Americas had considerably lower consumption. Annual average consumption in the United States, at 153.5 liters, was about twice that in the United Kingdom (77.7) or Canada (85.3).
In recent years, soda consumption has generally declined in the West. According to one estimate, per capita consumption in the United States reached its peak in 1998 and has continually fallen since. A study in the journal Obesity found that from 2003 to 2014 the proportion of Americans who drank a sugary beverage on a given day fell from approximately 62% to 50% for adults, and from 80% to 61% for children. The decrease has been attributed to, among other factors, an increased awareness of the dangers of obesity, and government efforts to improve diets.
At the same time, soda consumption has increased in some low- or middle-income countries such as Cameroon, Georgia, India and Vietnam as soda manufacturers increasingly target these markets and consumers have increasing discretionary income.
Production
Soft drinks are made by mixing dry or fresh ingredients with water. Production of soft drinks can be done at factories or at home. Soft drinks can be made at home by mixing a syrup or dry ingredients with carbonated water, or by Lacto-fermentation. Syrups are commercially sold by companies such as Soda-Club; dry ingredients are often sold in pouches, in a style of the popular U.S. drink mix Kool-Aid. Carbonated water is made using a soda siphon or a home carbonation system or by dropping dry ice into water. Food-grade carbon dioxide, used for carbonating drinks, often comes from ammonia plants.
Drinks like ginger ale and root beer are often brewed using yeast to cause carbonation.
Of most importance is that the ingredient meets the agreed specification on all major parameters. This is not only the functional parameter (in other words, the level of the major constituent), but the level of impurities, the microbiological status, and physical parameters such as color, particle size, etc.
Some soft drinks contain measurable amounts of alcohol. In some older preparations, this resulted from natural fermentation used to build the carbonation. In the United States, soft drinks (as well as other products such as non-alcoholic beer) are allowed by law to contain up to 0.5% alcohol by volume. Modern drinks introduce carbon dioxide for carbonation, but there is some speculation that alcohol might result from fermentation of sugars in a non-sterile environment. A small amount of alcohol is introduced in some soft drinks where alcohol is used in the preparation of the flavoring extracts such as vanilla extract.
Producers
Market control of the soft drink industry varies on a country-by-country basis. However, PepsiCo and the Coca-Cola Company remain the two largest producers of soft drinks in most regions of the world. In North America, Keurig Dr Pepper and Jones Soda also hold a significant amount of market share.
Health concerns
The over-consumption of sugar-sweetened soft drinks is associated with obesity, hypertension, type 2 diabetes, dental caries, and low nutrient levels. A few experimental studies reported the role sugar-sweetened soft drinks potentially contribute to these ailments, though other studies show conflicting information. According to a 2013 systematic review of systematic reviews, 83.3% of the systematic reviews without reported conflict of interest concluded that sugar-sweetened soft drinks consumption could be a potential risk factor for weight gain.
Obesity and weight-related diseases
From 1977 to 2002, Americans doubled their consumption of sweetened beverages - a trend that was paralleled by doubling the prevalence of obesity. The consumption of sugar-sweetened beverages is associated with weight and obesity, and changes in consumption can help predict changes in weight.
The consumption of sugar-sweetened soft drinks can also be associated with many weight-related diseases, including diabetes, metabolic syndrome, and cardiovascular risk factors.
Dental decay
Most soft drinks contain high concentrations of simple carbohydrates: glucose, fructose, sucrose and other simple sugars. If oral bacteria ferment carbohydrates and produce acids that may dissolve tooth enamel and induce dental decay, then sweetened drinks may increase the risk of dental caries. The risk would be greater if the frequency of consumption is high.
A large number of soda pops are acidic as are many fruits, sauces, and other foods. Drinking acidic drinks over a long period and continuous sipping may erode the tooth enamel. A 2007 study determined that some flavored sparkling waters are as erosive or more so than orange juice.
Using a drinking straw is often advised by dentists as the drink does not come into as much contact with the teeth. It has also been suggested that brushing teeth right after drinking soft drinks should be avoided as this can result in additional erosion to the teeth due to mechanical action of the toothbrush on weakened enamel.
Bone density and bone loss
A 2006 study of several thousand men and women, found that women who regularly drank cola-based sodas (three or more a day) had significantly lower bone mineral density (BMD) of about 4% in the hip compared to women who did not consume colas. The study found that the effect of regular consumption of cola sodas was not significant on men's BMD.
Benzene
In 2006, the United Kingdom Food Standards Agency published the results of its survey of benzene levels in soft drinks, which tested 150 products and found that four contained benzene levels above the World Health Organization (WHO) guidelines for drinking water.
The United States Food and Drug Administration released its own test results of several soft drinks containing benzoates and ascorbic or erythorbic acid. Five tested drinks contained benzene levels above the Environmental Protection Agency's recommended standard of 5 ppb. As of 2006, the FDA stated its belief that "the levels of benzene found in soft drinks and other beverages to date do not pose a safety concern for consumers".
Kidney stones
A study published in the Clinical Journal of the American Society of Nephrology in 2013 concluded that consumption of soft drinks was associated with a 23% higher risk of developing kidney stones.
Mortality, circulatory and digestive diseases
In a 2019 study, 451,743 people from Europe who had a consumption of soft drinks of two or more a day, had a greater chance of all-cause mortality. People who drank artificially sweetened drinks had a higher risk of cardiovascular diseases, and people who drank sugar-sweetened drinks with digestive diseases.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2273 2024-08-26 16:17:38
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2275) Silver Plating
Gist
Silver plating is a process in which other base metals are coated with a layer of silver. The process sounds simple, but it still needs to ensure that the base metal has an even layer of silver to gain that widely known and craved matte-white look.
With proper care and maintenance, 925 sterling silver plated stainless steel jewelry can last for several years or more. Regular cleaning with a soft cloth and mild soap, and storing the jewelry in a dry and safe place, can help to preserve its beauty and longevity.
Silver tarnish occurs when the silver plating is exposed to air or water containing an oxidant and a source of sulfur. This chemical reaction is what forms the silver sulfide on the surface of the part and can turn the white luster finish to a yellow or sometimes a black or brown.
Summary:
What Are The Benefits Of Silver Plating?
Silver plating has been around since the 18th century, when it was used to create cheaper versions of household items that would otherwise be made of solid silver, such as cutlery and candlesticks. Silver plating is a very popular metal finishing choice for many industries including medical, automotive, electronics, telecommunications, and many more. In this blog, we discuss why silver electroplating is used and what the key benefits of electroplating with silver are.
What is Silver Plating?
Before we talk about the benefits of silver plating, let’s discuss what exactly the process of silver electroplating involves. Metal plating, also known as metal finishing, is a process used by many manufacturers to coat the surface of an object in a thin layer of metal, such as silver in silver plating. From silver-plated tableware and jewellery, to medical equipment and electrical connectors, silver has the most applications compared to any other plated metal.
What Are The Benefits Of Silver Electroplating?
Due to the unique nature of this metal, silver electroplating offers a range of great benefits. You’ll find plenty of excellent reasons to use silver plating, some of which include:
Resistance To Wear and Corrosion
If you want to create a durable product that is resistant to corrosion, silver is one of your best bets. Adding a silver coating to your metal objects can allow them to become resistant to corrosion, resulting in a sturdier and longer-lasting product.
Thermal And Electrical Conductivity
Silver is known as one of the most conductive metals and possesses a high level of thermal and electrical conductivity, which makes it a perfect coating choice for applications that involve electric and heat such as electronics, automobile manufacture, or aerospace engineering.
Antibacterial And Antimicrobial Properties
Besides silver’s conductive properties, silver also has many other benefits that make it a popular choice when it comes to metal plating. Studies have shown that silver electroplating creates a finish that has antibacterial and antimicrobial properties, making it extremely valuable in medical as well as scientific applications.
Cost-Effective
Silver plating is truly cost-effective and can help reduce manufacturing costs in a number of ways. Coating your products with a silver finish is much cheaper than making them entirely out of this precious metal. In addition, silver is one of the least expensive precious metals, and choosing silver plating over gold plating, for example, can save you quite a bit of money.
What Are The Alternatives to Silver Plating?
Although silver is an excellent coating for a variety of substrates, it may not always be the most suitable metal finish option, depending on the application. You can choose to employ other materials such as gold or copper.
Details
Silver plating is a simple process of coating materials with silver, which is also known as electrolysis.
However, despite its easy-to-understand nature, there are a lot of other essential details you should know about silver plating. You need to understand how the process works, it’s benefits, and where it’s best used, so you’ll know how beneficial this widely used process of plating is for your business.
The Definition of Silver Plating
Silver plating is a process in which other base metals are coated with a layer of silver. The process sounds simple, but it still needs to ensure that the base metal has an even layer of silver to gain that widely known and craved matte-white look.
When the process is performed over nickel silver, the result is usually called electroplated nickel silver.
Besides nickel silver, the process is commonly used on copper, steel, titanium, graphite, ceramic, plastic, and aluminum.
The Benefits of Silver Plating
Silver plating provides several benefits. Due to the strength of silver, this type of coating offers excellent corrosion resistance to the base material and the product as a whole.
Furthermore, silver plating provides great solderability for small parts like kitchen utensils, but it also offers little electrical resistance making it perfect for all products that require an excellent finish and conductivity. A silver finish is also good for the lubricity of the product. Unfortunately, products with a silver finish can still tarnish, but due to the reasonably low price, silver plating is a cheaper alternative to gold plating, which offers similar results.
All in all, silver coating is thus used for products that require:
* Conductivity
* Corrosion resistance
* Wear resistance
* Durability
* Solderability
Depending on the type of usage of the coated material, the silver coating has a different level of thickness.
The Federal standard in the silver coating is QQ-S-365D, which covers electrolytic silver plating over various types of metals. The finish can be either bright, semi-bright, or matte. The brightness of the finish can still depend on the original surface finish of the base material so you might not get the same finish on different products that use diverse materials.
The Uses of Silver Plating
Generally, silver has the most applications across industries when compared to all other plated metals. That makes the process of silver plating indispensable. All of this mostly stems from the fact that silver is the cheapest of all precious metals. When compared to palladium and gold, silver is extremely affordable.
Silver plating is commonly used in several industries and for various popular products:
* Electronics – bearings, semiconductors, connectors
* Power generators – like battery and solar
* Different musical instruments
Electroplated nickel silver, which we already explained, is commonly used to make the finish of spoons, forks, knife handles, and other cutlery.
All in all, silver plating is a popular and widely used form of quality plating across industries. The high conductivity, great solderability, and corrosion resistance make it very useful, especially when it’s price and comparability to gold are taken into account.
It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2274 2024-08-27 00:22:31
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2276) Candy/Cotton Candy
Gist
Cotton candy is a large soft ball of white or pink sugar in the form of thin threads, usually sold on a stick and eaten at fairs and amusement parks.
Summary
Cotton candy, also known as candy floss (candyfloss) and fairy floss, is a spun sugar confection that resembles cotton. It usually contains small amounts of flavoring or food coloring.
It is made by heating and liquefying sugar, and spinning it centrifugally through minute holes, causing it to rapidly cool and re-solidify into fine strands. It is often sold at fairs, circuses, carnivals, and festivals, served in a plastic bag, on a stick, or on a paper cone.
It is made and sold globally, as candy floss in the United Kingdom, Ireland, India, New Zealand, Sri Lanka and South Africa, as fairy floss in Australia, as barbe à papa "daddy's beard" in France, "girl's hair" in the United Arab Emirates and Saudi Arabia, as "girl’s yarn" in Egypt. Similar confections include Korean kkul-tarae and Iranian pashmak.
History
Several sources track the origin of cotton candy to a form of spun sugar found in Europe in the 19th century. At that time, spun sugar was an expensive, labor-intensive endeavor and was not generally available to the average person. Others suggest versions of spun sugar originated in Italy as early as the 15th century.
Machine-spun cotton candy was invented in 1897 by dentist William Morrison and confectioner John C. Wharton, and first introduced to a wide audience at the 1904 World's Fair as Fairy Floss with great success, selling 68,655 boxes at 25¢ ($8.48 today) per box. On September 6, 1905, Albert D. Robinson of Lynn, Massachusetts submitted his patent for an electric candy-spinning machine, a combination of an electronic starter and motor-driven rotatable bowl that maintained heating efficiently. By May 1907, he transferred the rights to the General Electric Company of New York. His patent remains today as the basic cotton candy machine.
In 1915, food writer Julia Davis Chandler described "Candy Cotton" being sold at the Panama–Pacific International Exposition.
Joseph Lascaux, a dentist from New Orleans, Louisiana, invented a similar cotton candy machine in 1921. His patent named the sweet confection "cotton candy", eventually overtaking the name "fairy floss", although it retains this name in Australia. In the 1970s, an automatic cotton candy machine was created which made the product and packaged it, making it easier to produce at carnivals, stalls and other events requiring more portable production.
Tootsie Roll Industries, the world's largest cotton candy manufacturer, produces a bagged, fruit-flavored version called Fluffy Stuff.
In the United States, National Cotton Candy Day is celebrated on December 7.
Production
Typical machines used to make cotton candy include a spinning head enclosing a small "sugar reserve" bowl into which a charge of granulated, colored sugar (or separate sugar and food coloring) is poured. Heaters near the rim of the head melt the sugar, which is squeezed out through tiny holes by centrifugal force. Colored sugar packaged specially for the process is milled with melting characteristics and a crystal size optimized for the head and heated holes; granulated sugar used in baking contains fine crystals which spin out unmelted, while rock sugar crystals are too large to properly contact the heater, slowing the production of cotton candy.
The molten sugar solidifies in the air and is caught in a larger bowl which totally surrounds the spinning head. Left to operate for a period, the cotton-like product builds up on the inside walls of the larger bowl, at which point machine operators twirl a stick or cone around the rim of the large catching bowl, gathering the sugar strands into portions which are served on stick or cone, or in plastic bags. As the sugar reserve bowl empties, the operator recharges it with more feedstock. The product is sensitive to humidity, and in humid summer locales, the process can be messy and sticky.
Flavoring
The source material for candy mesh is usually both colored and flavored. When spun, cotton candy is white because it is made from sugar, but adding dye or coloring transforms the color. Originally, cotton candy was just white. In the US, cotton candy is available in a wide variety of flavors, but two flavor-blend colors predominate—blue raspberry and pink vanilla, both originally formulated by the Gold Medal brand (which uses the names "Boo Blue" and "Silly Nilly"). Cotton candy may come out purple when mixed. Cotton candy machines were notoriously unreliable until Gold Medal's invention of a sprung base in 1949—since then, they have manufactured nearly all commercial cotton candy machines and much of the cotton candy in the US.
Typically, once spun, cotton candy is only marketed by color. Absent a clear name other than "blue", the distinctive taste of the blue raspberry flavor mix has gone on to become a compound flavor that some other foods (gum, ice cream, rock candy, fluoride toothpaste) occasionally borrow ("cotton-candy flavored ice cream") to invoke the nostalgia of cotton candy. The sale of blue cotton candy at fairgrounds in the 1950s is one of the first documented instances of blue-raspberry flavoring in America. Pink bubble gum went through a similar transition from specific branded product to a generic flavor that transcended the original confection, and "bubble gum flavor" often shows up in the same product categories as "cotton candy flavor".
Machines
In 1978, the first automated machine was used for the production of cotton candy. Since then, many variants have appeared, ranging in size from counter-top to party- and carnival-size. Modern machines for commercial use can hold up to 3 pounds (1.4 kg) of sugar, have storage for extra flavors, and have bowls that spin at 3,450 revolutions per minute.
Banned
In February 2024, state of Tamil Nadu in India and Union of Puducherry implemented a ban after lab tests confirmed the presence of a cancer-causing substance, Rhodamine-B, in samples sent for testing. Andhra Pradesh reportedly started testing samples of the candy while food safety officials in Delhi were pushing for a ban.
Studies have shown that the chemical can increase the risk of cancer and Europe and California have made its use as a food dye illegal
Details
Candy, sweet food product, the main constituent of which generally is sugar. The application of the terms candy and confectionery varies among English-speaking countries. In the United States candy refers to both chocolate products and sugar-based confections; elsewhere “chocolate confectionery” refers to chocolates, “sugar confectionery” to the various sugar-based products, and “flour confectionery” to products such as cakes and pastries. This article is primarily concerned with sugar confectionery. Other types of confections are discussed in the articles baking and cocoa.
History
Egyptian hieroglyphics dating back at least 3,000 years indicate that the art of sugar confectionery was already established. The confectioner was regarded as a skilled craftsman by the Romans, and a confectioner’s kitchen excavated at Herculaneum was equipped with pots, pans, and other implements similar to those in use today.
Early confectioners, not having sugar, used honey as a sweetener and mixed it with various fruits, nuts, herbs, and spices.
During the Middle Ages the Persians spread sugarcane cultivation, developed refining methods, and began to make a sugar-based candy. A small amount of sugar was available in Europe during the Middle Ages and was used in the manufacture of the confections prepared and sold mainly by apothecaries. The Venetians brought about a major change in candy manufacture during the 14th century, when they began to import sugar from Arabia. By the 16th century confectioners were manufacturing sweets by molding boiled sugar with fruits and nuts into fanciful forms by simple hand methods. The development of candy-manufacturing machinery began in the late 18th century.
Ingredients:
Sweeteners
Sugar, mainly sucrose from sugar beets or sugarcane, is the major constituent of most candies. Other sweeteners employed in candy manufacture include corn syrup, corn sugar, honey, molasses, maple sugar, and noncaloric sweeteners. Sweeteners may be used in dry or liquid form.
Invert sugar, a mixture of glucose (dextrose) and fructose produced from sugar (sucrose) by application of heat and an acid “sugar doctor,” such as cream of tartar or citric acid, affects the sweetness, solubility, and amount of crystallization in candymaking. Invert sugar is also prepared as a syrup of about 75 percent concentration by the action of acid or enzymes on sugar in solution.
Texturizers and flavourings
Because of the perishability of fresh fluid milk and milk products, milk is usually used in concentrated or dried form. It contributes to candy flavour, colour, and texture. Fats, usually of vegetable origin, are primarily used to supply textural and “mouth feel” properties (lubrication and smoothness). They are also used to control crystallization and to impart plasticity. Such colloids as gelatin, pectin, and egg albumin are employed as emulsifying agents, maintaining fat distribution and providing aeration. Other ingredients include fruits; nuts; natural, fortified, and artificial flavours; and colourings.
Products
Candies can be divided into noncrystalline, or amorphous, and crystalline types. Noncrystalline candies, such as hard candies, caramels, toffees, and nougats, are chewy or hard, with homogeneous structure. Crystalline candies, such as fondant and fudge, are smooth, creamy, and easily chewed, with a definite structure of small crystals.
Sugar has the property of forming a type of noncrystalline “glass” that forms the basis of hard candy products. Sugar and water are boiled until the concentration of the solution reaches a high level, and supersaturation persists upon cooling. This solution takes a plastic form and on further cooling becomes a hard, transparent, glassy mass containing less than 2 percent water.
High-boiled sugar solutions are unstable, however, and will readily crystallize unless preventative steps are taken. Control of modern sugar-boiling processes is precise. Crystallization is prevented by adding either manufactured invert sugar or corn syrup. The latter is now favoured because it contains complex saccharides and dextrins that, in addition to increasing solubility, give greater viscosity, considerably retarding crystallization.
Hard candy manufacture
Originally, hard candy syrups were boiled over a coke or gas fire. Modern manufacturers use pans jacketed with high-pressure steam for batch boiling. Special steam-pressure cookers through which syrup passes continuously are used when a constant supply is required. For flavouring and colouring, the batch of boiled syrup is turned out on a table to cool. While still plastic, the ingredients are kneaded into the batch; this may be done mechanically. In continuous production, flavours may be added to the hot liquid syrup. Especially prepared “sealed” flavours are then required to prevent loss by evaporation.
After flavouring, the plastic mass is shaped by passing through rollers with impressions or through continuous forming machines that produce a “rope” of plastic sugar. By feeding a soft filling into the rope as a core, “bonbons” are made.
A satinlike finish may be obtained by “pulling” the plastic sugar. This consists of stretching the plastic mass on rotating arms and at the same time repeatedly overlapping. With suitable ratios of sugar to corn syrup, pulling will bring about partial crystallization and a short, spongy texture will result.
Caramels and toffee
The manufacture of caramel and toffee resembles hard candy making except that milk and fat are added.
Sweetened, condensed, or evaporated milk is usually employed. Fats may be either butter or vegetable oil, preferably emulsified with milk or with milk and some of the syrup before being added to the whole batch. Emulsifiers such as lecithin or glyceryl monostearate are particularly valuable in continuous processes. The final moisture content of toffee and particularly of caramels is higher than that of hard candy. Because milk and fat are present, the texture is plastic at normal temperatures. The action of heat on the milk solids, in conjunction with the sugar ingredients, imparts the typical flavour and colour to these candies. This process is termed caramelization.
Because caramel is plastic at lower temperatures than hard candy, it may be extruded. Machines eject the plastic caramel under pressure from a row of orifices; the resulting “ropes” are then cut into lengths. Under continuous manufacturing, all ingredients are metred in recipe quantities into a container that gives an initial boil. Then the mixed syrup is pumped first into a continuous cooker that reduces the moisture content to its final level, and finally into a temporary holding vessel in which increased caramelization occurs, permitting the flavour obtained by the batch process to be matched. The cooked caramel is then cooled, extruded, and cut.
Nougat
Although their consistency is similar to that of caramels, nougats usually do not contain milk. They are aerated by vigorously mixing a solution of egg albumin or other similar protein into boiled syrup; a less sticky product is obtained by mixing in some vegetable fat. Egg albumin is a powdered ingredient especially prepared from egg whites by a process of partial fermentation and low-temperature drying. Great care is needed to obtain a product that is readily soluble in water, will keep well, and is free from bacterial contamination. Milk and soy proteins are also used in making aerated confections, generally as partial replacements for egg. Like caramel, nougat may be made in a variety of textures and can be extruded. Soft, well-aerated nougats have become a very popular sweet, particularly as chocolate-covered bars. In some countries soft nougats are known as nougatine.
Gelatin is also used to produce a nougat with chewy texture. Hard nougat has a moisture content of 5 to 7 percent; in soft nougats it may be as high as 9 to 10 percent. The usual procedure of manufacture is first to make a “frappé,” which is prepared by dissolving egg albumin in water, mixing with syrup, and whipping to a light foam. A separate batch of syrup consisting of sugar and corn syrup is boiled to between 135 and 140 °C (275 and 285 °F), depending on the texture desired, then beaten vigorously with the frappé. Toward the end of the beating, some fat, powdered sugar, or fondant may be added to obtain a shorter texture.
Continuous nougat-manufacturing equipment prepares the frappé by feeding in measured amounts of egg solution, syrup, and air under pressure, then beating it. Through a valve, the frappé is delivered into a metered flow of boiled syrup; the two are mixed in a trough with a rotating screw that carries the mixture continuously forward. Other ingredients, such as fat, flavour, or nuts, also may be fed into the screw toward the end of the mixing process.
Fondant
Fondant, the basis of most chocolate-covered and crystallized crèmes (which themselves are sometimes called “fondants”), is made by mechanically beating a solution supersaturated with sugar, so that minute sugar crystals are deposited throughout the remaining syrup phase. These form an opaque, white, smooth paste that can be melted, flavoured, and coloured. Syrup made from corn syrup and sugar is now generally used for fondant.
Fully mechanical plants produce a ton of fondant per hour. Syrup, produced in a continuous cooker, is delivered to a rotating drum that is cooled internally with water sprays. The cooled syrup is scraped from the drum and delivered to a beater consisting of a water-cooled, rectangular box fitted internally with rotating pegged spindles and baffles. This gives maximum agitation while the syrup is cooling, causing very fine sugar crystals to be deposited in the syrup phase. The crystals, together with a small amount of air entrapped by the beating, give the fondant its typical white opacity. The proportion of sugar to corn syrup in the base syrup usually ranges from 3:1 to 4:1. The moisture content of fondant ranges from 12 to 13 percent.
Mechanically prepared fondant can be reheated without complete solution of the sugar-crystal phase, and it will be sufficiently fluid to be cast into molds. At the same time colourings and flavourings—fruit pulp, jam, essential oils, etc.—may be added. Remelting is usually carried out in steam-jacketed kettles provided with stirrers at a temperature range between 65 and 75 °C (145 and 155 °F). To produce light-textured fondants, 5 to 10 percent of frappé, made as described under Nougat, is added to the preparation.
Shaped pieces of fondant for crystallizing or covering with chocolate are formed by pouring the hot, melted, flavoured fondant into impressions made in cornstarch. A shallow tray about two inches deep is filled with cornstarch, which is leveled off and slightly compressed. A printing board covered with rows of plaster, wood, or metal models of the desired shape is then pressed into the starch and withdrawn. Into these impressions the fondant is poured and left to cool. Next, the tray is inverted over a sieve; the starch passes through, leaving the fondant pieces on the sieve. After gentle brushing or blowing to remove adhering starch, the fondants are ready for covering or crystallizing. A machine known as a Mogul carries out all these operations automatically, filling trays with starch, printing them, depositing melted fondant, and stacking the filled trays into a pile. At the other end of the machine, piles of trays that contain cooled and set crèmes are unstacked and inverted over sieves, and the crèmes are removed to be brushed and air-blown. Empty trays are automatically refilled, and the cycle continues.
Certain types of fondant may be remelted and poured into flexible rubber molds with impressions, but this process generally is limited to shallow crèmes of a fairly rigid consistency. Metal molds precoated with a substance that facilitates release of the crème also are used. The crème units are ejected from the inverted mold by compressed air onto a belt, which takes them forward for chocolate covering.
Fudge
Fudge combines certain properties of caramel with those of fondant. If hot caramel is vigorously mixed or if fondant is added to it, a smooth, crystalline paste forms on cooling. Known as fudge, this substance has a milky flavour similar to caramel and a soft, not plastic, texture. Fudge may be extruded or poured onto tables and cut into shapes. It is possible to construct a recipe that will pour into starch, but such fudge generally is inferior.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#2275 2024-08-27 22:43:51
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,831
Re: Miscellany
2275) Clock
Gist
A clock is a device other than a watch for indicating or measuring time commonly by means of hands moving on a dial.
Details
A clock or chronometer is a device that measures and displays time. The clock is one of the oldest human inventions, meeting the need to measure intervals of time shorter than the natural units such as the day, the lunar month, and the year. Devices operating on several physical processes have been used over the millennia.
Some predecessors to the modern clock may be considered "clocks" that are based on movement in nature: A sundial shows the time by displaying the position of a shadow on a flat surface. There is a range of duration timers, a well-known example being the hourglass. Water clocks, along with sundials, are possibly the oldest time-measuring instruments. A major advance occurred with the invention of the verge escapement, which made possible the first mechanical clocks around 1300 in Europe, which kept time with oscillating timekeepers like balance wheels.
Traditionally, in horology (the study of timekeeping), the term clock was used for a striking clock, while a clock that did not strike the hours audibly was called a timepiece. This distinction is not generally made any longer. Watches and other timepieces that can be carried on one's person are usually not referred to as clocks. Spring-driven clocks appeared during the 15th century. During the 15th and 16th centuries, clockmaking flourished. The next development in accuracy occurred after 1656 with the invention of the pendulum clock by Christiaan Huygens. A major stimulus to improving the accuracy and reliability of clocks was the importance of precise time-keeping for navigation. The mechanism of a timepiece with a series of gears driven by a spring or weights is referred to as clockwork; the term is used by extension for a similar mechanism not used in a timepiece. The electric clock was patented in 1840, and electronic clocks were introduced in the 20th century, becoming widespread with the development of small battery-powered semiconductor devices.
The timekeeping element in every modern clock is a harmonic oscillator, a physical object (resonator) that vibrates or oscillates at a particular frequency. This object can be a pendulum, a balance wheel, a tuning fork, a quartz crystal, or the vibration of electrons in atoms as they emit microwaves, the last of which is so precise that it serves as the definition of the second.
Clocks have different ways of displaying the time. Analog clocks indicate time with a traditional clock face and moving hands. Digital clocks display a numeric representation of time. Two numbering systems are in use: 12-hour time notation and 24-hour notation. Most digital clocks use electronic mechanisms and LCD, LED, or VFD displays. For the blind and for use over telephones, speaking clocks state the time audibly in words. There are also clocks for the blind that have displays that can be read by touch.
Etymology
The word clock derives from the medieval Latin word for 'bell'—clocca—and has cognates in many European languages. Clocks spread to England from the Low Countries, so the English word came from the Middle Low German and Middle Dutch Klocke. The word derives from the Middle English clokke, Old North French cloque, or Middle Dutch clocke, all of which mean 'bell'.History of time-measuring devices
History of timekeeping devices:
Sundials
The apparent position of the Sun in the sky changes over the course of each day, reflecting the rotation of the Earth. Shadows cast by stationary objects move correspondingly, so their positions can be used to indicate the time of day. A sundial shows the time by displaying the position of a shadow on a (usually) flat surface that has markings that correspond to the hours. Sundials can be horizontal, vertical, or in other orientations. Sundials were widely used in ancient times. With knowledge of latitude, a well-constructed sundial can measure local solar time with reasonable accuracy, within a minute or two. Sundials continued to be used to monitor the performance of clocks until the 1830s, when the use of the telegraph and trains standardized time and time zones between cities.
Devices that measure duration, elapsed time and intervals
Many devices can be used to mark the passage of time without respect to reference time (time of day, hours, minutes, etc.) and can be useful for measuring duration or intervals. Examples of such duration timers are candle clocks, incense clocks, and the hourglass. Both the candle clock and the incense clock work on the same principle, wherein the consumption of resources is more or less constant, allowing reasonably precise and repeatable estimates of time passages. In the hourglass, fine sand pouring through a tiny hole at a constant rate indicates an arbitrary, predetermined passage of time. The resource is not consumed, but re-used.
Water clocks
Water clocks, along with sundials, are possibly the oldest time-measuring instruments, with the only exception being the day-counting tally stick. Given their great antiquity, where and when they first existed is not known and is perhaps unknowable. The bowl-shaped outflow is the simplest form of a water clock and is known to have existed in Babylon and Egypt around the 16th century BC. Other regions of the world, including India and China, also have early evidence of water clocks, but the earliest dates are less certain. Some authors, however, write about water clocks appearing as early as 4000 BC in these regions of the world.
The Macedonian astronomer Andronicus of Cyrrhus supervised the construction of the Tower of the Winds in Athens in the 1st century BC, which housed a large clepsydra inside as well as multiple prominent sundials outside, allowing it to function as a kind of early clocktower. The Greek and Roman civilizations advanced water clock design with improved accuracy. These advances were passed on through Byzantine and Islamic times, eventually making their way back to Europe. Independently, the Chinese developed their own advanced water clocks by 725 AD, passing their ideas on to Korea and Japan.
Some water clock designs were developed independently, and some knowledge was transferred through the spread of trade. Pre-modern societies do not have the same precise timekeeping requirements that exist in modern industrial societies, where every hour of work or rest is monitored and work may start or finish at any time regardless of external conditions. Instead, water clocks in ancient societies were used mainly for astrological reasons. These early water clocks were calibrated with a sundial. While never reaching the level of accuracy of a modern timepiece, the water clock was the most accurate and commonly used timekeeping device for millennia until it was replaced by the more accurate pendulum clock in 17th-century Europe.
Islamic civilization is credited with further advancing the accuracy of clocks through elaborate engineering. In 797 (or possibly 801), the Abbasid caliph of Baghdad, Harun al-Rashid, presented Charlemagne with an Asian elephant named Abul-Abbas together with a "particularly elaborate example" of a water clock. Pope Sylvester II introduced clocks to northern and western Europe around 1000 AD.
Mechanical water clocks
The first known geared clock was invented by the great mathematician, physicist, and engineer Archimedes during the 3rd century BC. Archimedes created his astronomical clock, which was also a cuckoo clock with birds singing and moving every hour. It is the first carillon clock as it plays music simultaneously with a person blinking his eyes, surprised by the singing birds. The Archimedes clock works with a system of four weights, counterweights, and strings regulated by a system of floats in a water container with siphons that regulate the automatic continuation of the clock. The principles of this type of clock are described by the mathematician and physicist Hero, who says that some of them work with a chain that turns a gear in the mechanism. Another Greek clock probably constructed at the time of Alexander was in Gaza, as described by Procopius. The Gaza clock was probably a Meteoroskopeion, i.e., a building showing celestial phenomena and the time. It had a pointer for the time and some automations similar to the Archimedes clock. There were 12 doors opening one every hour, with Hercules performing his labors, the Lion at one o'clock, etc., and at night a lamp becomes visible every hour, with 12 windows opening to show the time.
The Tang dynasty Buddhist monk Yi Xing along with government official Liang Lingzan made the escapement in 723 (or 725) to the workings of a water-powered armillary sphere and clock drive, which was the world's first clockwork escapement. The Song dynasty polymath and genius Su Song (1020–1101) incorporated it into his monumental innovation of the astronomical clock tower of Kaifeng in 1088. His astronomical clock and rotating armillary sphere still relied on the use of either flowing water during the spring, summer, and autumn seasons or liquid mercury during the freezing temperatures of winter (i.e., hydraulics). In Su Song's waterwheel linkwork device, the action of the escapement's arrest and release was achieved by gravity exerted periodically as the continuous flow of liquid-filled containers of a limited size. In a single line of evolution, Su Song's clock therefore united the concepts of the clepsydra and the mechanical clock into one device run by mechanics and hydraulics. In his memorial, Su Song wrote about this concept:
According to your servant's opinion there have been many systems and designs for astronomical instruments during past dynasties all differing from one another in minor respects. But the principle of the use of water-power for the driving mechanism has always been the same. The heavens move without ceasing but so also does water flow (and fall). Thus if the water is made to pour with perfect evenness, then the comparison of the rotary movements (of the heavens and the machine) will show no discrepancy or contradiction; for the unresting follows the unceasing.
Song was also strongly influenced by the earlier armillary sphere created by Zhang Sixun (976 AD), who also employed the escapement mechanism and used liquid mercury instead of water in the waterwheel of his astronomical clock tower. The mechanical clockworks for Su Song's astronomical tower featured a great driving-wheel that was 11 feet in diameter, carrying 36 scoops, into each of which water was poured at a uniform rate from the "constant-level tank". The main driving shaft of iron, with its cylindrical necks supported on iron crescent-shaped bearings, ended in a pinion, which engaged a gear wheel at the lower end of the main vertical transmission shaft. This great astronomical hydromechanical clock tower was about ten metres high (about 30 feet), featured a clock escapement, and was indirectly powered by a rotating wheel either with falling water or liquid mercury. A full-sized working replica of Su Song's clock exists in the Republic of China (Taiwan)'s National Museum of Natural Science, Taichung city. This full-scale, fully functional replica, approximately 12 meters (39 feet) in height, was constructed from Su Song's original descriptions and mechanical drawings. The Chinese escapement spread west and was the source for Western escapement technology.
In the 12th century, Al-Jazari, an engineer from Mesopotamia (lived 1136–1206) who worked for the Artuqid king of Diyar-Bakr, Nasir al-Din, made numerous clocks of all shapes and sizes. The most reputed clocks included the elephant, scribe, and castle clocks, some of which have been successfully reconstructed. As well as telling the time, these grand clocks were symbols of the status, grandeur, and wealth of the Urtuq State. Knowledge of these mercury escapements may have spread through Europe with translations of Arabic and Spanish texts.
Fully mechanical
The word horologia (from the Greek —'hour', and —'to tell') was used to describe early mechanical clocks, but the use of this word (still used in several Romance languages) for all timekeepers conceals the true nature of the mechanisms. For example, there is a record that in 1176, Sens Cathedral in France installed an 'horologe', but the mechanism used is unknown. According to Jocelyn de Brakelond, in 1198, during a fire at the abbey of St Edmundsbury (now Bury St Edmunds), the monks "ran to the clock" to fetch water, indicating that their water clock had a reservoir large enough to help extinguish the occasional fire. The word clock (via Medieval Latin clocca from Old Irish clocc, both meaning 'bell'), which gradually supersedes "horologe", suggests that it was the sound of bells that also characterized the prototype mechanical clocks that appeared during the 13th century in Europe.
In Europe, between 1280 and 1320, there was an increase in the number of references to clocks and horologes in church records, and this probably indicates that a new type of clock mechanism had been devised. Existing clock mechanisms that used water power were being adapted to take their driving power from falling weights. This power was controlled by some form of oscillating mechanism, probably derived from existing bell-ringing or alarm devices. This controlled release of power – the escapement – marks the beginning of the true mechanical clock, which differed from the previously mentioned cogwheel clocks. The verge escapement mechanism appeared during the surge of true mechanical clock development, which did not need any kind of fluid power, like water or mercury, to work.
These mechanical clocks were intended for two main purposes: for signalling and notification (e.g., the timing of services and public events) and for modeling the solar system. The former purpose is administrative; the latter arises naturally given the scholarly interests in astronomy, science, and astrology and how these subjects integrated with the religious philosophy of the time. The astrolabe was used both by astronomers and astrologers, and it was natural to apply a clockwork drive to the rotating plate to produce a working model of the solar system.
Simple clocks intended mainly for notification were installed in towers and did not always require faces or hands. They would have announced the canonical hours or intervals between set times of prayer. Canonical hours varied in length as the times of sunrise and sunset shifted. The more sophisticated astronomical clocks would have had moving dials or hands and would have shown the time in various time systems, including Italian hours, canonical hours, and time as measured by astronomers at the time. Both styles of clocks started acquiring extravagant features, such as automata.
In 1283, a large clock was installed at Dunstable Priory in Bedfordshire in southern England; its location above the rood screen suggests that it was not a water clock. In 1292, Canterbury Cathedral installed a 'great horloge'. Over the next 30 years, there were mentions of clocks at a number of ecclesiastical institutions in England, Italy, and France. In 1322, a new clock was installed in Norwich, an expensive replacement for an earlier clock installed in 1273. This had a large (2 metre) astronomical dial with automata and bells. The costs of the installation included the full-time employment of two clockkeepers for two years.
Astronomical
An elaborate water clock, the 'Cosmic Engine', was invented by Su Song, a Chinese polymath, designed and constructed in China in 1092. This great astronomical hydromechanical clock tower was about ten metres high (about 30 feet) and was indirectly powered by a rotating wheel with falling water and liquid mercury, which turned an armillary sphere capable of calculating complex astronomical problems.
In Europe, there were the clocks constructed by Richard of Wallingford in Albans by 1336, and by Giovanni de Dondi in Padua from 1348 to 1364. They no longer exist, but detailed descriptions of their design and construction survive, and modern reproductions have been made. They illustrate how quickly the theory of the mechanical clock had been translated into practical constructions, and also that one of the many impulses to their development had been the desire of astronomers to investigate celestial phenomena.
The Astrarium of Giovanni Dondi dell'Orologio was a complex astronomical clock built between 1348 and 1364 in Padua, Italy, by the doctor and clock-maker Giovanni Dondi dell'Orologio. The Astrarium had seven faces and 107 moving gears; it showed the positions of the sun, the moon and the five planets then known, as well as religious feast days. The astrarium stood about 1 metre high, and consisted of a seven-sided brass or iron framework resting on 7 decorative paw-shaped feet. The lower section provided a 24-hour dial and a large calendar drum, showing the fixed feasts of the church, the movable feasts, and the position in the zodiac of the moon's ascending node. The upper section contained 7 dials, each about 30 cm in diameter, showing the positional data for the Primum Mobile, Venus, Mercury, the moon, Saturn, Jupiter, and Mars. Directly above the 24-hour dial is the dial of the Primum Mobile, so called because it reproduces the diurnal motion of the stars and the annual motion of the sun against the background of stars. Each of the 'planetary' dials used complex clockwork to produce reasonably accurate models of the planets' motion. These agreed reasonably well both with Ptolemaic theory and with observations.
Wallingford's clock had a large astrolabe-type dial, showing the sun, the moon's age, phase, and node, a star map, and possibly the planets. In addition, it had a wheel of fortune and an indicator of the state of the tide at London Bridge. Bells rang every hour, the number of strokes indicating the time. Dondi's clock was a seven-sided construction, 1 metre high, with dials showing the time of day, including minutes, the motions of all the known planets, an automatic calendar of fixed and movable feasts, and an eclipse prediction hand rotating once every 18 years. It is not known how accurate or reliable these clocks would have been. They were probably adjusted manually every day to compensate for errors caused by wear and imprecise manufacture. Water clocks are sometimes still used today, and can be examined in places such as ancient castles and museums. The Salisbury Cathedral clock, built in 1386, is considered to be the world's oldest surviving mechanical clock that strikes the hours.
Spring-driven
Clockmakers developed their art in various ways. Building smaller clocks was a technical challenge, as was improving accuracy and reliability. Clocks could be impressive showpieces to demonstrate skilled craftsmanship, or less expensive, mass-produced items for domestic use. The escapement in particular was an important factor affecting the clock's accuracy, so many different mechanisms were tried.
Spring-driven clocks appeared during the 15th century, although they are often erroneously credited to Nuremberg watchmaker Peter Henlein (or Henle, or Hele) around 1511. The earliest existing spring driven clock is the chamber clock given to Phillip the Good, Duke of Burgundy, around 1430, now in the Germanisches Nationalmuseum. Spring power presented clockmakers with a new problem: how to keep the clock movement running at a constant rate as the spring ran down. This resulted in the invention of the stackfreed and the fusee in the 15th century, and many other innovations, down to the invention of the modern going barrel in 1760.
Early clock dials did not indicate minutes and seconds. A clock with a dial indicating minutes was illustrated in a 1475 manuscript by Paulus Almanus, and some 15th-century clocks in Germany indicated minutes and seconds. An early record of a seconds hand on a clock dates back to about 1560 on a clock now in the Fremersdorf collection.
During the 15th and 16th centuries, clockmaking flourished, particularly in the metalworking towns of Nuremberg and Augsburg, and in Blois, France. Some of the more basic table clocks have only one time-keeping hand, with the dial between the hour markers being divided into four equal parts making the clocks readable to the nearest 15 minutes. Other clocks were exhibitions of craftsmanship and skill, incorporating astronomical indicators and musical movements. The cross-beat escapement was invented in 1584 by Jost Bürgi, who also developed the remontoire. Bürgi's clocks were a great improvement in accuracy as they were correct to within a minute a day. These clocks helped the 16th-century astronomer Tycho Brahe to observe astronomical events with much greater precision than before.
Pendulum
The next development in accuracy occurred after 1656 with the invention of the pendulum clock. Galileo had the idea to use a swinging bob to regulate the motion of a time-telling device earlier in the 17th century. Christiaan Huygens, however, is usually credited as the inventor. He determined the mathematical formula that related pendulum length to time (about 99.4 cm or 39.1 inches for the one second movement) and had the first pendulum-driven clock made. The first model clock was built in 1657 in the Hague, but it was in England that the idea was taken up. The longcase clock (also known as the grandfather clock) was created to house the pendulum and works by the English clockmaker William Clement in 1670 or 1671. It was also at this time that clock cases began to be made of wood and clock faces to use enamel as well as hand-painted ceramics.
In 1670, William Clement created the anchor escapement, an improvement over Huygens' crown escapement. Clement also introduced the pendulum suspension spring in 1671. The concentric minute hand was added to the clock by Daniel Quare, a London clockmaker and others, and the second hand was first introduced.
Hairspring
In 1675, Huygens and Robert Hooke invented the spiral balance spring, or the hairspring, designed to control the oscillating speed of the balance wheel. This crucial advance finally made accurate pocket watches possible. The great English clockmaker Thomas Tompion, was one of the first to use this mechanism successfully in his pocket watches, and he adopted the minute hand which, after a variety of designs were trialled, eventually stabilised into the modern-day configuration. The rack and snail striking mechanism for striking clocks, was introduced during the 17th century and had distinct advantages over the 'countwheel' (or 'locking plate') mechanism. During the 20th century there was a common misconception that Edward Barlow invented rack and snail striking. In fact, his invention was connected with a repeating mechanism employing the rack and snail. The repeating clock, that chimes the number of hours (or even minutes) on demand was invented by either Quare or Barlow in 1676. George Graham invented the deadbeat escapement for clocks in 1720.
Marine chronometer
A major stimulus to improving the accuracy and reliability of clocks was the importance of precise time-keeping for navigation. The position of a ship at sea could be determined with reasonable accuracy if a navigator could refer to a clock that lost or gained less than about 10 seconds per day. This clock could not contain a pendulum, which would be virtually useless on a rocking ship. In 1714, the British government offered large financial rewards to the value of 20,000 pounds for anyone who could determine longitude accurately. John Harrison, who dedicated his life to improving the accuracy of his clocks, later received considerable sums under the Longitude Act.
In 1735, Harrison built his first chronometer, which he steadily improved on over the next thirty years before submitting it for examination. The clock had many innovations, including the use of bearings to reduce friction, weighted balances to compensate for the ship's pitch and roll in the sea and the use of two different metals to reduce the problem of expansion from heat. The chronometer was tested in 1761 by Harrison's son and by the end of 10 weeks the clock was in error by less than 5 seconds.
Mass production
The British had dominated watch manufacture for much of the 17th and 18th centuries, but maintained a system of production that was geared towards high quality products for the elite. Although there was an attempt to modernise clock manufacture with mass-production techniques and the application of duplicating tools and machinery by the British Watch Company in 1843, it was in the United States that this system took off. In 1816, Eli Terry and some other Connecticut clockmakers developed a way of mass-producing clocks by using interchangeable parts. Aaron Lufkin Dennison started a factory in 1851 in Massachusetts that also used interchangeable parts, and by 1861 was running a successful enterprise incorporated as the Waltham Watch Company.
Early electric
In 1815, the English scientist Francis Ronalds published the first electric clock powered by dry pile batteries. Alexander Bain, a Scottish clockmaker, patented the electric clock in 1840. The electric clock's mainspring is wound either with an electric motor or with an electromagnet and armature. In 1841, he first patented the electromagnetic pendulum. By the end of the nineteenth century, the advent of the dry cell battery made it feasible to use electric power in clocks. Spring or weight driven clocks that use electricity, either alternating current (AC) or direct current (DC), to rewind the spring or raise the weight of a mechanical clock would be classified as an electromechanical clock. This classification would also apply to clocks that employ an electrical impulse to propel the pendulum. In electromechanical clocks the electricity serves no time keeping function. These types of clocks were made as individual timepieces but more commonly used in synchronized time installations in schools, businesses, factories, railroads and government facilities as a master clock and slave clocks.
Where an AC electrical supply of stable frequency is available, timekeeping can be maintained very reliably by using a synchronous motor, essentially counting the cycles. The supply current alternates with an accurate frequency of 50 hertz in many countries, and 60 hertz in others. While the frequency may vary slightly during the day as the load changes, generators are designed to maintain an accurate number of cycles over a day, so the clock may be a fraction of a second slow or fast at any time, but will be perfectly accurate over a long time. The rotor of the motor rotates at a speed that is related to the alternation frequency. Appropriate gearing converts this rotation speed to the correct ones for the hands of the analog clock. Time in these cases is measured in several ways, such as by counting the cycles of the AC supply, vibration of a tuning fork, the behaviour of quartz crystals, or the quantum vibrations of atoms. Electronic circuits divide these high-frequency oscillations to slower ones that drive the time display.
Quartz
The piezoelectric properties of crystalline quartz were discovered by Jacques and Pierre Curie in 1880. The first crystal oscillator was invented in 1917 by Alexander M. Nicholson, after which the first quartz crystal oscillator was built by Walter G. Cady in 1921. In 1927 the first quartz clock was built by Warren Marrison and J.W. Horton at Bell Telephone Laboratories in Canada. The following decades saw the development of quartz clocks as precision time measurement devices in laboratory settings—the bulky and delicate counting electronics, built with vacuum tubes at the time, limited their practical use elsewhere. The National Bureau of Standards (now NIST) based the time standard of the United States on quartz clocks from late 1929 until the 1960s, when it changed to atomic clocks. In 1969, Seiko produced the world's first quartz wristwatch, the Astron. Their inherent accuracy and low cost of production resulted in the subsequent proliferation of quartz clocks and watches.
Atomic
Currently, atomic clocks are the most accurate clocks in existence. They are considerably more accurate than quartz clocks as they can be accurate to within a few seconds over trillions of years. Atomic clocks were first theorized by Lord Kelvin in 1879. In the 1930s the development of magnetic resonance created practical method for doing this. A prototype ammonia maser device was built in 1949 at the U.S. National Bureau of Standards (NBS, now NIST). Although it was less accurate than existing quartz clocks, it served to demonstrate the concept. The first accurate atomic clock, a caesium standard based on a certain transition of the caesium-133 atom, was built by Louis Essen in 1955 at the National Physical Laboratory in the UK. Calibration of the caesium standard atomic clock was carried out by the use of the astronomical time scale ephemeris time (ET). As of 2013, the most stable atomic clocks are ytterbium clocks, which are stable to within less than two parts in 1 quintillion (2×{10}^{-18}).
Time display methods:
Analog
Analog clocks usually use a clock face which indicates time using rotating pointers called "hands" on a fixed numbered dial or dials. The standard clock face, known universally throughout the world, has a short "hour hand" which indicates the hour on a circular dial of 12 hours, making two revolutions per day, and a longer "minute hand" which indicates the minutes in the current hour on the same dial, which is also divided into 60 minutes. It may also have a "second hand" which indicates the seconds in the current minute. The only other widely used clock face today is the 24 hour analog dial, because of the use of 24 hour time in military organizations and timetables. Before the modern clock face was standardized during the Industrial Revolution, many other face designs were used throughout the years, including dials divided into 6, 8, 10, and 24 hours. During the French Revolution the French government tried to introduce a 10-hour clock, as part of their decimal-based metric system of measurement, but it did not achieve widespread use. An Italian 6 hour clock was developed in the 18th century, presumably to save power (a clock or watch striking 24 times uses more power).
Another type of analog clock is the sundial, which tracks the sun continuously, registering the time by the shadow position of its gnomon. Because the sun does not adjust to daylight saving time, users must add an hour during that time. Corrections must also be made for the equation of time, and for the difference between the longitudes of the sundial and of the central meridian of the time zone that is being used (i.e. 15 degrees east of the prime meridian for each hour that the time zone is ahead of GMT). Sundials use some or part of the 24 hour analog dial. There also exist clocks which use a digital display despite having an analog mechanism—these are commonly referred to as flip clocks. Alternative systems have been proposed. For example, the "Twelv" clock indicates the current hour using one of twelve colors, and indicates the minute by showing a proportion of a circular disk, similar to a moon phase.
Digital
Digital clocks display a numeric representation of time. Two numeric display formats are commonly used on digital clocks:
* the 24-hour notation with hours ranging 00–23;
* the 12-hour notation with AM/PM indicator, with hours indicated as 12AM, followed by 1AM–11AM, followed by 12PM, followed by 1PM–11PM (a notation mostly used in domestic environments).
Most digital clocks use electronic mechanisms and LCD, LED, or VFD displays; many other display technologies are used as well (cathode-ray tubes, nixie tubes, etc.). After a reset, battery change or power failure, these clocks without a backup battery or capacitor either start counting from 12:00, or stay at 12:00, often with blinking digits indicating that the time needs to be set. Some newer clocks will reset themselves based on radio or Internet time servers that are tuned to national atomic clocks. Since the introduction of digital clocks in the 1960s, there has been a notable decline in the use of analog clocks.
Some clocks, called 'flip clocks', have digital displays that work mechanically. The digits are painted on sheets of material which are mounted like the pages of a book. Once a minute, a page is turned over to reveal the next digit. These displays are usually easier to read in brightly lit conditions than LCDs or LEDs. Also, they do not go back to 12:00 after a power interruption. Flip clocks generally do not have electronic mechanisms. Usually, they are driven by AC-synchronous motors.
Hybrid (analog-digital)
Clocks with analog quadrants, with a digital component, usually minutes and hours displayed analogously and seconds displayed in digital mode.
Auditory
For convenience, distance, telephony or blindness, auditory clocks present the time as sounds. The sound is either spoken natural language, (e.g. "The time is twelve thirty-five"), or as auditory codes (e.g. number of sequential bell rings on the hour represents the number of the hour like the bell, Big Ben). Most telecommunication companies also provide a speaking clock service as well.
Word
Word clocks are clocks that display the time visually using sentences. E.g.: "It's about three o'clock." These clocks can be implemented in hardware or software.
Projection
Some clocks, usually digital ones, include an optical projector that shines a magnified image of the time display onto a screen or onto a surface such as an indoor ceiling or wall. The digits are large enough to be easily read, without using glasses, by persons with moderately imperfect vision, so the clocks are convenient for use in their bedrooms. Usually, the timekeeping circuitry has a battery as a backup source for an uninterrupted power supply to keep the clock on time, while the projection light only works when the unit is connected to an A.C. supply. Completely battery-powered portable versions resembling flashlights are also available.
Tactile
Auditory and projection clocks can be used by people who are blind or have limited vision. There are also clocks for the blind that have displays that can be read by using the sense of touch. Some of these are similar to normal analog displays, but are constructed so the hands can be felt without damaging them. Another type is essentially digital, and uses devices that use a code such as Braille to show the digits so that they can be felt with the fingertips.
Multi-display
Some clocks have several displays driven by a single mechanism, and some others have several completely separate mechanisms in a single case. Clocks in public places often have several faces visible from different directions, so that the clock can be read from anywhere in the vicinity; all the faces show the same time. Other clocks show the current time in several time-zones. Watches that are intended to be carried by travellers often have two displays, one for the local time and the other for the time at home, which is useful for making pre-arranged phone calls. Some equation clocks have two displays, one showing mean time and the other solar time, as would be shown by a sundial. Some clocks have both analog and digital displays. Clocks with Braille displays usually also have conventional digits so they can be read by sighted people.
Additional Information
A clock, mechanical or electrical device other than a watch for displaying time. A clock is a machine in which a device that performs regular movements in equal intervals of time is linked to a counting mechanism that records the number of movements. All clocks, of whatever form—whether 12-hour clocks or 24-hour clocks—are made on this principle.
The origin of the all-mechanical escapement clock is unknown; the first such devices may have been invented and used in monasteries to toll a bell that called the monks to prayers. The first mechanical clocks to which clear references exist were large, weight-driven machines fitted into towers and known today as turret clocks. These early devices struck only the hours and did not have hands or a dial.
The oldest surviving clock in England is that at Salisbury Cathedral, which dates from 1386. A clock erected at Rouen, France, in 1389 is still extant, and one built for Wells Cathedral in England is preserved in the Science Museum in London. The Salisbury clock strikes the hours, and those of Rouen and Wells also have mechanisms for chiming at the quarter hour. These clocks are large, iron-framed structures driven by falling weights attached to a cord wrapped around a drum and regulated by a mechanism known as a verge (or crown wheel) escapement. Their errors probably were as large as a half hour per day. The first domestic clocks were smaller wall-mounted versions of these large public clocks. They appeared late in the 14th century, and few examples have survived; most of them, extremely austere in design, had no cases or means of protection from dust.
About 1450, clockmakers working probably in southern Germany or northern Italy began to make small clocks driven by a spring. These were the first portable timepieces, representing an important landmark in horology. The time-telling dials of these clocks usually had an hour hand only (minute hands did not generally appear until the 1650s) and were exposed to the air; there was normally no form of cover such as a glass until the 17th century, though the mechanism was enclosed, and the cases were made of brass.
About 1581 Galileo noticed the characteristic timekeeping property of the pendulum. The Dutch astronomer and physicist Christiaan Huygens was responsible for the practical application of the pendulum as a time controller in clocks from 1656 onward. Huygens’s invention brought about a great increase in the importance and extent of clock making. Clocks, weight-driven and with short pendulums, were encased in wood and made to hang on the wall, but these new eight-day wall clocks had very heavy weights, and many fell off weak plaster walls and were destroyed. The next step was to extend the case to the floor, and the grandfather clock was born. In 1670 the long, or seconds, pendulum was introduced by English clock makers with the anchor escapement.
Mechanical clocks:
The pendulum
The pendulum is a reliable time measurer because, for small arcs, the time required for a complete swing (period) depends only on the length of the pendulum and is almost independent of the extent of the arc. The length of a pendulum with a period of one second is about 39 inches (990 mm), and an increase in length of 0.001 inch (0.025 mm) will make the clock lose about one second per day. Altering the length of a pendulum is therefore a sensitive means of regulation. The alteration is usually carried out by allowing the bob to rest upon a nut that can be screwed up or down the pendulum rod.
An expansion or contraction of the rod caused by changes of temperature will affect the timekeeping of a pendulum; e.g., a pendulum clock with a steel rod will lose one second a day for a rise in temperature of approximately 4 °F (2.2 °C). For accurate timekeeping, the length of the pendulum must be kept as nearly constant as possible. This may be done in several ways, some of which use the differing coefficients of expansion (the amount of expansion per degree change in temperature) of different metals to obtain a cancelling-out effect. In one popular compensation method, the bob consists of a glass or metal jar containing a suitable amount of mercury. The gridiron pendulum employs rods of different metal, usually brass and steel, while in the zinc-iron tube the pendulum rod is made of concentric tubes of zinc and iron. An improved method, however, is to make the pendulum rod from a special alloy called Invar. This material has such a small coefficient of expansion that small changes of temperature have a negligible effect and can easily be compensated for if required.
In a pendulum clock an escape wheel is allowed to rotate through the pitch of one tooth for each double swing of the pendulum and to transmit an impulse to the pendulum to keep it swinging. An ideal escapement would transmit the impulse without interfering with the free swing, and the impulse should be as uniform as possible. The double three-legged gravity escapement, which achieves the second of these but not the first, was invented by Edmund Beckett, afterward Lord Grimthorpe, and used by him for the great clock at Westminster, now generally known as Big Ben, which was installed in 1859. It became the standard for all really accurate tower clocks.
Escapement
The true innovation of the weight-driven clock was the escapement, the system that mediated the transfer of the energy of the gravitational force acting on the weights to the clock’s counting mechanism. The most common escapement was the verge-and-foliot.
In a typical verge-and-foliot escapement, the weighted rope unwinds from the barrel, turning the toothed escape wheel. Controlling the movement of the wheel is the verge, a vertical rod with pallets at each end. When the wheel turns, the top pallet stops it and causes the foliot, with its regulating weights, to oscillate. This oscillation turns the verge and releases the top pallet. The wheel advances until it is caught again by the bottom pallet, and the process repeats itself. The actions of the escapement stabilize the power of the gravitational force and are what produce the ticktock of weight-driven clocks.
The wheelwork
The wheelwork, or train, of a clock is the series of moving wheels (gears) that transmit motion from a weight or spring, via the escapement, to the minute and hour hands. It is most important that the wheels and pinions be made accurately and the tooth form designed so that the power is transferred as steadily as possible.
In a clock driven by a weight or a spring, the power is first transmitted by the main, or great, wheel. This engages with a pinion (a gear with a small number of teeth designed to mesh with a larger wheel), whose arbor (a turning rod to which gears are attached) is attached to the second wheel that, in its turn, engages with the next pinion, and so on, down through the train to the escapement. The gear ratios are such that one arbor, usually the second or third, rotates once an hour and can be used to carry the minute hand. A simple 12-to-1 gearing, known as the motion work, gives the necessary step-down ratio to drive the hour hand. The spring or weight is fitted with a mechanism so it can be rewound when necessary, and the arbor carrying the minute hand is provided with a simple slipping clutch that allows the hands to be set to the correct time.
The timekeeping part of all weight-driven clocks, including large tower clocks, is substantially the same. The figure shows the mechanism of a simple weight-driven timepiece with a pendulum. The frame is made up of two plates that carry the pivots of the various wheels and other moving parts and that are united and spaced by four pillars. The driving weight hangs from a line coiled around a barrel or sprocket, which is raised by turning the winding square or, in some cases, by pulling on the line. The main wheel engages with the centre pinion, on the arbor (axle) of which is also mounted the centre wheel. The front pivot of this wheel and pinion is lengthened to the right of the illustration; it carries the minute hand and part of the gearing necessary to drive the hour hand.
The centre wheel is also coupled through a suitable gear train to the escape wheel, which engages with the pallets that are fixed to the arbor between the front plate and the pendulum suspension math. Also fixed to the pallet arbor is the crutch, which terminates at its lower end in a fork that embraces the pendulum rod.
The motion work used for driving the hands is mounted between the dial and the front plate of the frame. The cannon pinion, which drives the motion work, rotates once an hour; it is coupled to the centre arbor by a flat spring that acts as a clutch and permits the hands to be set.
Electric clocks
Electric currents can be used to replace the weight or spring as a source of power and as a means of signaling time indications from a central master clock to a wide range of distant indicating dials. Invented in 1840, the first battery electric clock was driven by a spring and pendulum and employed an electrical impulse to operate a number of dials. Considerable experimental work followed, and it was not until 1906 that the first self-contained battery-driven clock was invented.
In a master clock system, electricity is used to give direct impulses to the pendulum, which in turn causes the clock’s gear train to move, or to lift a lever after it has imparted an impulse to the pendulum. In various modern master clocks the pendulum operates a light count wheel that turns through the pitch of one tooth every double swing and is arranged to release a lever every half minute. This lever gives an impulse to the pendulum and is then restored to its original position by an electromagnet. The pulse of current that operates the electromagnet can also be transmitted to a series of distant dials, or slave clocks, advancing the hands of each through the space of a half minute. Thus, a master clock can control scores of dials in a large group of buildings, as well as such other apparatus as time recorders and sirens.
Electric master clocks of this type are good timekeepers, since the impulse can be given symmetrically as the pendulum passes through its middle position and the interference with its motion is small.
With the application of the synchronous electric motor to clocks in 1918, domestic electric clocks became popular. A synchronous electric motor runs in step with the frequency of the electric power source, which in most countries alternates at 60 hertz (cycles per second). The electric motor is coupled to a reduction gearing that drives the clock hands at the correct rate.
The synchronous electric clock has no timekeeping properties in itself and is wholly dependent upon the frequency stability of the alternating current supplied. If this frequency changes, the electric clock will not keep correct time.
The most accurate mechanical timekeeper is the Shortt pendulum clock; it makes use of the movement described above for electric master clock systems. The Shortt pendulum clock consists of two separate clocks, one of which synchronizes the other. The timekeeping element is a pendulum that swings freely, except that once every half minute it receives an impulse from a gently falling lever. This lever is released by an electrical signal transmitted from its slave clock. After the impulse has been sent, a synchronizing signal is transmitted back to the slave clock that ensures that the impulse to the free pendulum will be released exactly a half minute later than the previous impulse. The pendulum swings in a sealed box in which the air is kept at a constant, low pressure. Shortt clocks in observatories are kept in a room, usually a basement, where the temperature remains nearly constant, and under these conditions they can maintain the correct time to within a few thousandths of a second per day.
In 1929 the quartz crystal was first applied to timekeeping; this invention was probably the single greatest contribution to precision time measurement. Quartz crystals oscillating at frequencies of 100,000 hertz can be compared and frequency differences determined to an accuracy of one part in 1010.
The timekeeping element of a quartz clock consists of a ring of quartz about 2.5 inches (63.5 mm) in diameter, suspended by threads and enclosed in a heat-insulated chamber. Electrodes are attached to the surfaces of the ring and connected to an electrical circuit in such a manner as to sustain oscillations. Since the frequency of vibration, 100,000-hertz, is too high for convenient time measurement, it is reduced by a process known as frequency division or demultiplication and applied to a synchronous motor connected to a clock dial through mechanical gearing. If a 100,000 hertz frequency, for example, is subjected to a combined electrical and mechanical gearing reduction of 6,000,000 to 1, then the second hand of the synchronous clock will make exactly one rotation in 60 seconds. The vibrations are so regular that the maximum error of an observatory quartz-crystal clock is only a few ten-thousandths of a second per day, equivalent to an error of one second every 10 years.
It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline