Math Is Fun Forum
You are not logged in.
- Topics: Active | Unanswered
#1601 2022-12-17 00:45:54
- Jai Ganesh
- Administrator

- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1564) Night
Summary
Night (also described as night time, unconventionally spelled as "nite") is the period of ambient darkness from sunset to sunrise during each 24-hour day, when the Sun is below the horizon. The exact time when night begins and ends depends on the location and varies throughout the year, based on factors such as season and latitude.
The word can be used in a different sense as the time between bedtime and morning. In common communication, the word night is used as a farewell ("good night", sometimes shortened to "night"), mainly when someone is going to sleep or leaving.
Astronomical night is the period between astronomical dusk and astronomical dawn when the Sun is between 18 and 90 degrees below the horizon and does not illuminate the sky. As seen from latitudes between about 48.56° and 65.73° north or south of the Equator, complete darkness does not occur around the summer solstice because, although the Sun sets, it is never more than 18° below the horizon at lower culmination, −90° Sun angles occur at the Tropic of Cancer on the December solstice and Tropic of Capricorn on the June solstice, and at the equator on equinoxes. And as seen from latitudes greater than 72° north or south of the equator, complete darkness does not occur both equinoxes because, although the Sun sets, it is never more than 18° below the horizon.
The opposite of night is day (or "daytime", to distinguish it from "day" referring to a 24-hour period). Twilight is the period of night after sunset or before sunrise when the Sun still illuminates the sky when it is below the horizon. At any given time, one side of Earth is bathed in sunlight (the daytime), while the other side is in darkness caused by Earth blocking the sunlight. The central part of the shadow is called the umbra, where the night is darkest.
Natural illumination at night is still provided by a combination of moonlight, planetary light, starlight, zodiacal light, gegenschein, and airglow. In some circumstances, aurorae, lightning, and bioluminescence can provide some illumination. The glow provided by artificial lighting is sometimes referred to as light pollution because it can interfere with observational astronomy and ecosystems.
Details
Duration and geography
On Earth, an average night is shorter than daytime due to two factors. Firstly, the Sun's apparent disk is not a point, but has an angular diameter of about 32 arcminutes (32'). Secondly, the atmosphere refracts sunlight so that some of it reaches the ground when the Sun is below the horizon by about 34'. The combination of these two factors means that light reaches the ground when the center of the solar disk is below the horizon by about 50'. Without these effects, daytime and night would be the same length on both equinoxes, the moments when the Sun appears to contact the celestial equator. On the equinoxes, daytime actually lasts almost 14 minutes longer than night does at the Equator, and even longer towards the poles.
The summer and winter solstices mark the shortest and longest nights, respectively. The closer a location is to either the North Pole or the South Pole, the wider the range of variation in the night's duration. Although daytime and night nearly equalize in length on the equinoxes, the ratio of night to day changes more rapidly at high latitudes than at low latitudes before and after an equinox. In the Northern Hemisphere, Denmark experiences shorter nights in June than India. In the Southern Hemisphere, Antarctica sees longer nights in June than Chile. Both hemispheres experience the same patterns of night length at the same latitudes, but the cycles are 6 months apart so that one hemisphere experiences long nights (winter) while the other is experiencing short nights (summer).
In the region within either polar circle, the variation in daylight hours is so extreme that part of summer sees a period without night intervening between consecutive days, while part of winter sees a period without daytime intervening between consecutive nights.
On other celestial bodies
The phenomenon of day and night is due to the rotation of a celestial body about its axis, creating an illusion of the sun rising and setting. Different bodies spin at very different rates, however. Some may spin much faster than Earth, while others spin extremely slowly, leading to very long days and nights. The planet Venus rotates once every 224.7 days – by far the slowest rotation period of any of the major planets. In contrast, the gas giant Jupiter's sidereal day is only 9 hours and 56 minutes. However, it is not just the sidereal rotation period which determines the length of a planet's day-night cycle but the length of its orbital period as well - Venus has a rotation period of 224.7 days, but a day-night cycle just 116.75 days long due to its retrograde rotation and orbital motion around the Sun. Mercury has the longest day-night cycle as a result of its 3:2 resonance between its orbital period and rotation period - this resonance gives it a day-night cycle that is 176 days long. A planet may experience large temperature variations between day and night, such as Mercury, the planet closest to the sun. This is one consideration in terms of planetary habitability or the possibility of extraterrestrial life.
Effect on life:
Biological
The disappearance of sunlight, the primary energy source for life on Earth, has dramatic effects on the morphology, physiology and behavior of almost every organism. Some animals sleep during the night, while other nocturnal animals, including moths and crickets, are active during this time. The effects of day and night are not seen in the animal kingdom alone – plants have also evolved adaptations to cope best with the lack of sunlight during this time. For example, crassulacean acid metabolism is a unique type of carbon fixation which allows some photosynthetic plants to store carbon dioxide in their tissues as organic acids during the night, which can then be used during the day to synthesize carbohydrates. This allows them to keep their stomata closed during the daytime, preventing transpiration of water when it is precious.
Social
The first constant electric light was demonstrated in 1835. As artificial lighting has improved, especially after the Industrial Revolution, night time activity has increased and become a significant part of the economy in most places. Many establishments, such as nightclubs, bars, convenience stores, fast-food restaurants, gas stations, distribution facilities, and police stations now operate 24 hours a day or stay open as late as 1 or 2 a.m. Even without artificial light, moonlight sometimes makes it possible to travel or work outdoors at night.
Nightlife is a collective term for entertainment that is available and generally more popular from the late evening into the early hours of the morning. It includes pubs, bars, nightclubs, parties, live music, concerts, cabarets, theatre, cinemas, and shows. These venues often require a cover charge for admission. Nightlife entertainment is often more adult-oriented than daytime entertainment.
Cultural and psychological aspects
Night is often associated with danger and evil, because of the psychological connection of night's all-encompassing darkness to the fear of the unknown and darkness's hindrance of a major sensory system (the sense of sight). Nighttime is naturally associated with vulnerability and danger for human physical survival. Criminals, animals, and other potential dangers can be concealed by darkness. Midnight has a particular importance in human imagination and culture.
Upper Paleolithic art was found to show (by Leroi-Gourhan) a pattern of choices where the portrayal of animals that were experienced as dangerous were located at a distance from the entrance of a cave dwelling at a number of different cave locations.
The belief in magic often includes the idea that magic and magicians are more powerful at night. Séances of spiritualism are usually conducted closer to midnight. Similarly, mythical and folkloric creatures such as vampires and werewolves are described as being more active at night. Ghosts are believed to wander around almost exclusively during night-time. In almost all cultures, there exist stories and legends warning of the dangers of night-time. In fact, the Saxons called the darkness of night the "death mist".
The cultural significance of the night in Islam differs from that in Western culture. The Quran was revealed during the Night of Power, the most significant night according to Islam. Muhammad made his famous journey from Mecca to Jerusalem and then to heaven in the night. Another prophet, Abraham came to a realization of the supreme being in charge of the universe at night.
People who prefer to be active during the night-time are called night owls.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1602 2022-12-18 00:58:04
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1565) Dawn
Summary
Dawn is the time that marks the beginning of twilight before sunrise. It is recognized by the appearance of indirect sunlight being scattered in Earth's atmosphere, when the centre of the Sun's disc has reached 18° below the observer's horizon. This morning twilight period will last until sunrise (when the Sun's upper limb breaks the horizon), when direct sunlight outshines the diffused light.
Types of dawn
Dawn begins with the first sight of lightness in the morning, and continues until the Sun breaks the horizon. This morning twilight before sunrise is divided into three categories depending on the amount of sunlight that is present in the sky, which is determined by the angular distance of the centre of the Sun (degrees below the horizon) in the morning. These categories are astronomical, nautical, and civil dawn.
Astronomical dawn
Astronomical dawn begins when the Sun is 18 degrees below the horizon in the morning. Astronomical twilight follows instantly until the Sun is 12 degrees below the horizon. At this point a very small portion of the Sun's rays illuminate the sky and the fainter stars begin to disappear. Astronomical dawn is often indistinguishable from night, especially in areas with light pollution. Astronomical dawn marks the beginning of astronomical twilight, which lasts until nautical dawn.
Nautical dawn
Nautical twilight begins when there is enough illumination for sailors to distinguish the horizon at sea but the sky being too dark to perform outdoor activities. Formally, it begins when the Sun is 12 degrees below the horizon in the morning. The sky becomes light enough to clearly distinguish it from land and water. Nautical dawn marks the start of nautical twilight, which lasts until civil dawn.
Civil dawn
Civil dawn begins when there is enough light for most objects to be distinguishable, so that some outdoor activities can commence. Formally, it occurs when the Sun is 6 degrees below the horizon in the morning.
If the sky is clear, it is blue colored, and if there is some cloud or haze, there can be bronze, orange and yellow colours. Some bright stars and planets such as Venus and Jupiter are visible to the naked eye at civil dawn. This moment marks the start of civil twilight, which lasts until sunrise.
Effects of latitude
The duration of the twilight period (e.g. between astronomical dawn and sunrise) varies greatly depending on the observer's latitude: from a little over 70 minutes at the Equator, to many hours in the polar regions.
The Equator
The period of twilight is shortest at the Equator, where the equinox Sun rises due east and sets due west, at a right angle to the horizon. Each stage of twilight (civil, nautical, and astronomical) lasts only 24 minutes. From anywhere on Earth, the twilight period is shortest around the equinoxes and longest on the solstices.
Polar regions
Daytime becomes longer as the summer solstice approaches, while nighttime gets longer as the winter solstice approaches. This can have a potential impact on the times and durations of dawn and dusk. This effect is more pronounced closer to the poles, where the Sun rises at the vernal equinox and sets at the autumn equinox, with a long period of twilight, lasting for a few weeks.
The polar circle (at 66°34′ north or south) is defined as the lowest latitude at which the Sun does not set at the summer solstice. Therefore, the angular radius of the polar circle is equal to the angle between Earth's equatorial plane and the ecliptic plane. This period of time with no sunset lengthens closer to the pole.
Near the summer solstice, latitudes higher than 54°34′ get no darker than nautical twilight; the "darkness of the night" varies greatly at these latitudes.
At latitudes higher than about 60°34, summer nights get no darker than civil twilight. This period of "bright nights" is longer at higher latitudes.
Example
Around the summer solstice, Glasgow, Scotland at 55°51′ N, and Copenhagen, Denmark at 55°40′ N, get a few hours of "night feeling". Oslo, Norway at 59°56′ N, and Stockholm, Sweden at 59°19′ N, seem very bright when the Sun is below the horizon. When the Sun gets 9.0 to 9.5 degrees below the horizon (at summer solstice this is at latitudes 57°30′–57°00′), the zenith gets dark even on cloud-free nights (if there is no full moon), and the brightest stars are clearly visible in a large majority of the sky.
Mythology and religion
In Islam, Zodiacal Light (or "false dawn") is referred to as False Morning and astronomical dawn is called Sahar or True Morning, and it is the time of first prayer of the day, and the beginning of the daily fast during Ramadan.
Many Indo-European mythologies have a dawn goddess, separate from the male Solar deity, her name deriving from PIE *h2ausos-, derivations of which include Greek Eos, Roman Aurora and Indian Ushas. Also related is Lithuanian Aušrinė, and possibly a Germanic *Austrōn- (whence the term Easter). In Sioux mythology, Anpao is an entity with two faces.
The Hindu dawn deity Ushas is female, whereas Surya, the Sun, and Aruṇa, the Sun's charioteer, are male. Ushas is one of the most prominent Rigvedic deities. The time of dawn is also referred to as the Brahmamuhurtham (Brahma is the God of creation and muhurtham is a Hindu unit of time), and is considered an ideal time to perform spiritual activities, including meditation and yoga. In some parts of India, both Usha and Pratyusha (dusk) are worshiped along with the Sun during the festival of Chhath.
Jesus in the Bible is often symbolized by dawn in the morning, also when Jesus rose on the third day it happened during the morning. Prime is the fixed time of prayer of the traditional Divine Office (Canonical Hours) in Christian liturgy, said at the first hour of daylight. Associated with Jesus, in Christianity, Christian burials take place in the direction of dawn.
In Judaism, the question of how to calculate dawn (Hebrew Alos/Alot HaShachar, or Alos/Alot) is posed by the Talmud, as it has many ramifications for Jewish law (such as the possible start time for certain daytime commandments, like prayer). The simple reading of the Talmud is that dawn takes place 72 minutes before sunrise. Others, including the Vilna Gaon, have the understanding that the Talmud's timeframe for dawn was referring specifically to an equinox day in Mesopotamia, and is therefore teaching that dawn should be calculated daily as commencing when the Sun is 16.1 degrees below the horizon. The longstanding practice among most Sephardic Jews is to follow the first opinion, while many Ashkenazi Jews follow the latter view.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1603 2022-12-19 00:03:21
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1566) Dusk
Summary
Dusk is the time just before night when the daylight has almost gone but when it is not completely dark.
Details
Dusk occurs at the darkest stage of twilight, or at the very end of astronomical twilight after sunset and just before nightfall. At predusk, during early to intermediate stages of twilight, enough light in the sky under clear conditions may occur to read outdoors without artificial illumination; however, at the end of civil twilight (when Earth rotates to a point at which the center of the Sun's disk is 6° below the local horizon), such lighting is required to read outside. The term dusk usually refers to astronomical dusk, or the darkest part of twilight before night begins.
Technical definitions
Civil, nautical, and astronomical twilight. Dusk is the darkest part of evening twilight.
The time of dusk is the moment at the very end of astronomical twilight, just before the minimum brightness of the night sky sets in, or may be thought of as the darkest part of evening twilight.However, technically, the three stages of dusk are as follows:
* At civil dusk, the center of the Sun's disc goes 6° below the horizon in the evening. It marks the end of civil twilight, which begins at sunset. At this time objects are still distinguishable and depending on weather conditions some stars and planets may start to become visible to the naked eye. The sky has many colors at this time, such as orange and red. Beyond this point artificial light may be needed to carry out outdoor activities, depending on atmospheric conditions and location.
* At nautical dusk, the Sun apparently moves to 12° below the horizon in the evening. It marks the end of nautical twilight, which begins at civil dusk. At this time, objects are less distinguishable, and stars and planets appear to brighten.
* At astronomical dusk, the Sun's position is 18° below the horizon in the evening. It marks the end of astronomical twilight, which begins at nautical dusk. After this time the Sun no longer illuminates the sky, and thus no longer interferes with astronomical observations.
Media
Dusk can be used to create an ominous tone and has been used as a title for many projects. One instance of this is the 2018 first person shooter Dusk (video game) by New Blood Interactive whose setting is in a similar lighting as the actual time of day.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1604 2022-12-19 21:58:15
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1567) Watermark
Summary
Watermark is a design produced by creating a variation in the thickness of paper fibre during the wet-paper phase of papermaking. This design is clearly visible when the paper is held up to a light source.
Watermarks are known to have existed in Italy before the end of the 13th century. Two types of watermark have been produced. The more common type, which produces a translucent design when held up to a light, is produced by a wire design laid over and sewn onto the sheet mold wire (for handmade paper) or attached to the “dandy roll” (for machine-made paper). The rarer “shaded” watermark is produced by a depression in the sheet mold wire, which results in a greater density of fibres—hence, a shaded, or darker, design when held up to a light. Watermarks are often used commercially to identify the manufacturer or the grade of paper. They have also been used to detect and prevent counterfeiting and forgery.
The notion of watermarks as a means of identification was carried beyond the printing press into the computer age. Digital watermarks, which may or may not be visible, can be added to image and video files so that information embedded in the file is retrievable for purposes of copyright protection. Audio files can also be watermarked in this manner.
Details
A watermark is an identifying image or pattern in paper that appears as various shades of lightness/darkness when viewed by transmitted light (or when viewed by reflected light, atop a dark background), caused by thickness or density variations in the paper. Watermarks have been used on postage stamps, currency, and other government documents to discourage counterfeiting. There are two main ways of producing watermarks in paper; the dandy roll process, and the more complex cylinder mould process.
Watermarks vary greatly in their visibility; while some are obvious on casual inspection, others require some study to pick out. Various aids have been developed, such as watermark fluid that wets the paper without damaging it.
A watermark is very useful in the examination of paper because it can be used for dating documents and artworks, identifying sizes, mill trademarks and locations, and determining the quality of a sheet of paper.
The word is also used for digital practices that share similarities with physical watermarks. In one case, overprint on computer-printed output may be used to identify output from an unlicensed trial version of a program. In another instance, identifying codes can be encoded as a digital watermark for a music, video, picture, or other file.
History
The origin of the water part of a watermark can be found back when a watermark was something that only existed in paper. At that time the watermark was created by changing the thickness of the paper and thereby creating a shadow/lightness in the watermarked paper. This was done while the paper was still wet/watery and therefore the mark created by this process is called a watermark.
Watermarks were first introduced in Fabriano, Italy, in 1282.
Processes:
Dandy roll process
Traditionally, a watermark was made by impressing a water-coated metal stamp onto the paper during manufacturing. The invention of the dandy roll in 1826 by John Marshall revolutionised the watermark process and made it easier for producers to watermark their paper.
The dandy roll is a light roller covered by material similar to window screen that is embossed with a pattern. Faint lines are made by laid wires that run parallel to the axis of the dandy roll, and the bold lines are made by chain wires that run around the circumference to secure the laid wires to the roll from the outside. Because the chain wires are located on the outside of the laid wires, they have a greater influence on the impression in the pulp, hence their bolder appearance than the laid wire lines.
This embossing is transferred to the pulp fibres, compressing and reducing their thickness in that area. Because the patterned portion of the page is thinner, it transmits more light through and therefore has a lighter appearance than the surrounding paper. If these lines are distinct and parallel, and/or there is a watermark, then the paper is termed laid paper. If the lines appear as a mesh or are indiscernible, and/or there is no watermark, then it is called wove paper. This method is called line drawing watermarks.
Cylinder mould process
Another type of watermark is called the cylinder mould watermark. It is a shaded watermark first used in 1848 that incorporates tonal depth and creates a greyscale image. Instead of using a wire covering for the dandy roll, the shaded watermark is created by areas of relief on the roll's own surface. Once dry, the paper may then be rolled again to produce a watermark of even thickness but with varying density. The resulting watermark is generally much clearer and more detailed than those made by the Dandy Roll process, and as such Cylinder Mould Watermark Paper is the preferred type of watermarked paper for banknotes, passports, motor vehicle titles, and other documents where it is an important anti-counterfeiting measure.
On postage stamps
In philately, the watermark is a key feature of a stamp, and often constitutes the difference between a common and a rare stamp. Collectors who encounter two otherwise identical stamps with different watermarks consider each stamp to be a separate identifiable issue. The "classic" stamp watermark is a small crown or other national symbol, appearing either once on each stamp or a continuous pattern. Watermarks were nearly universal on stamps in the 19th and early 20th centuries, but generally fell out of use and are not commonly used on modern U.S. issues, but some countries continue to use them.
Some types of embossing, such as that used to make the "cross on oval" design on early stamps of Switzerland, resemble a watermark in that the paper is thinner, but can be distinguished by having sharper edges than is usual for a normal watermark. Stamp paper watermarks also show various designs, letters, numbers and pictorial elements.
The process of bringing out the stamp watermark is fairly simple. Sometimes a watermark in stamp paper can be seen just by looking at the unprinted back side of a stamp. More often, the collector must use a few basic items to get a good look at the watermark. For example, watermark fluid may be applied to the back of a stamp to temporarily reveal the watermark.
Even using the simple watermarking method described, it can be difficult to distinguish some watermarks. Watermarks on stamps printed in yellow and orange can be particularly difficult to see. A few mechanical devices are also used by collectors to detect watermarks on stamps such as the Morley-Bright watermark detector and the more expensive Safe Signoscope. Such devices can be very useful for they can be used without the application of watermark fluid and also allow the collector to look at the watermark for a longer period of time to more easily detect the watermark.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1605 2022-12-20 20:44:54
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1568) Child
Summary
A child (pl: children) is a human being between the stages of birth and puberty, or between the developmental period of infancy and puberty. The legal definition of child generally refers to a minor, otherwise known as a person younger than the age of majority. Children generally have fewer rights and responsibilities than adults. They are classed as unable to make serious decisions.
Child may also describe a relationship with a parent (such as sons and daughters of any age) or, metaphorically, an authority figure, or signify group membership in a clan, tribe, or religion; it can also signify being strongly affected by a specific time, place, or circumstance, as in "a child of nature" or "a child of the Sixties."
Details:
Healthy Development
The early years of a child’s life are very important for his or her health and development. Healthy development means that children of all abilities, including those with special health care needs, are able to grow up where their social, emotional and educational needs are met. Having a safe and loving home and spending time with family―playing, singing, reading, and talking―are very important. Proper nutrition, exercise, and sleep also can make a big difference.
Effective Parenting Practices
Parenting takes many different forms. However, some positive parenting practices work well across diverse families and in diverse settings when providing the care that children need to be happy and healthy, and to grow and develop well. A recent report looked at the evidence in scientific publications for what works, and found these key ways that parents can support their child’s healthy development:
* Responding to children in a predictable way
* Showing warmth and sensitivity
* Having routines and household rules
* Sharing books and talking with children
* Supporting health and safety
* Using appropriate discipline without harshness
Parents who use these practices can help their child stay healthy, be safe, and be successful in many areas—emotional, behavioral, cognitive, and social. Read more about the report here.
Positive Parenting Tips
Get parenting, health, and safety tips for children from birth through 17 years of age
Developmental Milestones
Skills such as taking a first step, smiling for the first time, and waving “bye-bye” are called developmental milestones. Children reach milestones in how they play, learn, speak, behave, and move (for example, crawling and walking).
Children develop at their own pace, so it’s impossible to tell exactly when a child will learn a given skill. However, the developmental milestones give a general idea of the changes to expect as a child gets older.
As a parent, you know your child best. If your child is not meeting the milestones for his or her age, or if you think there could be a problem with your child’s development, talk with your child’s doctor and share your concerns. Don’t wait.
Learn more about milestones and parenting tips from the National Institutes of Health:
* Normal growth and developmentexternal icon
* Preschoolersexternal icon
* School age children external icon
* Adolescents external icon
* Developmental Monitoring and Screening
Parents, grandparents, early childhood providers, and other caregivers can participate in developmental monitoring, which observes how your child grows and changes over time and whether your child meets the typical developmental milestones in playing, learning, speaking, behaving, and moving.
Developmental screening takes a closer look at how your child is developing. A missed milestone could be a sign of a problem, so when you take your child to a well visit, the doctor, nurse, or another specialist might give your child a brief test, or you will complete a questionnaire about your child.
If the screening tool identifies an area of concern, a formal developmental evaluation may be needed, where a trained specialist takes an in-depth look at a child’s development.
If a child has a developmental delay, it is important to get help as soon as possible. When a developmental delay is not found early, children must wait to get the help they need to do well in social and educational settings.
If You’re Concerned
If your child is not meeting the milestones for his or her age, or you are concerned about your child’s development, talk with your child’s doctor and share your concerns. Don’t wait!
Additional Information
Children thrive when they feel safe, loved and nurtured. For many parents, forming a close bond with their child comes easily. For many others who did not feel cherished, protected or valued during their own childhood, it can be much more of a struggle. The good news is that parenting skills can be learned. Read on to learn why bonding with your little one is crucial to their development and well-being, and some simple ways that you can do it every day.
Why building a relationship with your child matters
Providing your child with love and affection is a pre-requisite for the healthy development of their brain, their self-confidence, capacity to thrive and even their ability to form relationships as they go through life.
You literally cannot give babies ‘too much’ love. There is no such thing as spoiling them by holding them too much or giving them too much attention. Responding to their cues for feeding and comfort makes babies feel secure. When babies are routinely left alone, they think they have been abandoned and so they become more clingy and insecure when their parents return.
When you notice your child’s needs and respond to them in a loving way, this helps your little one to feel at ease. Feeling safe, seen, soothed and secure increases neuroplasticity, the ability of the brain to change and adapt. When a child’s world at home is full of love, they are better prepared to deal with the challenges of the larger world. A positive early bond lays the ground for children to grow up to become happy, independent adults. Loving, secure relationships help build resilience, our ability to cope with challenges and recover from setbacks.
How to bond with your child
* Parenting can be difficult at times and there is no such thing as a perfect parent. But if you can provide a loving and nurturing environment for your child to grow up in and you’re a steady and reliable presence in their life, then you’ll be helping them to have a great start in life. Here are some ways that can help you build a strong connection with your child from the moment you meet.
* Notice what they do. When your baby or young child cries, gestures or babbles, respond appropriately with a hug, eye contact or words. This not only teaches your child that you’re paying attention to them, but it helps to build neural connections in your little one’s brain that support the development of communication and social skills.
* Play together. By playing with your child, you are showing them that they are valued and fun to be around. Give them your full attention when you play games together and enjoy seeing the world from your child’s perspective. When you’re enjoying fun moments and laughing together, your body releases endorphins (“feel-good hormones”) that promote a feeling of well-being for both you and your child.
* Hold them close. Cuddling and having skin-to-skin contact with your baby helps to bring you closer in many ways. Your child will feel comforted by your heartbeat and will even get to know your smell. As your child gets a bit older, hugging them can help them learn to regulate their emotions and manage stress. This is because when a child receives a hug, their brain releases oxytocin – the “feel good” chemical – and calms the release of cortisol, the “stress” chemical.
* Have conversations. Taking interest in what your young child has to say shows them that you care about their thoughts and feelings. This can even start from day one. By talking and softly singing to your newborn, it lets them know that you are close by and paying attention to them. When they make cooing noises, respond with words to help them learn the back and forth of a conversation.
* Respond to their needs. Changing a diaper or nappy, feeding your child and helping them fall asleep reassures them that their needs will be met and that they are safe and cared for. Taking care of your child and meeting their needs is also a great reminder of your ability to support your child.
Above all, enjoy being with your child, make the most of the time together and know that your love and presence go a long way to helping your child thrive.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1606 2022-12-21 13:11:48
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1509) Tower
Summary
A tower is any structure that is relatively tall in proportion to the dimensions of its base. It may be either freestanding or attached to a building or wall. Modifiers frequently denote a tower’s function (e.g., watchtower, water tower, church tower, and so on).
Historically, there are several types of structures particularly implied by the name. Defensive towers served as platforms from which a defending force could rain missiles down upon an attacking force. The Romans, Byzantines, and medieval Europeans built such towers along their city walls and adjoining important gates. The Romans and other peoples also used offensive, or siege, towers, as raised platforms for attacking troops to overrun high city walls. Military towers often gave their name to an entire fortress; the Tower of London, for example, includes the entire complex of buildings contiguous with the White Tower of William I the Conqueror.
Towers were an important feature of the churches and cathedrals built during the Romanesque and Gothic periods. Some Gothic church towers were designed to carry a spire, while others had flat roofs. Many church towers were used as belfries, though the most famous campanile, or bell tower, the Leaning Tower of Pisa (1174), is a freestanding structure. In civic architecture, towers were often used to hold clocks, as in many hotels de ville (town halls) in France and Germany. The use of towers declined somewhat during the Renaissance but reappeared in the more flamboyant Baroque architecture of the 17th and 18th centuries.
The use of steel frames enabled buildings to reach unprecedented heights in the late 19th and 20th centuries; the Eiffel Tower (1889) in Paris was the first structure to reveal the true vertical potential of steel construction. The ubiquity of modern skyscrapers has robbed the word tower of most of its meaning, though the Petronas Twin Towers in Kuala Lumpur, Malaysia, the Willis Tower in Chicago, and other skyscrapers still bear the term in their official names.
In 2007 the world’s tallest freestanding building was Taipei 101 (2003; the Taipei Financial Centre), 1,667 feet (508 metres) tall, in Taiwan. The tallest supported structure is a 2,063-foot (629-metre) stayed television broadcasting tower, completed in 1963 and located between Fargo and Blanchard, North Dakota, U.S.
CN Tower, also called Canadian National Tower, is a broadcast and telecommunications tower in Toronto. Standing at a height of 1,815 feet (553 metres), it was the world’s tallest freestanding structure until 2007, when it was surpassed by the Burj Dubai building in Dubayy (Dubai), U.A.E. Construction of CN Tower began in February 1973 and involved more than 1,500 workers; the tower was completed in February 1974, and the attachment of its antenna was finished in April 1975. First opened to the public on June 26, 1976, CN Tower was built by Canadian National Railway Company and was initially privately owned, but ownership of the tower was transferred to the Canadian government in 1995; it is now managed by a public corporation. CN Tower, whose designers included John Andrews, Webb Zerafa, Menkes Housden, and E.R. Baldwin, is by far Toronto’s most distinctive landmark. It is a major tourist attraction that includes observation decks, a revolving restaurant at some 1,151 feet (351 metres), and an entertainment complex. It is also a centre for telecommunications in Toronto.
Details
A tower is a tall structure, taller than it is wide, often by a significant factor. Towers are distinguished from masts by their lack of guy-wires and are therefore, along with tall buildings, self-supporting structures.
Towers are specifically distinguished from buildings in that they are built not to be habitable but to serve other functions using the height of the tower. For example, the height of a clock tower improves the visibility of the clock, and the height of a tower in a fortified building such as a castle increases the visibility of the surroundings for defensive purposes. Towers may also be built for observation, leisure, or telecommunication purposes. A tower can stand alone or be supported by adjacent buildings, or it may be a feature on top of a larger structure or building.
History
Towers have been used by mankind since prehistoric times. The oldest known may be the circular stone tower in walls of Neolithic Jericho (8000 BC). Some of the earliest towers were ziggurats, which existed in Sumerian architecture since the 4th millennium BC. The most famous ziggurats include the Sumerian Ziggurat of Ur, built in the 3rd millennium BC, and the Etemenanki, one of the most famous examples of Babylonian architecture.
Some of the earliest surviving examples are the broch structures in northern Scotland, which are conical tower houses. These and other examples from Phoenician and Roman cultures emphasised the use of a tower in fortification and sentinel roles. For example, the name of the Moroccan city of Mogador, founded in the first millennium BC, is derived from the Phoenician word for watchtower ('migdol'). The Romans utilised octagonal towers as elements of Diocletian's Palace in Croatia, which monument dates to approximately 300 AD, while the Servian Walls (4th century BC) and the Aurelian Walls (3rd century AD) featured square ones. The Chinese used towers as integrated elements of the Great Wall of China in 210 BC during the Qin Dynasty. Towers were also an important element of castles.
Other well known towers include the Leaning Tower of Pisa in Pisa, Italy built from 1173 until 1372, the Two Towers in Bologna, Italy built from 1109 until 1119 and the Towers of Pavia (25 survive), built between 11th and 13th century. The Himalayan Towers are stone towers located chiefly in Tibet built approximately 14th to 15th century.
Mechanics
Up to a certain height, a tower can be made with the supporting structure with parallel sides. However, above a certain height, the compressive load of the material is exceeded, and the tower will fail. This can be avoided if the tower's support structure tapers up the building.
A second limit is that of buckling—the structure requires sufficient stiffness to avoid breaking under the loads it faces, especially those due to winds. Many very tall towers have their support structures at the periphery of the building, which greatly increases the overall stiffness.
A third limit is dynamic; a tower is subject to varying winds, vortex shedding, seismic disturbances etc. These are often dealt with through a combination of simple strength and stiffness, as well as in some cases tuned mass dampers to damp out movements. Varying or tapering the outer aspect of the tower with height avoids vibrations due to vortex shedding occurring along the entire building simultaneously.
Functions
Although not correctly defined as towers, many modern high-rise buildings (in particular skyscraper) have 'tower' in their name or are colloquially called 'towers'. Skyscrapers are more properly classified as 'buildings'. In the United Kingdom, tall domestic buildings are referred to as tower blocks. In the United States, the original World Trade Center had the nickname the Twin Towers, a name shared with the Petronas Twin Towers in Kuala Lumpur. In addition some of the structures listed below do not follow the strict criteria used at List of tallest towers.
Strategic advantages
The tower throughout history has provided its users with an advantage in surveying defensive positions and obtaining a better view of the surrounding areas, including battlefields. They were constructed on defensive walls, or rolled near a target (see siege tower). Today, strategic-use towers are still used at prisons, military camps, and defensive perimeters.
Potential energy
By using gravity to move objects or substances downward, a tower can be used to store items or liquids like a storage silo or a water tower, or aim an object into the earth such as a drilling tower. Ski-jump ramps use the same idea, and in the absence of a natural mountain slope or hill, can be human-made.
Communication enhancement
In history, simple towers like lighthouses, bell towers, clock towers, signal towers and minarets were used to communicate information over greater distances. In more recent years, radio masts and cell phone towers facilitate communication by expanding the range of the transmitter. The CN Tower in Toronto, Ontario, Canada was built as a communications tower, with the capability to act as both a transmitter and repeater.
Transportation support
Towers can also be used to support bridges, and can reach heights that rival some of the tallest buildings above-water. Their use is most prevalent in suspension bridges and cable-stayed bridges. The use of the pylon, a simple tower structure, has also helped to build railroad bridges, mass-transit systems, and harbors.
Control towers are used to give visibility to help direct aviation traffic.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1607 2022-12-22 00:43:58
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1510) Prefabrication
Summary
Prefabrication is the the assembly of buildings or their components at a location other than the building site. The method controls construction costs by economizing on time, wages, and materials. Prefabricated units may include doors, stairs, window walls, wall panels, floor panels, roof trusses, room-sized components, and even entire buildings.
The concept and practice of prefabrication in one form or another has been part of human experience for centuries; the modern sense of prefabrication, however, dates from about 1905. Until the invention of the gasoline-powered truck, prefabricated units—as distinct from precut building materials such as stones and logs—were of ultralight construction. Since World War I the prefabrication of more massive building elements has developed in accordance with the fluctuation of building activity in the United States, the Soviet Union, and western Europe.
Prefabrication requires the cooperation of architects, suppliers, and builders regarding the size of basic modular units. In the American building industry, for example, the 4 × 8-foot panel is a standard unit. Building plans are drafted using 8-foot ceilings, and floor plans are described in multiples of four. Suppliers of prefabricated wall units build wall frames in dimensions of 8 feet high by 4, 8, 16, or 24 feet long. Insulation, plumbing, electrical wiring, ventilation systems, doors, and windows are all constructed to fit within the 4 × 8-foot modular unit.
Another prefabricated unit widely used in light construction is the roof truss, which is manufactured and stockpiled according to angle of pitch and horizontal length in 4-foot increments.
On the scale of institutional and office buildings and works of civil engineering, such as bridges and dams, rigid frameworks of steel with spans up to 120 feet (37 m) are prefabricated. The skins of large buildings are often modular units of porcelainized steel. Stairwells are delivered in prefabricated steel units. Raceways and ducts for electrical wiring, plumbing, and ventilation are built into the metal deck panels used in floors and roofs. The Verrazano-Narrows Bridge in New York City (with a span of 4,260 feet [1,298 m]) is made of 60 prefabricated units weighing 400 tons each.
Precast concrete components include slabs, beams, stairways, modular boxes, and even kitchens and bathrooms complete with precast concrete fixtures.
A prefabricated building component that is mass-produced in an assembly line can be made in a shorter time for lower cost than a similar element fabricated by highly paid skilled labourers at a building site. Many contemporary building components also require specialized equipment for their construction that cannot be economically moved from one building site to another. Savings in material costs and assembly time are facilitated by locating the prefabrication operation at a permanent site. Materials that have become highly specialized, with attendant fluctuations in price and availability, can be stockpiled at prefabrication shops or factories. In addition, the standardization of building components makes it possible for construction to take place where the raw material is least expensive.
The major drawback to prefabrication is the dilution of responsibility. A unit that is designed in one area of the country may be prefabricated in another and shipped to yet a third area, which may or may not have adequate criteria for inspecting materials that are not locally produced. This fragmentation of control factors increases the probability of structural failure.
Details
Prefabrication is the practice of assembling components of a structure in a factory or other manufacturing site, and transporting complete assemblies or sub-assemblies to the construction site where the structure is to be located. The term is used to distinguish this process from the more conventional construction practice of transporting the basic materials to the construction site where all assembly is carried out.
The term prefabrication also applies to the manufacturing of things other than structures at a fixed site. It is frequently used when fabrication of a section of a machine or any movable structure is shifted from the main manufacturing site to another location, and the section is supplied assembled and ready to fit. It is not generally used to refer to electrical or electronic components of a machine, or mechanical parts such as pumps, gearboxes and compressors which are usually supplied as separate items, but to sections of the body of the machine which in the past were fabricated with the whole machine. Prefabricated parts of the body of the machine may be called 'sub-assemblies' to distinguish them from the other components.
Process and theory
An example from house-building illustrates the process of prefabrication. The conventional method of building a house is to transport bricks, timber, cement, sand, steel and construction aggregate, etc. to the site, and to construct the house on site from these materials. In prefabricated construction, only the foundations are constructed in this way, while sections of walls, floors and roof are prefabricated (assembled) in a factory (possibly with window and door frames included), transported to the site, lifted into place by a crane and bolted together.
Prefabrication is used in the manufacture of ships, aircraft and all kinds of vehicles and machines where sections previously assembled at the final point of manufacture are assembled elsewhere instead, before being delivered for final assembly.
The theory behind the method is that time and cost is saved if similar construction tasks can be grouped, and assembly line techniques can be employed in prefabrication at a location where skilled labour is available, while congestion at the assembly site, which wastes time, can be reduced. The method finds application particularly where the structure is composed of repeating units or forms, or where multiple copies of the same basic structure are being constructed. Prefabrication avoids the need to transport so many skilled workers to the construction site, and other restricting conditions such as a lack of power, lack of water, exposure to harsh weather or a hazardous environment are avoided. Against these advantages must be weighed the cost of transporting prefabricated sections and lifting them into position as they will usually be larger, more fragile and more difficult to handle than the materials and components of which they are made.
History
Prefabrication has been used since ancient times. For example, it is claimed that the world's oldest known engineered roadway, the Sweet Track constructed in England around 3800 BC, employed prefabricated timber sections brought to the site rather than assembled on-site.[citation needed]
Sinhalese kings of ancient Sri Lanka have used prefabricated buildings technology to erect giant structures, which dates back as far as 2000 years, where some sections were prepared separately and then fitted together, specially in the Kingdom of Anuradhapura and Polonnaruwa.
After the great Lisbon earthquake of 1755, the Portuguese capital, especially the Baixa district, was rebuilt by using prefabrication on an unprecedented scale. Under the guidance of Sebastião José de Carvalho e Melo, popularly known as the Marquis de Pombal, the most powerful royal minister of D. Jose I, a new Pombaline style of architecture and urban planning arose, which introduced early anti-seismic design features and innovative prefabricated construction methods, according to which large multistory buildings were entirely manufactured outside the city, transported in pieces and then assembled on site. The process, which lasted into the nineteenth century, lodged the city's residents in safe new structures unheard-of before the quake.
Also in Portugal, the town of Vila Real de Santo António in the Algarve, founded on 30 December 1773, was quickly erected through the use of prefabricated materials en masse. The first of the prefabricated stones was laid in March 1774. By 13 May 1776, the centre of the town had been finished and was officially opened.
In 19th century Australia a large number of prefabricated houses were imported from the United Kingdom.
The method was widely used in the construction of prefabricated housing in the 20th century, such as in the United Kingdom as temporary housing for thousands of urban families "bombed out" during World War II. Assembling sections in factories saved time on-site and the lightness of the panels reduced the cost of foundations and assembly on site. Coloured concrete grey and with flat roofs, prefab houses were uninsulated and cold and life in a prefab acquired a certain stigma, but some London prefabs were occupied for much longer than the projected 10 years.
The Crystal Palace, erected in London in 1851, was a highly visible example of iron and glass prefabricated construction; it was followed on a smaller scale by Oxford Rewley Road railway station.
During World War II, prefabricated Cargo ships, designed to quickly replace ships sunk by Nazi U-boats became increasingly common. The most ubiquitous of these ships was the American Liberty ship, which reached production of over 2,000 units, averaging 3 per day.
Current uses
The most widely used form of prefabrication in building and civil engineering is the use of prefabricated concrete and prefabricated steel sections in structures where a particular part or form is repeated many times. It can be difficult to construct the formwork required to mould concrete components on site, and delivering wet concrete to the site before it starts to set requires precise time management. Pouring concrete sections in a factory brings the advantages of being able to re-use moulds and the concrete can be mixed on the spot without having to be transported to and pumped wet on a congested construction site. Prefabricating steel sections reduces on-site cutting and welding costs as well as the associated hazards.
Prefabrication techniques are used in the construction of apartment blocks, and housing developments with repeated housing units. Prefabrication is an essential part of the industrialization of construction. The quality of prefabricated housing units had increased to the point that they may not be distinguishable from traditionally built units to those that live in them. The technique is also used in office blocks, warehouses and factory buildings. Prefabricated steel and glass sections are widely used for the exterior of large buildings.
Detached houses, cottages, log cabin, saunas, etc. are also sold with prefabricated elements. Prefabrication of modular wall elements allows building of complex thermal insulation, window frame components, etc. on an assembly line, which tends to improve quality over on-site construction of each individual wall or frame. Wood construction in particular benefits from the improved quality. However, tradition often favors building by hand in many countries, and the image of prefab as a "cheap" method only slows its adoption. However, current practice already allows the modifying the floor plan according to the customer's requirements and selecting the surfacing material, e.g. a personalized brick facade can be masoned even if the load-supporting elements are timber.
Prefabrication saves engineering time on the construction site in civil engineering projects. This can be vital to the success of projects such as bridges and avalanche galleries, where weather conditions may only allow brief periods of construction. Prefabricated bridge elements and systems offer bridge designers and contractors significant advantages in terms of construction time, safety, environmental impact, constructibility, and cost. Prefabrication can also help minimize the impact on traffic from bridge building. Additionally, small, commonly used structures such as concrete pylons are in most cases prefabricated.
Radio towers for mobile phone and other services often consist of multiple prefabricated sections. Modern lattice towers and guyed masts are also commonly assembled of prefabricated elements.
Prefabrication has become widely used in the assembly of aircraft and spacecraft, with components such as wings and fuselage sections often being manufactured in different countries or states from the final assembly site. However, this is sometimes for political rather than commercial reasons, such as for Airbus.
Advantages
* Moving partial assemblies from a factory often costs less than moving pre-production resources to each site
* Deploying resources on-site can add costs; prefabricating assemblies can save costs by reducing on-site work
* Factory tools - jigs, cranes, conveyors, etc. - can make production faster and more precise
* Factory tools - shake tables, hydraulic testers, etc. - can offer added quality assurance
* Consistent indoor environments of factories eliminate most impacts of weather on production
* Cranes and reusable factory supports can allow shapes and sequences without expensive on-site falsework
* Higher-precision factory tools can aid more controlled movement of building heat and air, for lower energy consumption and healthier buildings
* Factory production can facilitate more optimal materials usage, recycling, noise capture, dust capture, etc.
* Machine-mediated parts movement, and freedom from wind and rain can improve construction safety
Disadvantages
* Transportation costs may be higher for voluminous prefabricated sections (especially sections so big that they constitute oversize loads requiring special signage, escort vehicles, and temporary road closures) than for their constituent materials, which can often be packed more densely and are more likely to fit onto standard-sized vehicles.
* Large prefabricated sections may require heavy-duty cranes and precision measurement and handling to place in position.
Off-site fabrication
Off-site fabrication is a process that incorporates prefabrication and pre-assembly. The process involves the design and manufacture of units or modules, usually remote from the work site, and the installation at the site to form the permanent works at the site. In its fullest sense, off-site fabrication requires a project strategy that will change the orientation of the project process from construction to manufacture to installation. Examples of off-site fabrication are wall panels for homes, wooden truss bridge spans, airport control stations.
There are four main categories of off-site fabrication, which is often also referred to as off-site construction. These can be described as component (or sub-assembly) systems, panelised systems, volumetric systems, and modular systems. Below these categories different branches, or technologies are being developed. There are a vast number of different systems on the market which fall into these categories and with recent advances in digital design such as building information modeling (BIM), the task of integrating these different systems into a construction project is becoming increasingly a "digital" management proposition.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1608 2022-12-23 00:12:42
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1511) Fragility (glass physics)
Summary
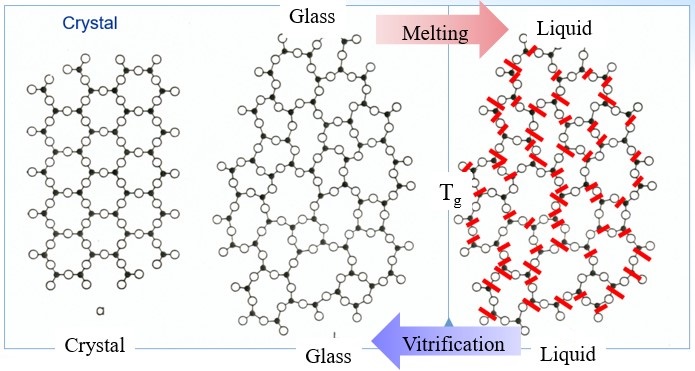
Glass physics: The standard definition of a glass (or vitreous solid) is a solid formed by rapid melt quenching. However, the term "glass" is often defined in a broader sense, to describe any non-crystalline (amorphous) solid that exhibits a glass transition when heated towards the liquid state. Glass is an amorphous solid.
Details
In glass physics, fragility characterizes how rapidly the dynamics of a material slows down as it is cooled toward the glass transition: materials with a higher fragility have a relatively narrow glass transition temperature range, while those with low fragility have a relatively broad glass transition temperature range. Physically, fragility may be related to the presence of dynamical heterogeneity in glasses, as well as to the breakdown of the usual Stokes–Einstein relationship between viscosity and diffusion.
Definition
Formally, fragility reflects the degree to which the temperature dependence of the viscosity (or relaxation time) deviates from Arrhenius behavior. This classification was originally proposed by Austen Angell. The most common definition of fragility is the "kinetic fragility index" m, which characterizes the slope of the viscosity (or relaxation time) of a material with temperature as it approaches the glass transition temperature from above:
where
is viscosity, Tg is the glass transition temperature, m is fragility, and T is temperature. Glass-formers with a high fragility are called "fragile"; those with a low fragility are called "strong". For example, silica has a relatively low fragility and is called "strong", whereas some polymers have relatively high fragility and are called "fragile". Fragility has no direct relationship with the colloquial meaning of the word "fragility", which more closely relates to the brittleness of a material.Several fragility parameters have been introduced to characterise the fragility of liquids, including the Bruning–Sutton, Avramov and Doremus fragility parameters. The Bruning–Sutton fragility parameter m relies on the curvature or slope of the viscosity curves. The Avramov fragility parameter α is based on a Kohlraush-type formula of viscosity derived for glasses: strong liquids have α ≈ 1 whereas liquids with higher α values become more fragile. Doremus indicated that practically all melts deviate from the Arrhenius behaviour, e.g. the activation energy of viscosity changes from a high QH at low temperature to a low QL at high temperature. However asymptotically both at low and high temperatures the activation energy of viscosity becomes constant, e.g. independent of temperature. Changes that occur in the activation energy are unambiguously characterised by the ratio between the two values of activation energy at low and high temperatures, which Doremus suggested could be used as a fragility criterion: RD=QH/QL. The higher RD, the more fragile are the liquids, Doremus’ fragility ratios range from 1.33 for germania to 7.26 for diopside melts.
The Doremus’ criterion of fragility can be expressed in terms of thermodynamic parameters of the defects mediating viscous flow in the oxide melts: RD=1+Hd/Hm, where Hd is the enthalpy of formation and Hm is the enthalpy of motion of such defects. Hence the fragility of oxide melts is an intrinsic thermodynamic parameter of melts which can be determined unambiguously by experiment.
The fragility can also be expressed analytically in terms of physical parameters that are related to the interatomic or intermolecular interaction potential. It is given as function of a parameter which measures the steepness of the interatomic or intermolecular repulsion, and as a function of the thermal expansion coefficient of the liquid, which, instead, is related to the attractive part of the interatomic or intermolecular potential. The analysis of various systems (from Lennard-Jones model liquids to metal alloys) has evidenced that a steeper interatomic repulsion leads to more fragile liquids, or, conversely, that soft atoms make strong liquids.
Recent synchrotron radiation X-ray diffraction experiments showed a clear link between structure evolution of the supercooled liquid on cooling, for example, intensification of Ni-P and Cu-P peaks in the radial distribution function close to the glass-transition, and liquid fragility.
Physical implications
The physical origin of the non-Arrhenius behavior of fragile glass formers is an area of active investigation in glass physics. Advances over the last decade have linked this phenomenon with the presence of locally heterogeneous dynamics in fragile glass formers; i.e. the presence of distinct (if transient) slow and fast regions within the material. This effect has also been connected to the breakdown of the Stokes–Einstein relation between diffusion and viscosity in fragile liquids.
It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1609 2022-12-24 00:11:23
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1512) Sunglasses
Sunglasses or sun glasses (informally called shades or sunnies; more names below) are a form of protective eyewear designed primarily to prevent bright sunlight and high-energy visible light from damaging or discomforting the eyes. They can sometimes also function as a visual aid, as variously termed spectacles or glasses exist, featuring lenses that are colored, polarized or darkened. In the early 20th century, they were also known as sun cheaters (cheaters then being an American slang term for glasses).
Since the 1930s, sunglasses have been a popular fashion accessory, especially on the beach.
The American Optometric Association recommends wearing sunglasses that block ultraviolet radiation (UV) whenever a person is in the sunlight to protect the eyes from UV and blue light, which can cause several serious eye problems. Their usage is mandatory immediately after some surgical procedures, such as LASIK, and recommended for a certain time period in dusty areas, when leaving the house and in front of a TV screen or computer monitor after LASEK. It is important to note that dark glasses that do not block UV radiation can be more damaging to the eyes than not wearing eye protection at all, since they tend to open the pupil and allow more UV rays into the eye.
(LASIK or Lasik (laser-assisted in situ keratomileusis), commonly referred to as laser eye surgery or laser vision correction, is a type of refractive surgery for the correction of myopia, hyperopia, and an actual cure for astigmatism, since it is in the cornea. LASIK surgery is performed by an ophthalmologist who uses a laser or microkeratome to reshape the eye's cornea in order to improve visual acuity. For most people, LASIK provides a long-lasting alternative to eyeglasses or contact lenses.
LASIK is very similar to another surgical corrective procedure, photorefractive keratectomy (PRK), and LASEK. All represent advances over radial keratotomy in the surgical treatment of refractive errors of vision. For patients with moderate to high myopia or thin corneas which cannot be treated with LASIK and PRK, the phakic intraocular lens is an alternative.
As of 2018, roughly 9.5 million Americans have had LASIK and, globally, between 1991 and 2016, more than 40 million procedures were performed. However, the procedure seemed to be a declining option as of 2015.)
Visual clarity and comfort
Sunglasses can improve visual comfort and visual clarity by protecting the eye from glare.
Various types of disposable sunglasses are dispensed to patients after receiving mydriatic eye drops during eye examinations.
The lenses of polarized sunglasses reduce glare reflected at some angles off shiny non-metallic surfaces, such as water. They allow wearers to see into water when only surface glare would otherwise be seen, and eliminate glare from a road surface when driving into the sun.
Protection
Sunglasses offer protection against excessive exposure to light, including its visible and invisible components.
The most widespread protection is against ultraviolet radiation, which can cause short-term and long-term ocular problems such as photokeratitis (snow blindness), cataracts, pterygium, and various forms of eye cancer. Medical experts advise the public on the importance of wearing sunglasses to protect the eyes from UV; for adequate protection, experts recommend sunglasses that reflect or filter out 99% or more of UVA and UVB light, with wavelengths up to 400 nm. Sunglasses that meet this requirement are often labeled as "UV400". This is slightly more protection than the widely used standard of the European Union, which requires that 95% of the radiation up to only 380 nm must be reflected or filtered out. Sunglasses are not sufficient to protect the eyes against permanent harm from looking directly at the Sun, even during a solar eclipse. Special eyewear known as solar viewers are required for direct viewing of the sun. This type of eyewear can filter out UV radiation harmful to the eyes.
More recently, high-energy visible light (HEV) has been implicated as a cause of age-related macular degeneration; before, debates had already existed as to whether "blue blocking" or amber tinted lenses may have a protective effect. Some manufacturers already design glasses to block blue light; the insurance company Suva, which covers most Swiss employees, asked eye experts around Charlotte Remé (ETH Zürich) to develop norms for blue blocking, leading to a recommended minimum of 95% of the blue light. Sunglasses are especially important for children, as their ocular lenses are thought to transmit far more HEV light than adults (lenses "yellow" with age).
There has been some speculation that sunglasses actually promote skin cancer. This is due to the eyes being tricked into producing less melanocyte-stimulating hormone in the body.
Assessing protection
The only way to assess the protection of sunglasses is to have the lenses measured, either by the manufacturer or by a properly equipped optician. Several standards for sunglasses allow a general classification of the UV protection (but not the blue light protection), and manufacturers often indicate simply that the sunglasses meet the requirements of a specific standard rather than publish the exact figures.
The only "visible" quality test for sunglasses is their fit. The lenses should fit close enough to the face that only very little "stray light" can reach the eye from their sides, or from above or below, but not so close that the eyelashes smear the lenses. To protect against "stray light" from the sides, the lenses should fit close enough to the temples and/or merge into broad temple arms or leather blinders.
It is not possible to "see" the protection that sunglasses offer. Dark lenses do not automatically filter out more harmful UV radiation and blue light than light lenses. Inadequate dark lenses are even more harmful than inadequate light lenses (or wearing no sunglasses at all) because they provoke the pupil to open wider. As a result, more unfiltered radiation enters the eye. Depending on the manufacturing technology, sufficiently protective lenses can block much or little light, resulting in dark or light lenses. The lens color is not a guarantee either. Lenses of various colors can offer sufficient (or insufficient) UV protection. Regarding blue light, the color gives at least a first indication: Blue blocking lenses are commonly yellow or brown, whereas blue or gray lenses cannot offer the necessary blue light protection. However, not every yellow or brown lens blocks sufficient blue light. In rare cases, lenses can filter out too much blue light (i.e., 100%), which affects color vision and can be dangerous in traffic when colored signals are not properly recognized.
High prices cannot guarantee sufficient protection as no correlation between high prices and increased UV protection has been demonstrated. A 1995 study reported that "Expensive brands and polarizing sunglasses do not guarantee optimal UVA protection." The Australian Competition & Consumer Commission has also reported that "consumers cannot rely on price as an indicator of quality". One survey even found that a $6.95 pair of generic glasses offered slightly better protection than expensive Salvatore Ferragamo shades.
Further functions
While non-tinted glasses are very rarely worn without the practical purpose of correcting eyesight or protecting one's eyes, sunglasses have become popular for several further reasons, and are sometimes worn even indoors or at night.
Sunglasses can be worn to hide one's eyes. They can make eye contact impossible, which can be intimidating to those not wearing sunglasses; the avoided eye contact can also demonstrate the wearer's detachment, which is considered desirable (or "cool") in some circles. Eye contact can be avoided even more effectively by using mirrored sunglasses. Sunglasses can also be used to hide emotions; this can range from hiding blinking to hiding weeping and its resulting red eyes. In all cases, hiding one's eyes has implications for nonverbal communication; this is useful in poker, and many professional poker players wear heavily tinted glasses indoors while playing, so that it is more difficult for opponents to read tells which involve eye movement and thus gain an advantage.
Fashion trends can be another reason for wearing sunglasses, particularly designer sunglasses from high-end fashion brands. Sunglasses of particular shapes may be in vogue as a fashion accessory. The relevance of sunglasses within the fashion industry has included prominent fashion editors' reviews of annual trends in sunglasses as well as runway fashion shows featuring sunglasses as a primary or secondary component of a look. Fashion trends can also draw on the "cool" image of sunglasses and association with a particular lifestyle, especially the close connection between sunglasses and beach life. In some cases, this connection serves as the core concept behind an entire brand.
People may also wear sunglasses to hide an abnormal appearance of their eyes. This can be true for people with severe visual impairment, such as the blind, who may wear sunglasses to avoid making others uncomfortable. The assumption is that it may be more comfortable for another person not to see the hidden eyes rather than see abnormal eyes or eyes which seem to look in the wrong direction. People may also wear sunglasses to hide dilated or contracted pupils, bloodshot eyes due to drug use, chronic dark circles or crow's feet, recent physical abuse (such as a black eye), exophthalmos (bulging eyes), a cataract, or eyes which jerk uncontrollably (nystagmus).
Lawbreakers have been known to wear sunglasses during or after committing a crime as an aid to hiding their identities.
Land vehicle driving
When driving a vehicle, particularly at high speed, dazzling glare caused by a low Sun, or by lights reflecting off snow, puddles, other vehicles, or even the front of the vehicle, can be lethal. Sunglasses can protect against glare when driving. Two criteria must be met: vision must be clear, and the glasses must let sufficient light get to the eyes for the driving conditions. General-purpose sunglasses may be too dark, or otherwise unsuitable for driving.
The Automobile Association and the Federation of Manufacturing Opticians have produced guidance for selection of sunglasses for driving. Variable tint or photochromic lenses increase their optical density when exposed to UV light, reverting to their clear state when the UV brightness decreases. Car windscreens filter out UV light, slowing and limiting the reaction of the lenses and making them unsuitable for driving as they could become too dark or too light for the conditions. Some manufacturers produce special photochromic lenses that adapt to the varying light conditions when driving.
Lenses of fixed tint are graded according to the optical density of the tint; in the UK sunglasses must be labelled and show the filter category number. Lenses with light transmission less than 75% are unsuitable for night driving, and lenses with light transmission less than 8% (category 4) are unsuitable for driving at any time; they should by UK law be labelled 'Not suitable for driving and road use'. Yellow tinted lenses are also not recommended for night use. Due to the light levels within the car, filter category 2 lenses which transmit between 18% and 43% of light are recommended for daytime driving. Polarised lenses normally have a fixed tint, and can reduce reflected glare more than non-polarised lenses of the same density, particularly on wet roads.
Graduated lenses, with the bottom part lighter than the top, can make it easier to see the controls within the car. All sunglasses should be marked as meeting the standard for the region where sold. An anti-reflection coating is recommended, and a hard coating to protect the lenses from scratches. Sunglasses with deep side arms can block side, or peripheral, vision and are not recommended for driving.
Even though some of these glasses are proven good enough for driving at night, it is strongly recommended not to do so, due to the changes in a wide variety of light intensities, especially while using yellow tinted protection glasses. The main purpose of these glasses are to protect the wearer from dust and smog particles entering into the eyes while driving at high speeds.
Aircraft piloting
Many of the criteria for sunglasses worn when piloting an aircraft are similar to those for land vehicles. Protection against UV radiation is more important, as its intensity increases with altitude. Polarised glasses are undesirable as aircraft windscreens are often polarised, intentionally or unintentionally, showing Moiré patterns on looking through the windscreen; and some LCDs used by instruments emit polarised light, and can dim or disappear when the pilot turns to look at them.
Sports
Like corrective glasses, sunglasses have to meet special requirements when worn for sports. They need shatterproof and impact-resistant lenses; a strap or other fixing is typically used to keep glasses in place during sporting activities, and they have a nose cushion.
For water sports, so-called water sunglasses (also: surf goggles or water eyewear) are specially adapted for use in turbulent water, such as the surf or whitewater. In addition to the features for sports glasses, water sunglasses can have increased buoyancy to stop them from sinking should they come off, and they can have a vent or other method to eliminate fogging. These sunglasses are used in water sports such as surfing, windsurfing, kiteboarding, wakeboarding, kayaking, jet skiing, bodyboarding, and water skiing.
Mountain climbing or traveling across glaciers or snowfields requires above-average eye protection, because sunlight (including ultraviolet radiation) is more intense in higher altitudes, and snow and ice reflect additional light. Popular glasses for this use are a type called glacier glasses or glacier goggles. They typically have very dark round lenses and leather blinders at the sides, which protect the eyes by blocking the Sun's rays around the edges of the lenses.
Special shaded visors were once allowed in American football; Jim McMahon, quarterback for the Chicago Bears and San Diego Chargers, famously used a sun visor during his professional football career due to a childhood eye injury and almost always wears dark sunglasses when not wearing a football helmet. Darkened visors now require a doctor's prescription at most levels of the game, mainly because concussion protocol requires officials to look a player in the eye, something made difficult by tinted visors.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1610 2022-12-25 00:08:56
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1513) Ramp
Summary
An inclined plane is a simple machine consisting of a sloping surface, used for raising heavy bodies. The force required to move an object up the incline is less than the weight being raised, discounting friction. The steeper the slope, or incline, the more nearly the required force approaches the actual weight. Expressed mathematically, the force F required to move a block D up an inclined plane without friction is equal to its weight W times the sine of the angle the inclined plane makes with the horizontal.
The principle of the inclined plane is used widely—for example, in screws and bolts, where a small force acting along a slope can produce a much larger force.
Details
An inclined plane, also known as a ramp, is a flat supporting surface tilted at an angle from the vertical direction, with one end higher than the other, used as an aid for raising or lowering a load. The inclined plane is one of the six classical simple machines defined by Renaissance scientists. Inclined planes are used to move heavy loads over vertical obstacles. Examples vary from a ramp used to load goods into a truck, to a person walking up a pedestrian ramp, to an automobile or railroad train climbing a grade.
Moving an object up an inclined plane requires less force than lifting it straight up, at a cost of an increase in the distance moved. The mechanical advantage of an inclined plane, the factor by which the force is reduced, is equal to the ratio of the length of the sloped surface to the height it spans. Owing to conservation of energy, the same amount of mechanical energy (work) is required to lift a given object by a given vertical distance, disregarding losses from friction, but the inclined plane allows the same work to be done with a smaller force exerted over a greater distance.
The angle of friction, also sometimes called the angle of repose, is the maximum angle at which a load can rest motionless on an inclined plane due to friction without sliding down. This angle is equal to the arctangent of the coefficient of static friction μs between the surfaces.
Two other simple machines are often considered to be derived from the inclined plane. The wedge can be considered a moving inclined plane or two inclined planes connected at the base. The screw consists of a narrow inclined plane wrapped around a cylinder.
The term may also refer to a specific implementation; a straight ramp cut into a steep hillside for transporting goods up and down the hill. This may include cars on rails or pulled up by a cable system; a funicular or cable railway, such as the Johnstown Inclined Plane.
Uses
Inclined planes are widely used in the form of loading ramps to load and unload goods on trucks, ships and planes. Wheelchair ramps are used to allow people in wheelchairs to get over vertical obstacles without exceeding their strength. Escalators and slanted conveyor belts are also forms of an inclined plane.In a funicular or cable railway a railroad car is pulled up a steep inclined plane using cables. Inclined planes also allow heavy fragile objects, including humans, to be safely lowered down a vertical distance by using the normal force of the plane to reduce the gravitational force. Aircraft evacuation slides allow people to rapidly and safely reach the ground from the height of a passenger airliner.
Other inclined planes are built into permanent structures. Roads for vehicles and railroads have inclined planes in the form of gradual slopes, ramps, and causeways to allow vehicles to surmount vertical obstacles such as hills without losing traction on the road surface. Similarly, pedestrian paths and sidewalks have gentle ramps to limit their slope, to ensure that pedestrians can keep traction. Inclined planes are also used as entertainment for people to slide down in a controlled way, in playground slides, water slides, ski slopes and skateboard parks.
History
In 1586, Flemish engineer Simon Stevin (Stevinus) derived the mechanical advantage of the inclined plane by an argument that used a string of beads. He imagined two inclined planes of equal height but different slopes, placed back-to-back (above) as in a prism. A loop of string with beads at equal intervals is draped over the inclined planes, with part of the string hanging down below.
The beads resting on the planes act as loads on the planes, held up by the tension force in the string at point T. Stevin's argument goes like this:
The string must be stationary, in static equilibrium. If the string was heavier on one side than the other, and began to slide right or left under its own weight, when each bead had moved to the position of the previous bead the string would be indistinguishable from its initial position and therefore would continue to be unbalanced and slide. This argument could be repeated indefinitely, resulting in a circular perpetual motion, which is absurd. Therefore, it is stationary, with the forces on the two sides at point T (above) equal.
Inclined planes have been used by people since prehistoric times to move heavy objects. The sloping roads and causeways built by ancient civilizations such as the Romans are examples of early inclined planes that have survived, and show that they understood the value of this device for moving things uphill. The heavy stones used in ancient stone structures such as Stonehenge are believed to have been moved and set in place using inclined planes made of earth, although it is hard to find evidence of such temporary building ramps. The Egyptian pyramids were constructed using inclined planes, Siege ramps enabled ancient armies to surmount fortress walls. The ancient Greeks constructed a paved ramp 6 km (3.7 miles) long, the Diolkos, to drag ships overland across the Isthmus of Corinth.
However the inclined plane was the last of the six classic simple machines to be recognised as a machine. This is probably because it is a passive and motionless device (the load is the moving part), and also because it is found in nature in the form of slopes and hills. Although they understood its use in lifting heavy objects, the ancient Greek philosophers who defined the other five simple machines did not include the inclined plane as a machine. This view persisted among a few later scientists; as late as 1826 Karl von Langsdorf wrote that an inclined plane "...is no more a machine than is the slope of a mountain". The problem of calculating the force required to push a weight up an inclined plane (its mechanical advantage) was attempted by Greek philosophers Heron of Alexandria (c. 10 - 60 CE) and Pappus of Alexandria (c. 290 - 350 CE), but their solutions were incorrect.
It wasn't until the Renaissance that the inclined plane was solved mathematically and classed with the other simple machines. The first correct analysis of the inclined plane appeared in the work of 13th century author Jordanus de Nemore, however his solution was apparently not communicated to other philosophers of the time. Girolamo Cardano (1570) proposed the incorrect solution that the input force is proportional to the angle of the plane. Then at the end of the 16th century, three correct solutions were published within ten years, by Michael Varro (1584), Simon Stevin (1586), and Galileo Galilei (1592). Although it was not the first, the derivation of Flemish engineer Simon Stevin is the most well-known, because of its originality and use of a string of beads In 1600, Italian scientist Galileo Galilei included the inclined plane in his analysis of simple machines in Le Meccaniche ("On Mechanics"), showing its underlying similarity to the other machines as a force amplifier.
The first elementary rules of sliding friction on an inclined plane were discovered by Leonardo da Vinci (1452-1519), but remained unpublished in his notebooks. They were rediscovered by Guillaume Amontons (1699) and were further developed by Charles-Augustin de Coulomb (1785). Leonhard Euler (1750) showed that the tangent of the angle of repose on an inclined plane is equal to the coefficient of friction.
Additional Information
Ramps are a wonderful thing, they promote accessibility and allow those that might not be able to get in or out of places and spaces to do just that.
They can also be used for loading recreational vehicles, navigating curbs when making commercial deliveries, and so much more. Portable ramps have plenty of benefits that make them as desirable if not more preferable to permanent ramp systems. There are plenty of benefits to portable ramps and outlined below are 10 portable ramp advantages.
1. Ease of Use
Perhaps the most important benefit is that portable ramps are easy to use and they can be added to any home, building, or access point. They can be used to get into buildings for those that are disabled or that are impaired in some way, they can offer easy maneuvering for those that need assistance loading or unloading heavy or bulky items, and they can be moved and adjusted as needed.
2. Durability
Portable ramps are built to withstand continued use and can take on the rigors of repeat set up, pick up, and storage. They are designed to carry a fairly significant amount of weight, helping to offer the ease of access needed. Built from high-strength aluminum, EZ-ACCESS portable ramps are also rust-proof so they can stand up to harsh environments and offer portable access for years to come.
3. Multiple Uses
These types of ramps can also be used in tons of different ways. They are not limited to just being mobility ramps for those that might have problems getting around or that might have to use mobility aids. This type of ramp can be used for loading and unloading your recreational vehicles into your truck, getting lawn mowers and other items into different spaces, and getting all those heavy or bulky items that you have moved around. They are also useful on construction sites, in warehouses, on deliveries, and more.
4. Easy Installation
This is another benefit to this type of ramp. Instead of having to do major construction to get a ramp installed, you can get it installed without doing any major renovation. This type of ramp can be installed quickly, often in just a matter of minutes, as they typically do not require any sort of assembly.
5. Easy Removal
With a portable ramp a major draw is that they are not permanent. When the ramp is no longer needed, it can be taken down quickly and easily and then stowed away until next use. These ramps can be set up when they are needed and then can be removed as needed as well.
6. They are More Compact
Most permanent ramps are bulky, they tend to be much larger and also require a great deal of work to have them installed properly. Portable ramps are just that, they are portable which means that they are designed to be much more compact, and easy to move around as needed.
7. Light Weight
Portable ramps are designed to be very light weight which means that if they do need to be moved or taken from one place to another, that can be done fairly quickly and easily.
8. Incredibly Varied
There are so many types of portable ramps. With multiple styles, sizes, and surface types, the right ramp can be chosen based on your specific requirements and needs.
9. Affordability
Portable ramps are often less expensive than ramps that must be added permanently to structures. These ramps are designed to be more affordable, they are designed with durable materials, and they are going to last for a very long time without you having to spend a great deal of money to make costly alterations to your home or the structure to which the ramp is being added to.
10. Safe
Portable ramps are designed with your safety in mind and many have safety features incorporated in such as a slip-resistant surface, curbs along each side of the ramp to help prevent slippage, and they come in lengthy sizes so that you can be sure your incline isn’t too steep.
Portable ramps are the wave of the future. These ramps are affordable, far less difficult to set up, incredibly versatile, and offer a plethora of benefits to the user. Portable ramps are a great option if you do have mobility issues, if you want a recreational ramp, or if you need a ramp for your commercial property.
It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1611 2022-12-25 20:40:15
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1514) Excursion
An excursion is a trip by a group of people, usually made for leisure, education, or physical purposes. It is often an adjunct to a longer journey or visit to a place, sometimes for other (typically work-related) purposes.
Public transportation companies issue reduced price excursion tickets to attract business of this type. Often these tickets are restricted to off-peak days or times for the destination concerned.
Short excursions for education or for observations of natural phenomena are called field trips. One-day educational field studies are often made by classes as extracurricular exercises, e.g. to visit a natural or geographical feature.
The term is also used for short military movements into foreign territory, without a formal announcement of war.
Excursion : A brief recreational trip; a journey out of the usual way. It is a short journey arranged so that a group of people can visit a place, especially while they are on holiday

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1612 2022-12-25 21:51:07
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1515) Tourism
Summary
Tourism is travel for pleasure or business; also the theory and practice of touring, the business of attracting, accommodating, and entertaining tourists, and the business of operating tours. The World Tourism Organization defines tourism more generally, in terms which go "beyond the common perception of tourism as being limited to holiday activity only", as people "travelling to and staying in places outside their usual environment for not more than one consecutive year for leisure and not less than 24 hours, business and other purposes". Tourism can be domestic (within the traveller's own country) or international, and international tourism has both incoming and outgoing implications on a country's balance of payments.
Tourism numbers declined as a result of a strong economic slowdown (the late-2000s recession) between the second half of 2008 and the end of 2009, and in consequence of the outbreak of the 2009 H1N1 influenza virus, but slowly recovered until the COVID-19 pandemic put an abrupt end to the growth. The United Nations World Tourism Organization estimated that global international tourist arrivals might decrease by 58% to 78% in 2020, leading to a potential loss of US$0.9–1.2 trillion in international tourism receipts.
Globally, international tourism receipts (the travel item in balance of payments) grew to US$1.03 trillion (€740 billion) in 2005, corresponding to an increase in real terms of 3.8% from 2010. International tourist arrivals surpassed the milestone of 1 billion tourists globally for the first time in 2012, emerging source markets such as China, Russia, and Brazil had significantly increased their spending over the previous decade.
Global tourism accounts for c. 8% of global greenhouse-gas emissions. Emissions as well as other significant environmental and social impacts are not always beneficial to local communities and their economies. For this reason, many tourist development organizations have begun to focus on sustainable tourism to mitigate the negative effects caused by the growing impact of tourism. The United Nations World Tourism Organization emphasized these practices by promoting tourism as part of the Sustainable Development Goals, through programs like the International Year for Sustainable Tourism for Development in 2017, and programs like Tourism for SDGs focusing on how SDG 8, SDG 12 and SDG 14 implicate tourism in creating a sustainable economy.
Tourism has reached new dimensions with the emerging industry of space tourism as well as the current industry with cruise ships, there are many different ways of tourism. Another potential new tourism industry is virtual tourism.
Details
Tourism is the act and process of spending time away from home in pursuit of recreation, relaxation, and pleasure, while making use of the commercial provision of services. As such, tourism is a product of modern social arrangements, beginning in western Europe in the 17th century, although it has antecedents in Classical antiquity.
Tourism is distinguished from exploration in that tourists follow a “beaten path,” benefit from established systems of provision, and, as befits pleasure-seekers, are generally insulated from difficulty, danger, and embarrassment. Tourism, however, overlaps with other activities, interests, and processes, including, for example, pilgrimage. This gives rise to shared categories, such as “business tourism,” “sports tourism,” and “medical tourism” (international travel undertaken for the purpose of receiving medical care).
The origins of tourism
By the early 21st century, international tourism had become one of the world’s most important economic activities, and its impact was becoming increasingly apparent from the Arctic to Antarctica. The history of tourism is therefore of great interest and importance. That history begins long before the coinage of the word tourist at the end of the 18th century. In the Western tradition, organized travel with supporting infrastructure, sightseeing, and an emphasis on essential destinations and experiences can be found in ancient Greece and Rome, which can lay claim to the origins of both “heritage tourism” (aimed at the celebration and appreciation of historic sites of recognized cultural importance) and beach resorts. The Seven Wonders of the World became tourist sites for Greeks and Romans.
Pilgrimage offers similar antecedents, bringing Eastern civilizations into play. Its religious goals coexist with defined routes, commercial hospitality, and an admixture of curiosity, adventure, and enjoyment among the motives of the participants. Pilgrimage to the earliest Buddhist sites began more than 2,000 years ago, although it is hard to define a transition from the makeshift privations of small groups of monks to recognizably tourist practices. Pilgrimage to Mecca is of similar antiquity. The tourist status of the hajj is problematic given the number of casualties that—even in the 21st century—continued to be suffered on the journey through the desert. The thermal spa as a tourist destination—regardless of the pilgrimage associations with the site as a holy well or sacred spring—is not necessarily a European invention, despite deriving its English-language label from Spa, an early resort in what is now Belgium. The oldest Japanese onsen (hot springs) were catering to bathers from at least the 6th century. Tourism has been a global phenomenon from its origins.
Modern tourism is an increasingly intensive, commercially organized, business-oriented set of activities whose roots can be found in the industrial and postindustrial West. The aristocratic grand tour of cultural sites in France, Germany, and especially Italy—including those associated with Classical Roman tourism—had its roots in the 16th century. It grew rapidly, however, expanding its geographical range to embrace Alpine scenery during the second half of the 18th century, in the intervals between European wars. (If truth is historically the first casualty of war, tourism is the second, although it may subsequently incorporate pilgrimages to graves and battlefield sites and even, by the late 20th century, to concentration camps.) As part of the grand tour’s expansion, its exclusivity was undermined as the expanding commercial, professional, and industrial middle ranks joined the landowning and political classes in aspiring to gain access to this rite of passage for their sons. By the early 19th century, European journeys for health, leisure, and culture became common practice among the middle classes, and paths to the acquisition of cultural capital (that array of knowledge, experience, and polish that was necessary to mix in polite society) were smoothed by guidebooks, primers, the development of art and souvenir markets, and carefully calibrated transport and accommodation systems.
Technology and the democratization of international tourism
Transport innovation was an essential enabler of tourism’s spread and democratization and its ultimate globalization. Beginning in the mid-19th century, the steamship and the railway brought greater comfort and speed and cheaper travel, in part because fewer overnight and intermediate stops were needed. Above all else, these innovations allowed for reliable time-tabling, essential for those who were tied to the discipline of the calendar if not the clock. The gaps in accessibility to these transport systems were steadily closing in the later 19th century, while the empire of steam was becoming global. Railways promoted domestic as well as international tourism, including short visits to the coast, city, and countryside which might last less than a day but fell clearly into the “tourism” category. Rail travel also made grand tour destinations more widely accessible, reinforcing existing tourism flows while contributing to tensions and clashes between classes and cultures among the tourists. By the late 19th century, steam navigation and railways were opening tourist destinations from Lapland to New Zealand, and the latter opened the first dedicated national tourist office in 1901.
After World War II, governments became interested in tourism as an invisible import and as a tool of diplomacy, but prior to this time international travel agencies took the lead in easing the complexities of tourist journeys. The most famous of these agencies was Britain’s Thomas Cook and Son organization, whose operations spread from Europe and the Middle East across the globe in the late 19th century. The role played by other firms (including the British tour organizers Frame’s and Henry Gaze and Sons) has been less visible to 21st-century observers, not least because these agencies did not preserve their records, but they were equally important. Shipping lines also promoted international tourism from the late 19th century onward. From the Norwegian fjords to the Caribbean, the pleasure cruise was already becoming a distinctive tourist experience before World War I, and transatlantic companies competed for middle-class tourism during the 1920s and ’30s. Between the World Wars, affluent Americans journeyed by air and sea to a variety of destinations in the Caribbean and Latin America.
Tourism became even bigger business internationally in the latter half of the 20th century as air travel was progressively deregulated and decoupled from “flag carriers” (national airlines). The airborne package tour to sunny coastal destinations became the basis of an enormous annual migration from northern Europe to the Mediterranean before extending to a growing variety of long-haul destinations, including Asian markets in the Pacific, and eventually bringing postcommunist Russians and eastern Europeans to the Mediterranean. Similar traffic flows expanded from the United States to Mexico and the Caribbean. In each case these developments built on older rail-, road-, and sea-travel patterns. The earliest package tours to the Mediterranean were by motor coach (bus) during the 1930s and postwar years. It was not until the late 1970s that Mediterranean sun and sea vacations became popular among working-class families in northern Europe; the label “mass tourism,” which is often applied to this phenomenon, is misleading. Such holidays were experienced in a variety of ways because tourists had choices, and the destination resorts varied widely in history, culture, architecture, and visitor mix. From the 1990s the growth of flexible international travel through the rise of budget airlines, notably easyJet and Ryanair in Europe, opened a new mix of destinations. Some of these were former Soviet-bloc locales such as Prague and Riga, which appealed to weekend and short-break European tourists who constructed their own itineraries in negotiation with local service providers, mediated through the airlines’ special deals. In international tourism, globalization has not been a one-way process; it has entailed negotiation between hosts and guests.
Day-trippers and domestic tourism
While domestic tourism could be seen as less glamorous and dramatic than international traffic flows, it has been more important to more people over a longer period. From the 1920s the rise of Florida as a destination for American tourists has been characterized by “snowbirds” from the northern and Midwestern states traveling a greater distance across the vast expanse of the United States than many European tourists travel internationally. Key phases in the pioneering development of tourism as a commercial phenomenon in Britain were driven by domestic demand and local journeys. European wars in the late 18th and early 19th centuries prompted the “discovery of Britain” and the rise of the Lake District and Scottish Highlands as destinations for both the upper classes and the aspiring classes. The railways helped to open the seaside to working-class day-trippers and holidaymakers, especially in the last quarter of the 19th century. By 1914 Blackpool in Lancashire, the world’s first working-class seaside resort, had around four million visitors per summer. Coney Island in Brooklyn, New York, had more visitors by this time, but most were day-trippers who came from and returned to locations elsewhere in the New York City area by train the same day. Domestic tourism is less visible in statistical terms and tends to be serviced by regional, local, and small family-run enterprises. The World Tourism Organization, which tries to count tourists globally, is more concerned with the international scene, but across the globe, and perhaps especially in Asia, domestic tourism remains much more important in numerical terms than the international version.
A case study: the beach holiday
Much of the post-World War II expansion of international tourism was based on beach holidays, which have a long history. In their modern, commercial form, beach holidays are an English invention of the 18th century, based on the medical adaptation of popular sea-bathing traditions. They built upon the positive artistic and cultural associations of coastal scenery for societies in the West, appealing to the informality and habits and customs of maritime society. Later beach holiday destinations incorporated the sociability and entertainment regimes of established spa resorts, sometimes including gambling casinos. Beach holidays built on widespread older uses of the beach for health, enjoyment, and religious rites, but it was the British who formalized and commercialized them. From the late 18th and early 19th centuries, beach resorts spread successively across Europe and the Mediterranean and into the United States, then took root in the European-settled colonies and republics of Oceania, South Africa, and Latin America and eventually reached Asia.
Beach holiday environments, regulations, practices, and fashions mutated across cultures as sunshine and relaxation displaced therapy and convention. Coastal resorts became sites of conflict over access and use as well as over concepts of decency and excess. Beaches could be, in acceptably exciting ways, liminal frontier zones where the usual conventions could be suspended. (Not just in Rio de Janeiro have beaches become carnivalesque spaces where the world has been temporarily turned upside down.) Coastal resorts could also be dangerous and challenging. They could become arenas for class conflict, starting with the working-class presence at the 19th-century British seaside, where it took time for day-trippers from industrial towns to learn to moderate noisy, boisterous behaviour and abandon nude bathing. Beaches were also a prime location for working out economic, ethnic, “racial,” or religious tensions, such as in Mexico, where government-sponsored beach resort developments from the 1970s displaced existing farming communities. In South Africa the apartheid regime segregated the beaches, and in the Islamic world locals sustained their own bathing traditions away from the tourist beaches.
The beach is only the most conspicuous of many distinctive settings to attract a tourist presence and generate a tourism industry, but its history illustrates many general points about tradition, diffusion, mutation, and conflict. Tourism has also made use of history, as historic sites attract cultural tourists and collectors of iconic images. Indigenous peoples can sometimes profit from the marketability of their customs, and even the industrial archaeology of tourism itself is becoming good business, with historically significant hotels, transport systems, and even amusement park rides becoming popular destinations. Heritage and authenticity are among the many challenging and compromised attributes that tourism uses to market the intangible wares that it appropriates. The global footprint of tourism—its economic, environmental, demographic, and cultural significance—was already huge at the beginning of the 20th century and continues to grow exponentially. As the body of literature examining this important industry continues to expand, historical perspectives will develop further.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1613 2022-12-26 20:46:30
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1516) Alcoholics Anonymous
Summary
Alcoholics Anonymous (AA) is a voluntary fellowship of alcoholic persons who seek to get sober and remain sober through self-help and the help of other recovered alcoholics. Although general conventions meet periodically and Alcoholics Anonymous World Services, Inc., is headquartered in New York City, all AA groups are essentially local and autonomous. To counteract self-indulgence and promote the group’s welfare, members identify themselves only by first name and surname initial. Much of the program has a social and spiritual, but nonsectarian, basis.
AA began in May 1935 in the meeting of two alcoholics attempting to overcome their drinking problems: a New York stockbroker, “Bill W.” (William Griffith Wilson [1895–1971]), and a surgeon from Akron, Ohio, “Dr. Bob S.” (Robert Holbrook Smith [1879–1950]). Drawing upon their own experiences, they set out to help fellow alcoholics and first recorded their program in Alcoholics Anonymous (1939; 3rd ed., 1976). By the early 21st century, Alcoholics Anonymous had some 2,000,000 members forming more than 110,000 groups in about 180 countries and territories (most of them, however, in the United States and Canada).
Details
Alcoholics Anonymous (AA) is an international mutual aid fellowship of alcoholics dedicated to abstinence-based recovery from alcoholism through its spiritually-inclined Twelve Step program. Following its Twelve Traditions, AA is non-professional and spiritual but non-denominational, as well as apolitical and unaffiliated. In 2020 AA estimated its worldwide membership to be over two million with 75% of those in the U.S. and Canada.
Without it taking a position on the disease model of alcoholism, AA is still associated with its popularity since many of its members took a large role in spreading it. Regarding its effectiveness, a 2020 scientific review saw clinical interventions encouraging increased AA participation resulting in higher abstinence rates over other clinical interventions while probably reducing health costs.
AA dates its start to 1935 when Bill Wilson (Bill W) first commiserated alcoholic to alcoholic with Bob Smith (Dr. Bob) who, along with Wilson, was active in AA's precursor the Christian revivalist Oxford Group. Within the Oxford Group Wilson and Smith, joined by other alcoholics, supported each other in meetings and individually until forming a fellowship of alcoholics only. In 1939 they published Alcoholics Anonymous: The Story of How More Than One Hundred Men Have Recovered From Alcoholism. Known as the Big Book and the source of AA’s name, it contains AA's Twelve Step recovery program with later editions including the Twelve Traditions, first adopted in 1950, to formalize and unify the fellowship as a benign anarchy.
The Twelve Steps are presented as a suggested self-improvement program resulting in a spiritual awakening after an alcoholic has conceded powerlessness over alcohol and acknowledged its damage, as well as having listed and strived to correct personal failings and by making amends for misdeeds. The Steps suggest helping other alcoholics through the Steps, which, though not explicitly prescribed, is often done by sponsoring other alcoholics. Submitting to the will of God—"as we understood Him"— is urged by the Steps, but differing spiritual spiritual practices and persuasions, as well as non-theist members, are accepted and accommodated.
The Twelve Traditions are AA's guidelines for members, groups and its non-governing upper echelons. Besides making a desire to stop drinking the only membership requirement, the Traditions advise against dogma, hierarchies and involvement in public controversies so recovery from alcoholism remains AA’s primary purpose. Without threat of retribution or means of enforcement the Traditions urge members to remain anonymous in public media. They also wish that members or groups to not use AA to gain wealth, property or prestige. The Traditions establish AA groups as autonomous, self-supporting through members’ voluntary contributions while rejecting outside contributions, and, as with all of AA, barred from representing AA as affiliated with or supporting of other organizations or causes.
With AA's permission, subsequent fellowships such as Narcotics Anonymous and Gamblers Anonymous have adopted and adapted the Twelve Steps and the Twelve Traditions to their addiction recovery programs.
![]()
It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1614 2022-12-27 13:56:30
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1517) Credit card
Summary
A credit card is a payment card issued to users (cardholders) to enable the cardholder to pay a merchant for goods and services based on the cardholder's accrued debt (i.e., promise to the card issuer to pay them for the amounts plus the other agreed charges). The card issuer (usually a bank or credit union) creates a revolving account and grants a line of credit to the cardholder, from which the cardholder can borrow money for payment to a merchant or as a cash advance. There are two credit card groups: consumer credit cards and business credit cards. Most cards are plastic, but some are metal cards (stainless steel, gold, palladium, titanium), and a few gemstone-encrusted metal cards.
A regular credit card is different from a charge card, which requires the balance to be repaid in full each month or at the end of each statement cycle. In contrast, credit cards allow the consumers to build a continuing balance of debt, subject to interest being charged. A credit card differs from a charge card also in that a credit card typically involves a third-party entity that pays the seller and is reimbursed by the buyer, whereas a charge card simply defers payment by the buyer until a later date.
A credit card also differs from a debit card, which can be used like currency by the owner of the card. Alternatives to credit cards include debit cards, mobile payments, digital wallets, cryptocurrencies, pay-by-hand, bank transfers, and buy now, pay later. As of June 2018, there were 7.753 billion credit cards in the world. In 2020, there were 1.09 billion credit cards in circulation in the U.S and 72.5% of adults (187.3 million) in the country had at least one credit card.
Technical specifications
The size of most credit cards is 85.60 by 53.98 millimetres (3+3⁄8 in × 2+1⁄8 in) and rounded corners with a radius of 2.88–3.48 millimetres (9⁄80–11⁄80 in) conforming to the ISO/IEC 7810 ID-1 standard, the same size as ATM cards and other payment cards, such as debit cards.
Credit cards have a printed or embossed bank card number complying with the ISO/IEC 7812 numbering standard. The card number's prefix, called the Bank Identification Number (known in the industry as a BIN), is the sequence of digits at the beginning of the number that determine the bank to which a credit card number belongs. This is the first six digits for MasterCard and Visa cards. The next nine digits are the individual account number, and the final digit is a validity check digit.
Both of these standards are maintained and further developed by ISO/IEC JTC 1/SC 17/WG 1. Credit cards have a magnetic stripe conforming to the ISO/IEC 7813. Most modern credit cards use smart card technology: they have a computer chip embedded in them as a security feature. In addition, complex smart cards, including peripherals such as a keypad, a display or a fingerprint sensor are increasingly used for credit cards.
In addition to the main credit card number, credit cards also carry issue and expiration dates (given to the nearest month), as well as extra codes such as issue numbers and security codes. Complex smart cards allow to have a variable security code, thus increasing security for online transactions. Not all credit cards have the same sets of extra codes nor do they use the same number of digits.
Credit card numbers and cardholder names were originally embossed, to allow for easy transfer of such information to charge slips printed on carbon paper forms. With the decline of paper slips, some credit cards are no longer embossed and in fact the card number is no longer in the front. In addition, some cards are now vertical in design, rather than horizontal.
Details
A credit card is a small plastic card containing a means of identification, such as a signature or picture, that authorizes the person named on it to charge goods or services to an account, for which the cardholder is billed periodically.
The use of credit cards originated in the United States during the 1920s, when individual firms, such as oil companies and hotel chains, began issuing them to customers for purchases made at company outlets. The first universal credit card, which could be used at a variety of establishments, was introduced by the Diners’ Club, Inc., in 1950. Another major card of this type, known as a travel and entertainment card, was established by the American Express Company in 1958. Under this system, the credit card company charges its cardholders an annual fee and bills them on a periodic basis—usually monthly. Cooperating merchants throughout the world pay a service charge to the credit card issuer in the range of 4–7 percent of total billings.
A later innovation was the bank credit card system, in which the bank credits the account of the merchant as sales slips are received and assembles the charges to be billed at the end of the period to the cardholder, who pays the bank either in toto or in monthly installments with interest or “carrying charges” added. The first national plan was BankAmericard, begun on a statewide basis by the Bank of America in California in 1958, licensed in other states beginning in 1966, and renamed VISA in 1976–77. Many banks that began credit card plans on a citywide or regional basis eventually affiliated with major national bank plans as the range of included services (meals and lodging as well as store purchases) expanded. This development changed the nature of personal credit, which was no longer limited by location. The growing reach of credit networks allowed a person to make credit card purchases on a national and, eventually, international scale. The system has spread to all parts of the world. Other major bank cards include MasterCard (formerly known as Master Charge in the United States), JCB (in Japan), Discover (formerly partnering with Novus and primarily issued in the United States), and Barclaycard (in the United Kingdom, Europe, and the Caribbean).
In bank credit card systems, the cardholder may choose to pay on an installment basis, in which case the bank earns interest on the outstanding balance. The interest income permits banks to refrain from charging cardholders an annual fee and to charge participating merchants a lower service charge. An additional advantage of the system is that merchants receive their payments promptly by depositing their bills of sale with the bank. (See also revolving credit.)
Store cards are a third form of credit card. They lack the wide acceptance of bank cards or travel and entertainment cards because they are accepted only by the retailer that issues them.
In the late 20th century, credit card use began to increase dramatically, with many customers soon outspending their earnings. Users who were unable to make the monthly payments on outstanding balances accrued on high-interest cards were subsequently hit with hefty penalty fees and quickly fell into default. The recession and rising unemployment that accompanied the global financial crisis of 2008–09 led to a rise in defaults as consumers were increasingly forced to rely on credit. In April 2009 the U.S. House of Representatives approved the Credit Card Holders’ Bill of Rights, which would provide additional consumer protections and restrict or eliminate credit card industry practices deemed unfair or abusive. Credit card debt is typically higher in industrialized countries such as the United States—the world’s most indebted country—the United Kingdom, and Australia. Nonindustrialized countries and countries with strict bankruptcy laws such as Germany, however, tend to have relatively low credit card debt.
Debit cards are in some ways similar to credit cards—for example, in terms of appearance and functionality. However, unlike credit cards, when a debit card transaction occurs, the amount is immediately deducted from the bank account.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1615 2022-12-28 02:18:15
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1518) Aerodrome
Summary
An aerodrome is a place or area where small aircraft can land and take off.
2. a landing field for airplanes that has extensive buildings, equipment, shelters, etc.; airport.
3. An airdrome is a place or area where small aircraft can land and take off.
Details
An aerodrome (Commonwealth English) or airdrome (American English) is a location from which aircraft flight operations take place, regardless of whether they involve air cargo, passengers, or neither, and regardless of whether it is for public or private use. Aerodromes include small general aviation airfields, large commercial airports, and military air bases.
The term airport may imply a certain stature (having satisfied certain certification criteria or regulatory requirements) that not all aerodromes may have achieved. That means that all airports are aerodromes, but not all aerodromes are airports. Usage of the term "aerodrome" remains more common in Ireland and Commonwealth nations, and is conversely almost unknown in American English, where the term "airport" is applied almost exclusively.
A water aerodrome is an area of open water used regularly by seaplanes, floatplanes or amphibious aircraft for landing and taking off.
In formal terminology, as defined by the International Civil Aviation Organization (ICAO), an aerodrome is "a defined area on land or water (including any buildings, installations, and equipment) intended to be used either wholly or in part for the arrival, departure, and surface movement of aircraft."
Etymology
The word aerodrome derives from Ancient Greek air, and road or course, literally meaning air course. An ancient linguistic parallel is hippodrome (a stadium for horse racing and chariot racing), derived from (híppos), horse, and (drómos), course. A modern linguistic parallel is velodrome, an arena for velocipedes. Αεροδρόμιο is the word for airport in Modern Greek, which transliterates as aerodromio.
In British military usage, the Royal Flying Corps in the First World War, and the Royal Air Force in the First and Second World Wars, used the term—it had the advantage that their French allies, on whose soil they were often based, and with whom they co-operated, used the cognate term aérodrome.
In Canada and Australia, aerodrome is a legal term of art for any area of land or water used for aircraft operation, regardless of facilities.
International Civil Aviation Organization (ICAO) documents use the term aerodrome, for example, in the Annex to the ICAO Convention about aerodromes, their physical characteristics, and their operation. However, the terms airfield or airport mostly superseded[citation needed] use of aerodrome after the Second World War, in colloquial language.
History
In the early days of aviation, when there were no paved runways and all landing fields were grass, a typical airfield might permit takeoffs and landings in only a couple of directions, much like today's airports, whereas an aerodrome was distinguished, by virtue of its much greater size, by its ability to handle landings and takeoffs in any direction. The ability to always take off and land directly into the wind, regardless of the wind's direction, was an important advantage in the earliest days of aviation when an airplane's performance in a crosswind takeoff or landing might be poor or even dangerous. The development of differential braking in aircraft, improved aircraft performance, utilization of paved runways, and the fact that a circular aerodrome required much more space than did the "L" or triangle shaped airfield, eventually made the early aerodromes obsolete.
The unimproved airfield remains a phenomenon in military aspects. The DHC-4 Caribou served in the United States military in Vietnam (designated as the CV-2), landing on rough, unimproved airfields where the C-130 Hercules workhorse could not operate. Earlier, the Ju 52 and Fieseler Storch could do the same, one example of the latter taking off from the Führerbunker whilst completely surrounded by Russian troops.
Types:
Airport
In colloquial use in certain environments, the terms airport and aerodrome are often interchanged. However, in general, the term airport may imply or confer a certain stature upon the aviation facility that other aerodromes may not have achieved. In some jurisdictions, airport is a legal term of art reserved exclusively for those aerodromes certified or licensed as airports by the relevant civil aviation authority after meeting specified certification criteria or regulatory requirements.
Air base
An air base is an aerodrome with significant facilities to support aircraft and crew. The term is usually reserved for military bases, but also applies to civil seaplane bases.
Airstrip
An airstrip is a small aerodrome that consists only of a runway with perhaps fueling equipment. They are generally in remote locations, e.g. Airstrips in Tanzania. Many airstrips (now mostly abandoned) were built on the hundreds of islands in the Pacific Ocean during the Second World War. A few airstrips grew to become full-fledged airbases as the strategic or economic importance of a region increased over time.
An Advanced Landing Ground was a temporary airstrip used by the Allies in the run-up to and during the invasion of Normandy, and these were built both in Britain, and on the continent.
Water aerodrome
A water aerodrome or seaplane base is an area of open water used regularly by seaplanes, floatplanes and amphibious aircraft for landing and taking off. It may have a terminal building on land and/or a place where the plane can come to shore and dock like a boat to load and unload ((for example, Yellowknife Water Aerodrome). Some are co-located with a land based airport and are certified airports in their own right. These include Vancouver International Water Airport and Vancouver International Airport. Others, such as Vancouver Harbour Flight Centre have their own control tower, Vancouver Harbour Control Tower.
By country:
Canada
The Canadian Aeronautical Information Manual says "...for the most part, all of Canada can be an aerodrome", however there are also "registered aerodromes" and "certified airports". To become a registered aerodrome, the operator must maintain certain standards and keep the Minister of Transport informed of any changes. To be certified as an airport the aerodrome, which usually supports commercial operations, must meet safety standards. Nav Canada, the private company responsible for air traffic control services in Canada, publishes the Canada Flight Supplement, a directory of all registered Canadian land aerodromes, as well as the Canada Water Aerodrome Supplement (CWAS).
Republic of Ireland
Casement Aerodrome is the main military airport used by the Irish Air Corps. The term "aerodrome" is used for airports and airfields of lesser importance in Ireland, such as those at Abbeyshrule; Bantry; Birr; Inisheer; Inishmaan; Inishmore; Newcastle, County Wicklow; and Trim.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1616 2022-12-29 00:17:48
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1519) Chemical Element
Summary
A chemical element is a species of atoms that have a given number of protons in their nuclei, including the pure substance consisting only of that species. Unlike chemical compounds, chemical elements cannot be broken down into simpler substances by any chemical reaction. The number of protons in the nucleus is the defining property of an element, and is referred to as its atomic number (represented by the symbol Z) – all atoms with the same atomic number are atoms of the same element. Almost all of the baryonic matter of the universe is composed of chemical elements (among rare exceptions are neutron stars). When different elements undergo chemical reactions, atoms are rearranged into new compounds held together by chemical bonds. Only a minority of elements, such as silver and gold, are found uncombined as relatively pure native element minerals. Nearly all other naturally occurring elements occur in the Earth as compounds or mixtures. Air is primarily a mixture of the elements nitrogen, oxygen, and argon, though it does contain compounds including carbon dioxide and water.
The history of the discovery and use of the elements began with primitive human societies that discovered native minerals like carbon, sulfur, copper and gold (though the concept of a chemical element was not yet understood). Attempts to classify materials such as these resulted in the concepts of classical elements, alchemy, and various similar theories throughout human history. Much of the modern understanding of elements developed from the work of Dmitri Mendeleev, a Russian chemist who published the first recognizable periodic table in 1869. This table organizes the elements by increasing atomic number into rows ("periods") in which the columns ("groups") share recurring ("periodic") physical and chemical properties. The periodic table summarizes various properties of the elements, allowing chemists to derive relationships between them and to make predictions about compounds and potential new ones.
By November 2016, the International Union of Pure and Applied Chemistry had recognized a total of 118 elements. The first 94 occur naturally on Earth, and the remaining 24 are synthetic elements produced in nuclear reactions. Save for unstable radioactive elements (radionuclides) which decay quickly, nearly all of the elements are available industrially in varying amounts. The discovery and synthesis of further new elements is an ongoing area of scientific study.
Details
A chemical element, also called element, is any substance that cannot be decomposed into simpler substances by ordinary chemical processes. Elements are the fundamental materials of which all matter is composed.
This article considers the origin of the elements and their abundances throughout the universe. The geochemical distribution of these elementary substances in the Earth’s crust and interior is treated in some detail, as is their occurrence in the hydrosphere and atmosphere. The article also discusses the periodic law and the tabular arrangement of the elements based on it.
General observations
At present there are 118 known chemical elements. About 20 percent of them do not exist in nature (or are present only in trace amounts) and are known only because they have been synthetically prepared in the laboratory. Of the known elements, 11 (hydrogen, nitrogen, oxygen, fluorine, chlorine, and the six noble gases) are gases under ordinary conditions, two (bromine and mercury) are liquids (two more, cesium and gallium, melt at about or just above room temperature), and the rest are solids. Elements can combine with one another to form a wide variety of more complex substances called compounds. The number of possible compounds is almost infinite; perhaps a million are known, and more are being discovered every day. When two or more elements combine to form a compound, they lose their separate identities, and the product has characteristics quite different from those of the constituent elements. The gaseous elements hydrogen and oxygen, for example, with quite different properties, can combine to form the compound water, which has altogether different properties from either oxygen or hydrogen. Water clearly is not an element because it consists of, and actually can be decomposed chemically into, the two substances hydrogen and oxygen; these two substances, however, are elements because they cannot be decomposed into simpler substances by any known chemical process. Most samples of naturally occurring matter are physical mixtures of compounds. Seawater, for example, is a mixture of water and a large number of other compounds, the most common of which is sodium chloride, or table salt. Mixtures differ from compounds in that they can be separated into their component parts by physical processes; for example, the simple process of evaporation separates water from the other compounds in seawater.
Historical development of the concept of element
The modern concept of an element is unambiguous, depending as it does on the use of chemical and physical processes as a means of discriminating elements from compounds and mixtures. The existence of fundamental substances from which all matter is made, however, has been the basis of much theoretical speculation since the dawn of history. The ancient Greek philosophers Thales, Anaximenes, and Heracleitus each suggested that all matter is composed of one essential principle—or element. Thales believed this element to be water; Anaximenes suggested air; and Heracleitus, fire. Another Greek philosopher, Empedocles, expressed a different belief—that all substances are composed of four elements: air, earth, fire, and water. Aristotle agreed and emphasized that these four elements are bearers of fundamental properties, dryness and heat being associated with fire, heat and moisture with air, moisture and cold with water, and cold and dryness with earth. In the thinking of these philosophers all other substances were supposed to be combinations of the four elements, and the properties of substances were thought to reflect their elemental compositions. Thus, Greek thought encompassed the idea that all matter could be understood in terms of elemental qualities; in this sense, the elements themselves were thought of as nonmaterial. The Greek concept of an element, which was accepted for nearly 2,000 years, contained only one aspect of the modern definition—namely, that elements have characteristic properties.
In the latter part of the Middle Ages, as alchemists became more sophisticated in their knowledge of chemical processes, the Greek concepts of the composition of matter became less satisfactory. Additional elemental qualities were introduced to accommodate newly discovered chemical transformations. Thus, sulfur came to represent the quality of combustibility, mercury that of volatility or fluidity, and salt that of fixity in fire (or incombustibility). These three alchemical elements, or principles, also represented abstractions of properties reflecting the nature of matter, not physical substances.
The important difference between a mixture and a chemical compound eventually was understood, and in 1661 the English chemist Robert Boyle recognized the fundamental nature of a chemical element. He argued that the four Greek elements could not be the real chemical elements because they cannot combine to form other substances nor can they be extracted from other substances. Boyle stressed the physical nature of elements and related them to the compounds they formed in the modern operational way.
In 1789 the French chemist Antoine-Laurent Lavoisier published what might be considered the first list of elemental substances based on Boyle’s definition. Lavoisier’s list of elements was established on the basis of a careful, quantitative study of decomposition and recombination reactions. Because he could not devise experiments to decompose certain substances, or to form them from known elements, Lavoisier included in his list of elements such substances as lime, alumina, and silica, which now are known to be very stable compounds. That Lavoisier still retained a measure of influence from the ancient Greek concept of the elements is indicated by his inclusion of light and heat (caloric) among the elements.
Seven substances recognized today as elements—gold, silver, copper, iron, lead, tin, and mercury—were known to the ancients because they occur in nature in relatively pure form. They are mentioned in the Bible and in an early Hindu medical treatise, the Caraka-samhita. Sixteen other elements were discovered in the second half of the 18th century, when methods of separating elements from their compounds became better understood. Eighty-two more followed after the introduction of quantitative analytical methods.
The atomic nature of the elements
Paralleling the development of the concept of elements was an understanding of the nature of matter. At various times in history, matter has been considered to be either continuous or discontinuous. Continuous matter is postulated to be homogeneous and divisible without limit, each part exhibiting identical properties regardless of size. This was essentially the point of view taken by Aristotle when he associated his elemental qualities with continuous matter. Discontinuous matter, on the other hand, is conceived of as particulate—that is, divisible only up to a point, the point at which certain basic units called atoms are reached. According to this concept, also known as the atomic hypothesis, subdivision of the basic unit (atom) could give rise only to particles with profoundly different properties. Atoms, then, would be the ultimate carriers of the properties associated with bulk matter.
The atomic hypothesis is usually credited to the Greek philosopher Democritus, who considered all matter to be composed of atoms of the four elements—earth, air, fire, and water. But Aristotle’s concept of continuous matter generally prevailed and influenced thought until experimental findings in the 16th century forced a return to the atomic theory. Two types of experimental evidence gave support to the atomic hypothesis: first, the detailed behaviour of gaseous substances and, second, the quantitative weight relationships observed with a variety of chemical reactions. The English chemist John Dalton was the first to explain the empirically derived laws of chemical combination by postulating the existence of atoms with unique sets of properties. At the time, chemical combining power (valence) and relative atomic weights were the properties of most interest. Subsequently numerous independent experimental verifications of the atomic hypothesis were carried out, and today it is universally accepted. Indeed, in 1969 individual uranium and thorium atoms were actually observed by means of an electron microscope.
The structure of atoms
Atoms of elemental substances are themselves complex structures composed of more fundamental particles called protons, neutrons, and electrons. Experimental evidence indicates that, within an atom, a small nucleus, which generally contains both protons and neutrons, is surrounded by a swarm, or cloud, of electrons. The fundamental properties of these subatomic particles are their weight and electrical charge. Whereas protons carry a positive charge and electrons a negative one, neutrons are electrically neutral. The diameter of an atom (about {10}^{-8} centimetre) is 10,000 times larger than that of its nucleus. Neutrons and protons, which are collectively called nucleons, have relative weights of approximately one atomic mass unit, whereas an electron is only about 1/2000 as heavy. Because neutrons and protons occur in the nucleus, virtually all of the mass of the atom is concentrated there. The number of protons in the nucleus is equivalent to the atomic number of the element. The total number of protons and neutrons is called the mass number because it equals the relative weight of that atom compared to other atoms. Because the atom itself is electrically neutral, the atomic number represents not only the number of protons, or positive charges, in the nucleus but also the number of electrons, or negative charges, in the extranuclear region of the atom.
The chemical characteristics of elements are intimately related to the number and arrangement of electrons in their atoms. Thus, elements are completely distinguishable from each other by their atomic numbers. The realization that such is the case leads to another definition of an element, namely, a substance, all atoms of which have the same atomic number.
The existence of isotopes
Careful experimental examination of naturally occurring samples of many pure elements shows that not all the atoms present have the same atomic weight, even though they all have the same atomic number. Such a situation can occur only if the atoms have different numbers of neutrons in their nuclei. Such groups of atoms—with the same atomic number but with different relative weights—are called isotopes. The number of isotopic forms that a naturally occurring element possesses ranges from one (e.g., fluorine) to as many as ten (e.g., tin); most of the elements have at least two isotopes. The atomic weight of an element is usually determined from large numbers of atoms containing the natural distribution of isotopes, and, therefore, it represents the average isotopic weight of the atoms constituting the sample. More recently, precision mass-spectrometric methods have been used to determine the distribution and weights of isotopes in various naturally occurring samples of elements.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1617 2022-12-29 03:01:37
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1520) The atomic nature of the elements
Paralleling the development of the concept of elements was an understanding of the nature of matter. At various times in history, matter has been considered to be either continuous or discontinuous. Continuous matter is postulated to be homogeneous and divisible without limit, each part exhibiting identical properties regardless of size. This was essentially the point of view taken by Aristotle when he associated his elemental qualities with continuous matter. Discontinuous matter, on the other hand, is conceived of as particulate—that is, divisible only up to a point, the point at which certain basic units called atoms are reached. According to this concept, also known as the atomic hypothesis, subdivision of the basic unit (atom) could give rise only to particles with profoundly different properties. Atoms, then, would be the ultimate carriers of the properties associated with bulk matter.
The atomic hypothesis is usually credited to the Greek philosopher Democritus, who considered all matter to be composed of atoms of the four elements—earth, air, fire, and water. But Aristotle’s concept of continuous matter generally prevailed and influenced thought until experimental findings in the 16th century forced a return to the atomic theory. Two types of experimental evidence gave support to the atomic hypothesis: first, the detailed behaviour of gaseous substances and, second, the quantitative weight relationships observed with a variety of chemical reactions. The English chemist John Dalton was the first to explain the empirically derived laws of chemical combination by postulating the existence of atoms with unique sets of properties. At the time, chemical combining power (valence) and relative atomic weights were the properties of most interest. Subsequently numerous independent experimental verifications of the atomic hypothesis were carried out, and today it is universally accepted. Indeed, in 1969 individual uranium and thorium atoms were actually observed by means of an electron microscope.
The structure of atoms
Atoms of elemental substances are themselves complex structures composed of more fundamental particles called protons, neutrons, and electrons. Experimental evidence indicates that, within an atom, a small nucleus, which generally contains both protons and neutrons, is surrounded by a swarm, or cloud, of electrons. The fundamental properties of these subatomic particles are their weight and electrical charge. Whereas protons carry a positive charge and electrons a negative one, neutrons are electrically neutral. The diameter of an atom (about {10}^{-8} centimetre) is 10,000 times larger than that of its nucleus. Neutrons and protons, which are collectively called nucleons, have relative weights of approximately one atomic mass unit, whereas an electron is only about 1/2000 as heavy. Because neutrons and protons occur in the nucleus, virtually all of the mass of the atom is concentrated there. The number of protons in the nucleus is equivalent to the atomic number of the element. The total number of protons and neutrons is called the mass number because it equals the relative weight of that atom compared to other atoms. Because the atom itself is electrically neutral, the atomic number represents not only the number of protons, or positive charges, in the nucleus but also the number of electrons, or negative charges, in the extranuclear region of the atom.
The chemical characteristics of elements are intimately related to the number and arrangement of electrons in their atoms. Thus, elements are completely distinguishable from each other by their atomic numbers. The realization that such is the case leads to another definition of an element, namely, a substance, all atoms of which have the same atomic number.
The existence of isotopes
Careful experimental examination of naturally occurring samples of many pure elements shows that not all the atoms present have the same atomic weight, even though they all have the same atomic number. Such a situation can occur only if the atoms have different numbers of neutrons in their nuclei. Such groups of atoms—with the same atomic number but with different relative weights—are called isotopes. The number of isotopic forms that a naturally occurring element possesses ranges from one (e.g., fluorine) to as many as ten (e.g., tin); most of the elements have at least two isotopes. The atomic weight of an element is usually determined from large numbers of atoms containing the natural distribution of isotopes, and, therefore, it represents the average isotopic weight of the atoms constituting the sample. More recently, precision mass-spectrometric methods have been used to determine the distribution and weights of isotopes in various naturally occurring samples of elements.
It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1618 2022-12-29 21:22:13
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1521) Origin of the Elements
Summary
Nucleosynthesis is the process that creates new atomic nuclei from pre-existing nucleons (protons and neutrons) and nuclei. According to current theories, the first nuclei were formed a few minutes after the Big Bang, through nuclear reactions in a process called Big Bang nucleosynthesis. After about 20 minutes, the universe had expanded and cooled to a point at which these high-energy collisions among nucleons ended, so only the fastest and simplest reactions occurred, leaving our universe containing hydrogen and helium. The rest is traces of other elements such as lithium and the hydrogen isotope deuterium. Nucleosynthesis in stars and their explosions later produced the variety of elements and isotopes that we have today, in a process called cosmic chemical evolution. The amounts of total mass in elements heavier than hydrogen and helium (called 'metals' by astrophysicists) remains small (few percent), so that the universe still has approximately the same composition.
Stars fuse light elements to heavier ones in their cores, giving off energy in the process known as stellar nucleosynthesis. Nuclear fusion reactions create many of the lighter elements, up to and including iron and nickel in the most massive stars. Products of stellar nucleosynthesis remain trapped in stellar cores and remnants except if ejected through stellar winds and explosions. The neutron capture reactions of the r-process and s-process create heavier elements, from iron upwards.
Supernova nucleosynthesis within exploding stars is largely responsible for the elements between oxygen and rubidium: from the ejection of elements produced during stellar nucleosynthesis; through explosive nucleosynthesis during the supernova explosion; and from the r-process (absorption of multiple neutrons) during the explosion.
Neutron star mergers are a recently discovered major source of elements produced in the r-process. When two neutron stars collide, a significant amount of neutron-rich matter may be ejected which then quickly forms heavy elements.
Cosmic ray spallation is a process wherein cosmic rays impact nuclei and fragment them. It is a significant source of the lighter nuclei, particularly 3He, 9Be and 10,11B, that are not created by stellar nucleosynthesis. Cosmic ray spallation can occur in the interstellar medium, on asteroids and meteoroids, or on Earth in the atmosphere or in the ground. This contributes to the presence on Earth of cosmogenic nuclides.
On Earth new nuclei are also produced by radiogenesis, the decay of long-lived, primordial radionuclides such as uranium, thorium, and potassium-40.
Details
The fundamental reaction that produces the huge amounts of energy radiated by the Sun and most other stars is the fusion of the lightest element, hydrogen, its nucleus having a single proton, into helium, the second lightest and second most abundant, with a nucleus consisting of two protons and two neutrons. In many stars the production of helium is followed by the fusion of helium into heavier elements, up to iron. The still heavier elements cannot be made in energy-releasing fusion reactions; an input of energy is required to produce them.
The proportion of different elements within a star—i.e., its chemical composition—is gradually changed by nuclear fusion reactions. This change is initially concentrated in the central regions of the star where it cannot be directly observed, but it alters some observable properties of the star, such as brightness and surface temperature, and these alterations are taken as evidence of what is going on in the interior. Some stars become unstable and discharge some transmuted matter into interstellar space; this leads to a change in the chemical composition of the interstellar medium and of any stars subsequently formed. The main problem concerned with the origin of the chemical elements is to decide to what extent the chemical composition of the stars seen today differs from the initial chemical composition of the universe and to determine where the change in chemical composition has been produced. Reference is made in this article to the chemical composition of the universe, but most of the observations refer to our own and neighbouring galaxies.
Cosmic abundances of the elements
The relative numbers of atoms of the various elements are usually described as the abundances of the elements. The chief sources of data from which information is gained about present-day abundances of the elements are observations of the chemical composition of stars and gas clouds in the Galaxy, which contains the solar system and part of which is visible to the naked eye as the Milky Way; of neighbouring galaxies; of the Earth, Moon, and meteorites; and of the cosmic rays.
Stars and gas clouds
Atoms absorb and emit light, and the atoms of each element do so at specific and characteristic wavelengths. A spectroscope spreads out these wavelengths of light from any source into a spectrum of bright-coloured lines, a different pattern identifying each element. When light from an unknown source is analyzed in a spectroscope, the different patterns of bright lines in the spectrum reveal which elements emitted the light. Such a pattern is called an emission, or bright-line, spectrum. When light passes through a gas or cloud at a lower temperature than the light source, the gas absorbs at its identifying wavelengths, and a dark-line, or absorption, spectrum will be formed.
Thus, absorption and emission lines in the spectrum of light from stars yield information concerning the chemical composition of the source of light and of the chemical composition of clouds through which the light has traveled. The absorption lines may be formed either by interstellar clouds or by the cool outer layers of the stars. The chemical composition of a star is obtained by a study of absorption lines formed in its atmosphere.
The presence of an element can, therefore, be detected easily, but it is more difficult to determine how much of it there is. The intensity of an absorption line depends not only on the total number of atoms of the element in the atmosphere of the star but also on the number of these atoms that are in a state capable of absorbing radiation of the relevant wavelength and the probability of absorption occurring. The absorption probability can, in principle, be measured in the laboratory, but the whole physical structure of the atmosphere must be calculated to determine the number of absorbing atoms. Naturally, it is easier to study the chemical composition of the Sun than of other stars, but, even for the Sun, after many decades of study, there are still significant uncertainties of chemical composition. The spectra of stars differ considerably, and originally it was believed that this indicated a wide variety of chemical composition. Subsequently, it was realized that it is the surface temperature of a star that largely determines which spectral lines are excited and that most stars have similar chemical compositions.
There are, however, differences in chemical composition among stars, and these differences are important in a study of the origin of the elements. Studies of the processes that operate during stellar evolution enable estimates to be made of the ages of stars. There is, for example, a clear tendency for very old stars to have smaller quantities of elements heavier than helium than do younger stars. This suggests that the Galaxy originally contained little of the so-called heavy elements (elements beyond helium in the periodic table); and the variation of chemical composition with age suggests that heavy elements must have been produced more rapidly in the Galaxy’s early history than now. Observations are also beginning to indicate that chemical composition is dependent on position in the Galaxy as well as age, with a higher heavy-element content near the galactic centre.
In addition to stars, the Galaxy contains interstellar gas and dust. Some of the gas is very cold, but some forms hot clouds, the gaseous nebulae, the chemical composition of which can be studied in some detail. The chemical composition of the gas seems to resemble that of young stars. This is in agreement with the theory that young stars are formed from the interstellar gas.
Cosmic rays
High-energy electrons and atomic nuclei known as cosmic rays reach the Earth from all directions in the Galaxy. Their chemical composition can be observed only to a limited extent, but this can give some information about their place of origin and possibly about the origin of the chemical elements.
The cosmic rays are observed to be proportionately richer in heavy elements than are the stars, and they also contain more of the light elements lithium, beryllium, and boron, which are very rare in stars. One particularly interesting suggestion is that transuranium nuclei may have been detected in the cosmic rays. Uranium is element 92, the most massive naturally occurring on Earth; 20 elements beyond uranium (called the transuranium series) have been created artificially. All transuranium nuclei are highly unstable, which would seem to indicate that the cosmic rays must have been produced in the not too distant past.
It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1619 2022-12-30 17:35:52
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1522) Chemical Compound
Summary
A chemical compound is a chemical substance composed of many identical molecules (or molecular entities) containing atoms from more than one chemical element held together by chemical bonds. A molecule consisting of atoms of only one element is therefore not a compound. A compound can be transformed into a different substance by a chemical reaction, which may involve interactions with other substances. In this process, bonds between atoms may be broken and/or new bonds formed.
There are four major types of compounds, distinguished by how the constituent atoms are bonded together. Molecular compounds are held together by covalent bonds; ionic compounds are held together by ionic bonds; intermetallic compounds are held together by metallic bonds; coordination complexes are held together by coordinate covalent bonds. Non-stoichiometric compounds form a disputed marginal case.
A chemical formula specifies the number of atoms of each element in a compound molecule, using the standard chemical symbols with numerical subscripts. Many chemical compounds have a unique CAS number identifier assigned by the Chemical Abstracts Service. Globally, more than 350,000 chemical compounds (including mixtures of chemicals) have been registered for production and use.
Details
A chemical compound is any substance composed of identical molecules consisting of atoms of two or more chemical elements.
All the matter in the universe is composed of the atoms of more than 100 different chemical elements, which are found both in pure form and combined in chemical compounds. A sample of any given pure element is composed only of the atoms characteristic of that element, and the atoms of each element are unique. For example, the atoms that constitute carbon are different from those that make up iron, which are in turn different from those of gold. Every element is designated by a unique symbol consisting of one, two, or three letters arising from either the current element name or its original (often Latin) name. For example, the symbols for carbon, hydrogen, and oxygen are simply C, H, and O, respectively. The symbol for iron is Fe, from its original Latin name ferrum. The fundamental principle of the science of chemistry is that the atoms of different elements can combine with one another to form chemical compounds. Methane, for example, which is formed from the elements carbon and hydrogen in the ratio four hydrogen atoms for each carbon atom, is known to contain distinct CH4 molecules. The formula of a compound—such as CH4—indicates the types of atoms present, with subscripts representing the relative numbers of atoms (although the numeral 1 is never written).
Water, which is a chemical compound of hydrogen and oxygen in the ratio two hydrogen atoms for every oxygen atom, contains H2O molecules. Sodium chloride is a chemical compound formed from sodium (Na) and chlorine (Cl) in a 1:1 ratio. Although the formula for sodium chloride is NaCl, the compound does not contain actual NaCl molecules. Rather, it contains equal numbers of sodium ions with a charge of positive one (Na+) and chloride ions with a charge of negative one (Cl−). (See below Trends in the chemical properties of the elements for a discussion of the process for changing uncharged atoms to ions [i.e., species with a positive or negative net charge].) The substances mentioned above exemplify the two basic types of chemical compounds: molecular (covalent) and ionic. Methane and water are composed of molecules; that is, they are molecular compounds. Sodium chloride, on the other hand, contains ions; it is an ionic compound.
The atoms of the various chemical elements can be likened to the letters of the alphabet: just as the letters of the alphabet are combined to form thousands of words, the atoms of the elements can combine in various ways to form a myriad of compounds. In fact, there are millions of chemical compounds known, and many more millions are possible but have not yet been discovered or synthesized. Most substances found in nature—such as wood, soil, and rocks—are mixtures of chemical compounds. These substances can be separated into their constituent compounds by physical methods, which are methods that do not change the way in which atoms are aggregated within the compounds. Compounds can be broken down into their constituent elements by chemical changes. A chemical change (that is, a chemical reaction) is one in which the organization of the atoms is altered. An example of a chemical reaction is the burning of methane in the presence of molecular oxygen (O2) to form carbon dioxide (CO2) and water.
CH4 + 2O2 → CO2 + 2H2O
In this reaction, which is an example of a combustion reaction, changes occur in the way that the carbon, hydrogen, and oxygen atoms are bound together in the compounds.
Chemical compounds show a bewildering array of characteristics. At ordinary temperatures and pressures, some are solids, some are liquids, and some are gases. The colours of the various compounds span those of the rainbow. Some compounds are highly toxic to humans, whereas others are essential for life. Substitution of only a single atom within a compound may be responsible for changing the colour, odour, or toxicity of a substance. So that some sense can be made out of this great diversity, classification systems have been developed. An example cited above classifies compounds as molecular or ionic. Compounds are also classified as organic or inorganic. Organic compounds (see below Organic compounds), so called because many of them were originally isolated from living organisms, typically contain chains or rings of carbon atoms. Because of the great variety of ways that carbon can bond with itself and other elements, there are more than nine million organic compounds. The compounds that are not considered to be organic are called inorganic compounds.
Within the broad classifications of organic and inorganic are many subclasses, mainly based on the specific elements or groups of elements that are present. For example, among the inorganic compounds, oxides contain O2− ions or oxygen atoms, hydrides contain H− ions or hydrogen atoms, sulfides contain S2− ions, and so forth. Subclasses of organic compounds include alcohols (which contain the ―OH group), carboxylic acids (characterized by the ―COOH group), amines (which have an ―NH2 group), and so on.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1620 2022-12-31 14:04:21
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1523) Mixture
Summary
In chemistry, a mixture is a material made up of two or more different chemical substances which are not chemically bonded. A mixture is the physical combination of two or more substances in which the identities are retained and are mixed in the form of solutions, suspensions and colloids.
Mixtures are one product of mechanically blending or mixing chemical substances such as elements and compounds, without chemical bonding or other chemical change, so that each ingredient substance retains its own chemical properties and makeup. Despite the fact that there are no chemical changes to its constituents, the physical properties of a mixture, such as its melting point, may differ from those of the components. Some mixtures can be separated into their components by using physical (mechanical or thermal) means. Azeotropes are one kind of mixture that usually poses considerable difficulties regarding the separation processes required to obtain their constituents (physical or chemical processes or, even a blend of them).
Details
A mixture is a material that is made up of two more chemical compounds or substances that do not combine together chemically. It is actually the physical combination of two or more substances that are able to retain their identities while they are mixed in form of solutions, suspensions, or colloids. You can separate them by physical methods. In any mixture, the various components do not form through any kind of chemical change. Therefore, the components’ individual properties remain intact.
What is a Mixture?
Mixtures are substances that are made up of two or more different types of substances. Physical means can be used to separate them. A solution of salt and water, a combination of sugar and water, various gases, air, and so on are examples. The different components of any combination do not unite through any chemical changes. As a result, the components retain their distinct characteristics.
In addition, unlike in a compound, the components in a mixture do not combine chemically to produce new material. Instead, they just mix and maintain their original characteristics. Because the components are not in set quantities, the lemonade shown above is a combination. It might be made with more or less lemon juice, or with more or less sugar, and still be called lemonade.
Properties of Mixtures
* All the components or substances in a mixture retain their original physical properties.
* The mixture can be separated into its components physically by using some techniques.
* The components in a mixture may or may not be in a fixed proportion and can vary in quantity.
Examples of Mixtures
* Smog is a mixture of Smoke and Fog.
* Cement is a mixture of Sand, Water and Gravel.
* Sea Water is a mixture of Water and Salt.
* Soil is a mixture of Minerals, Air, Organic materials, Water, and Living Organisms.
* Blood is a mixture of Plasma, White Blood Cells, Red Blood Cells, and Platelets.
* Gasoline is a mixture of Hydrocarbons, Petroleum, and Fuel Additives.
* Brass is an Alloy and is a mixture of metals like Zinc and Copper.
* Nichrome is also an Alloy and is a mixture of metals like Chromium, Iron, and Nickel.
* Bleach is a mixture of Caustic Soda, Chlorine, and Water.
Types of Mixtures
Mixtures can be broadly classified into two main categories. These are
* Homogeneous Mixtures
* Heterogeneous Mixtures
Types of Mixtures:
What is a Homogeneous Mixture?
Homo means sane. The mixtures in which the components have a uniform distribution throughout the mixture are known as homogeneous mixtures. For example, salt and water is homogeneous mixture as the taste of the water will be the same if you take a sip from any portion of water. This shows that salt is uniformly distributed in the mixture.
e.g. Salt and water, Sugar and water, Alcohol and water, etc.
Properties of Homogeneous Mixtures
* These have a uniform distribution of components throughout the mixture.
* The centrifugal force cannot be used to separate the components.
* Homogeneous mixtures do not exhibit the Tyndall effect i.e. the scattering of light by the particles in the medium when a light beam is an incident on the mixture. The path of light becomes visible due to the scattering of the light beam.
* The particle size is <1nm.
* All the solutions are homogeneous mixtures.
Examples of Homogeneous Mixture
Air,
Any type of soft drink,
Cooking Gas,
Coffee,
Cement,
Vinegar, etc.
What is a Heterogeneous Mixture?
Hetero means different. The mixtures in which the components do not have a uniform distribution throughout the mixture which means in which the components are unevenly distributed are said to be heterogeneous mixtures. For example, sand and water is an example of the heterogeneous mixture as sand does not distribute uniformly in water. e.g. Sand and water, Sugar and salt, Ice in water, etc.
Properties of Heterogeneous Mixtures
* The components of heterogeneous mixture do not uniform distribute throughout the mixture.
* You can draw a boundary between the components by just looking at the mixture.
* The particle size ranges between 1nm to 1 μm.
* They can exhibit the Tyndall effect.
Examples of Heterogeneous Mixture
Iron Ore,
Granite,
Milk and Cereal,
Sugar and Salt,
Water and Oil,
Rice and Beans,
Water and Sand, etc.
Difference Between Mixture and Compound
The compounds and mixtures described are as follows:
* When two or more elements are combined together are called Compounds.
For example, Water, Salt, etc.
* When two or more substances are mixed together physically are called Mixture.
For example, Air, Smog etc.
It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1621 2023-01-01 12:49:27
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1524) Sunlight
Summary
Sunlight is a portion of the electromagnetic radiation given off by the Sun, in particular infrared, visible, and ultraviolet light. On Earth, sunlight is scattered and filtered through Earth's atmosphere, and is obvious as daylight when the Sun is above the horizon. When direct solar radiation is not blocked by clouds, it is experienced as sunshine, a combination of bright light and radiant heat. When blocked by clouds or reflected off other objects, sunlight is diffused. Sources estimate a global average of between 164 watts to 340 watts per square meter over a 24-hour day; this figure is estimated by NASA to be about a quarter of Earth's average total solar irradiance.
The ultraviolet radiation in sunlight has both positive and negative health effects, as it is both a requisite for vitamin D3 synthesis and a mutagen.
Sunlight takes about 8.3 minutes to reach Earth from the surface of the Sun. A photon starting at the center of the Sun and changing direction every time it encounters a charged particle would take between 10,000 and 170,000 years to get to the surface.
Sunlight is a key factor in photosynthesis, the process used by plants and other autotrophic organisms to convert light energy, normally from the Sun, into chemical energy that can be used to synthesize carbohydrates and to fuel the organisms' activities.
Details
Sunlight, also called sunshine, is solar radiation that is visible at Earth’s surface. The amount of sunlight is dependent on the extent of the daytime cloud cover. Some places on Earth receive more than 4,000 hours per year of sunlight (more than 90 percent of the maximum possible), as in the Sahara; others receive less than 2,000 hours, as in regions of frequent storminess, such as Scotland and Iceland. Over much of the middle-latitude region of the world, the amount of sunlight varies regularly as the day progresses, owing to greater cloud cover in the early morning and during the late afternoon.
Ordinarily, sunlight is broken down into three major components: (1) visible light, with wavelengths between 0.4 and 0.8 micrometre, (2) ultraviolet light, with wavelengths shorter than 0.4 micrometre, and (3) infrared radiation, with wavelengths longer than 0.8 micrometre. The visible portion constitutes nearly half of the total radiation received at the surface of Earth. Although ultraviolet light constitutes only a very small proportion of the total radiation, this component is extremely important. It produces vitamin D through the activation of ergosterol. Unfortunately, the polluted atmosphere over large cities robs solar radiation of a significant portion of its ultraviolet light. Infrared radiation has its chief merit in its heat-producing quality. Close to half of total solar radiation received at the surface of Earth is infrared.
On its path through the atmosphere the solar radiation is absorbed and weakened by various constituents of the atmosphere. It is also scattered by air molecules and dust particles. Short wavelengths of light, such as blue, scatter more easily than do the longer red wavelengths. This phenomenon is responsible for the varying colour of the sky at different times of day. When the sun is high overhead, its rays pass through the intervening atmosphere almost vertically. The light thus encounters less dust and fewer air molecules than it would if the sun were low on the horizon and its rays had a longer passage through the atmosphere. During this long passage the dominant blue wavelengths of light are scattered and blocked, leaving the longer, unobstructed red wavelengths to reach Earth and lend their tints to the sky at dawn and dusk.
An effective absorber of solar radiation is ozone, which forms by a photochemical process at heights of 10–50 km (6–30 miles) and filters out most of the radiation below 0.3 micrometre. Equally important as an absorber in the longer wavelengths is water vapour. A secondary absorber in the infrared range is carbon dioxide. These two filter out much of the solar energy with wavelengths longer than 1 micrometre.
The Eppley pyrheliometer measures the length of time that the surface receives sunlight and the sunshine’s intensity as well. It consists of two concentric silver rings of equal area, one blackened and the other whitened, connected to a thermopile. The sun’s rays warm the blackened ring more than they do the whitened one, and this temperature difference produces an electromotive force that is nearly proportional to the sunlight’s intensity. The electromotive force is automatically measured and recorded and yields a continuous record of the duration and intensity of the periods of sunlight.
/img/iea/jvwv5ylW6x/sunlight.jpg)
It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1622 2023-01-02 14:36:00
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1525) Transponder
Summary
A transponder is a wireless communications, monitoring, or control device that picks up and automatically responds to an incoming signal. The term is a contraction of the words transmitter and responder. Transponders can be either passive or active.
A passive transponder allows a computer or robot to identify an object. Magnetic labels, such as those on credit cards and store items, are common examples. A passive transponder must be used with an active sensor that decodes and transcribes the data the transponder contains. The transponder unit can be physically tiny, and its information can be sensed up to several feet away.
Simple active transponders are employed in location, identification, and navigation systems for commercial and private aircraft. An example is an RFID (radio-frequency identification) device that transmits a coded signal when it receives a request from a monitoring or control point. The transponder output signal is tracked, so the position of the transponder can be constantly monitored. The input (receiver) and output (transmitter) frequencies are preassigned. Transponders of this type can operate over distances of thousands of miles.
Sophisticated active transponders are used in communications satellites and on board space vehicles. They receive incoming signals over a range, or band, of frequencies, and retransmit the signals on a different band at the same time. The device is similar to a repeater of the sort used in land-based cellular telephone networks. The incoming signal, usually originating from a point on the earth's surface, is called the uplink. The outgoing signal, usually sent to a point or region on the surface, is the downlink. These transponders sometimes operate on an interplanetary scale.
Details
In telecommunications, a transponder is a device that, upon receiving a signal, emits a different signal in response. The term is a blend of transmitter and responder.
In air navigation or radio frequency identification, a flight transponder is an automated transceiver in an aircraft that emits a coded identifying signal in response to an interrogating received signal. In a communications satellite, a satellite transponder receives signals over a range of uplink frequencies, usually from a satellite ground station; the transponder amplifies them, and re-transmits them on a different set of downlink frequencies to receivers on Earth, often without changing the content of the received signal or signals.
Satellite/broadcast communications
A communications satellite’s channels are called transponders because each is a separate transceiver or repeater. With digital video data compression and multiplexing, several video and audio channels may travel through a single transponder on a single wideband carrier. Original analog video only has one channel per transponder, with subcarriers for audio and automatic transmission identification service (ATIS). Non-multiplexed radio stations can also travel in single channel per carrier (SCPC) mode, with multiple carriers (analog or digital) per transponder. This allows each station to transmit directly to the satellite, rather than paying for a whole transponder, or using landlines to send it to an earth station for multiplexing with other stations.
Optical communications
In optical fiber communications, a transponder is the element that sends and receives the optical signal from a fiber. A transponder is typically characterized by its data rate and the maximum distance the signal can travel.
The term "transponder" can apply to different items with important functional differences, mentioned across academic and commercial literature:
* according to one description, a transponder and transceiver are both functionally similar devices that convert a full-duplex electrical signal into a full-duplex optical signal. The difference between the two is that transceivers interface electrically with the host system using a serial interface, whereas transponders use a parallel interface to do so. In this view, transponders provide easier-to-handle lower-rate parallel signals, but are bulkier and consume more power than transceivers.
* according to another description, transceivers are limited to providing an electrical-optical function only (not differentiating between serial or parallel electrical interfaces), whereas transponders convert an optical signal at one wavelength to an optical signal at another wavelength (typically ITU standardized for DWDM communication). As such, transponders can be considered as two transceivers placed back-to-back. This view also seems to be held by e.g. Fujitsu.
As a result, difference in transponder functionality also might influence the functional description of related optical modules like transceivers and muxponders.
Aviation
Another type of transponder occurs in identification friend or foe (IFF) systems in military aviation and in air traffic control secondary surveillance radar (beacon radar) systems for general aviation and commercial aviation.[6] Primary radar works best with large all-metal aircraft, but not so well on small, composite aircraft. Its range is also limited by terrain and rain or snow and also detects unwanted objects such as automobiles, hills and trees. Furthermore, it cannot always estimate the altitude of an aircraft. Secondary radar overcomes these limitations but it depends on a transponder in the aircraft to respond to interrogations from the ground station to make the plane more visible.
Depending on the type of interrogation, the transponder sends back a transponder code (or "squawk code", Mode A) or altitude information (Mode C) to help air traffic controllers to identify the aircraft and to maintain separation between planes. Another mode called Mode S (Mode Select) is designed to help avoiding over-interrogation of the transponder (having many radars in busy areas) and to allow automatic collision avoidance. Mode S transponders are backward compatible with Modes A and C. Mode S is mandatory in controlled airspace in many countries. Some countries have also required, or are moving toward requiring, that all aircraft be equipped with Mode S, even in uncontrolled airspace. However, in the field of general aviation there have been objections to these moves, because of the cost, size, limited benefit to the users in uncontrolled airspace, and, in the case of balloons and gliders, the power requirements during long flights.
Transponders are used on some military aircraft to ensure ground personnel can verify the functionality of a missile’s flight termination system prior to launch. Such radar enhancing transponders are needed as the enclosed weapon bays on modern aircraft interfere with prelaunch, flight termination system verification performed by range safety personnel during training test launches. The transponders re-radiate the signals allowing for much longer communication distances.
Marine
The International Maritime Organization's International Convention for the Safety of Life at Sea (SOLAS) requires the Automatic Identification System (AIS) to be fitted aboard international voyaging ships with 300 or more gross tonnage (GT), and all passenger ships regardless of size. Although AIS transmitters/receivers are generally called transponders they generally transmit autonomously, although coast stations can interrogate class B transponders on smaller vessels for additional information. In addition, navigational aids often have transponders called RACON (radar beacons) designed to make them stand out on a ship's radar screen.
Automotive
Many modern automobiles have keys with transponders hidden inside the plastic head of the key. The user of the car may not even be aware that the transponder is there, because there are no buttons to press. When a key is inserted into the ignition lock cylinder and turned, the car's computer sends a signal to the transponder. Unless the transponder replies with a valid code, the computer will not allow the engine to be started. Transponder keys have no battery; they are energized by the signal itself.
Road
Electronic toll collection systems such as E-ZPass in the eastern United States use RFID transponders to identify vehicles. Highway 407 in Ontario, Canada, is one of the world's first completely automated toll highways.
Motorsport
Transponders are used in motorsport for lap timing purposes. A cable loop is dug into the race circuit near to the start/finish line. Each car has an active transponder with a unique ID code. When the racing car passes the start/finish line the lap time and the racing position is shown on the score board.
Passive and active RFID systems are used in off-road events such as Enduro and Hare and Hounds racing, the riders have a transponder on their person, normally on their arm. When they complete a lap they swipe or touch the receiver which is connected to a computer and log their lap time.
NASCAR uses transponders and cable loops placed at numerous points around the track to determine the lineup during a caution period. This system replaced a dangerous race back to the start-finish line.
Underwater
Sonar transponders operate under water and are used to measure distance and form the basis of underwater location marking, position tracking and navigation.
Gated communities
Transponders may also be used by residents to enter their gated communities. However, having more than one transponder causes problems. If a resident's car with simple transponder is parked in the vicinity, any vehicle can come up to the automated gate, triggering the gate interrogation signal, which may get an acceptable response from the resident's car. Such units properly installed might involve beamforming, unique transponders for each vehicle, or simply obliging vehicles to be stored away from the gate.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1623 2023-01-03 14:20:55
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1526) Asteroid
Summary
An asteroid is a minor planet of the inner Solar System. Sizes and shapes of asteroids vary significantly, ranging from 1-meter rocks to a dwarf planet almost 1000 km in diameter; they are rocky, metallic or icy bodies with no atmosphere.
Of the roughly one million known asteroids the greatest number are located between the orbits of Mars and Jupiter, approximately 2 to 4 AU from the Sun, in the main asteroid belt. Asteroids are generally classified to be of three types: C-type, M-type, and S-type. These were named after and are generally identified with carbonaceous, metallic, and silicaceous compositions, respectively. The size of asteroids varies greatly; the largest, Ceres, is almost 1,000 km (600 mi) across and qualifies as a dwarf planet. The total mass of all the asteroids combined is only 3% that of Earth's Moon. The majority of main belt asteroids follow slightly elliptical, stable orbits, revolving in the same direction as the Earth and taking from three to six years to complete a full circuit of the Sun.
Asteroids have been historically observed from Earth; the Galileo spacecraft provided the first close observation of an asteroid. Several dedicated missions to asteroids were subsequently launched by NASA and JAXA, with plans for other missions in progress. NASA's NEAR Shoemaker studied Eros, and Dawn observed Vesta and Ceres. JAXA's missions Hayabusa and Hayabusa2 studied and returned samples of Itokawa and Ryugu, respectively. OSIRIS-REx studied Bennu, collecting a sample in 2020 to be delivered back to Earth in 2023. NASA's Lucy, launched in 2021, will study eight different asteroids, one from the main belt and seven Jupiter trojans. Psyche, scheduled for launch in 2023, will study a metallic asteroid of the same name.
Near-Earth asteroids can threaten all life on the planet; an asteroid impact event resulted in the Cretaceous–Paleogene extinction. Different asteroid deflection strategies have been proposed; the Double Asteroid Redirection Test spacecraft, or DART, was launched in 2021 and intentionally impacted Dimorphos in September 2022, successfully altering its orbit by crashing into it.
Details
An Asteroid, also called minor planet or planetoid, is any of a host of small bodies, about 1,000 km (600 miles) or less in diameter, that orbit the Sun primarily between the orbits of Mars and Jupiter in a nearly flat ring called the asteroid belt. It is because of their small size and large numbers relative to the major planets that asteroids are also called minor planets. The two designations have been used interchangeably, though the term asteroid is more widely recognized by the general public. Among scientists, those who study individual objects with dynamically interesting orbits or groups of objects with similar orbital characteristics generally use the term minor planet, whereas those who study the physical properties of such objects usually refer to them as asteroids. The distinction between asteroids and meteoroids having the same origin is culturally imposed and is basically one of size. Asteroids that are approximately house-sized (a few tens of metres across) and smaller are often called meteoroids, though the choice may depend somewhat on context—for example, whether they are considered objects orbiting in space (asteroids) or objects having the potential to collide with a planet, natural satellite, or other comparatively large body or with a spacecraft (meteoroids).
Major milestones in asteroid research
Early discoveries
The first asteroid was discovered on January 1, 1801, by the astronomer Giuseppe Piazzi at Palermo, Italy. At first Piazzi thought he had discovered a comet; however, after the orbital elements of the object had been computed, it became clear that the object moved in a planetlike orbit between the orbits of Mars and Jupiter. Because of illness, Piazzi was able to observe the object only until February 11. Although the discovery was reported in the press, Piazzi only shared details of his observations with a few astronomers and did not publish a complete set of his observations until months later. With the mathematics then available, the short arc of observations did not allow computation of an orbit of sufficient accuracy to predict where the object would reappear when it moved back into the night sky, so some astronomers did not believe in the discovery at all.
There matters might have stood had it not been for the fact that that object was located at the heliocentric distance predicted by Bode’s law of planetary distances, proposed in 1766 by the German astronomer Johann D. Titius and popularized by his compatriot Johann E. Bode, who used the scheme to advance the notion of a “missing” planet between Mars and Jupiter. The discovery of the planet Uranus in 1781 by the British astronomer William Herschel at a distance that closely fit the distance predicted by Bode’s law was taken as strong evidence of its correctness. Some astronomers were so convinced that they agreed during an astronomical conference in 1800 to undertake a systematic search. Ironically, Piazzi was not a party to that attempt to locate the missing planet. Nonetheless, Bode and others, on the basis of the preliminary orbit, believed that Piazzi had found and then lost it. That led German mathematician Carl Friedrich Gauss to develop in 1801 a method for computing the orbit of minor planets from only a few observations, a technique that has not been significantly improved since. The orbital elements computed by Gauss showed that, indeed, the object moved in a planetlike orbit between the orbits of Mars and Jupiter. Using Gauss’s predictions, German Hungarian astronomer Franz von Zach (ironically, the one who had proposed making a systematic search for the “missing” planet) rediscovered Piazzi’s object on December 7, 1801. (It was also rediscovered independently by German astronomer Wilhelm Olbers on January 2, 1802.) Piazzi named that object Ceres after the ancient Roman grain goddess and patron goddess of Sicily, thereby initiating a tradition that continues to the present day: asteroids are named by their discoverers (in contrast to comets, which are named for their discoverers).
The discovery of three more faint objects in similar orbits over the next six years—Pallas, Juno, and Vesta—complicated that elegant solution to the missing-planet problem and gave rise to the surprisingly long-lived though no longer accepted idea that the asteroids were remnants of a planet that had exploded.
Following that flurry of activity, the search for the planet appears to have been abandoned until 1830, when Karl L. Hencke renewed it. In 1845 he discovered a fifth asteroid, which he named Astraea.
The name asteroid (Greek for “starlike”) had been suggested to Herschel by classicist Charles Burney, Jr., via his father, music historian Charles Burney, Sr., who was a close friend of Herschel’s. Herschel proposed the term in 1802 at a meeting of the Royal Society. However, it was not accepted until the mid-19th century, when it became clear that Ceres and the other asteroids were not planets.
There were 88 known asteroids by 1866, when the next major discovery was made: Daniel Kirkwood, an American astronomer, noted that there were gaps (now known as Kirkwood gaps) in the distribution of asteroid distances from the Sun (see below Distribution and Kirkwood gaps). The introduction of photography to the search for new asteroids in 1891, by which time 322 asteroids had been identified, accelerated the discovery rate. The asteroid designated (323) Brucia, detected in 1891, was the first to be discovered by means of photography. By the end of the 19th century, 464 had been found, and that number grew to 108,066 by the end of the 20th century and was almost 1,000,000 in the third decade of the 21st century. The explosive growth was a spin-off of a survey designed to find 90 percent of asteroids with diameters greater than one kilometre that can cross Earth’s orbit and thus have the potential to collide with the planet (see below Near-Earth asteroids).
Later advances
In 1918 the Japanese astronomer Hirayama Kiyotsugu recognized clustering in three of the orbital elements (semimajor axis, eccentricity, and inclination) of various asteroids. He speculated that objects sharing those elements had been formed by explosions of larger parent asteroids, and he called such groups of asteroids “families.”
In the mid-20th century, astronomers began to consider the idea that, during the formation of the solar system, Jupiter was responsible for interrupting the accretion of a planet from a swarm of planetesimals located about 2.8 astronomical units (AU) from the Sun; for elaboration of this idea, see below Origin and evolution of the asteroids. (One astronomical unit is the average distance from Earth to the Sun—about 150 million km [93 million miles].) About the same time, calculations of the lifetimes of asteroids whose orbits passed close to those of the major planets showed that most such asteroids were destined either to collide with a planet or to be ejected from the solar system on timescales of a few hundred thousand to a few million years. Since the age of the solar system is approximately 4.6 billion years, this meant that the asteroids seen today in such orbits must have entered them recently and implied that there was a source for those asteroids. At first that source was thought to be comets that had been captured by the planets and that had lost their volatile material through repeated passages inside the orbit of Mars. It is now known that most such objects come from regions in the main asteroid belt near Kirkwood gaps and other orbital resonances.
During much of the 19th century, most discoveries concerning asteroids were based on studies of their orbits. The vast majority of knowledge about the physical characteristics of asteroids—for example, their size, shape, rotation period, composition, mass, and density—was learned beginning in the 20th century, in particular since the 1970s. As a result of such studies, those objects went from being merely “minor” planets to becoming small worlds in their own right. The discussion below follows that progression in knowledge, focusing first on asteroids as orbiting bodies and then on their physical nature.
Geography of the asteroid belt
Geography in its most-literal sense is a description of the features on the surface of Earth or another planet. Three coordinates—latitude, longitude, and altitude—suffice for locating all such features. Similarly, the location of any object in the solar system can be specified by three parameters—heliocentric ecliptic longitude, heliocentric ecliptic latitude, and heliocentric distance. Such positions, however, are valid for only an instant of time, since all objects in the solar system are continuously in motion. Thus, a better descriptor of the “location” of a solar system object is the path, called the orbit, that it follows around the Sun (or, in the case of a planetary satellite [moon], the path around its parent planet).
All asteroids orbit the Sun in elliptical orbits and move in the same direction as the major planets. Some elliptical orbits are very nearly circles, whereas others are highly elongated (eccentric). An orbit is completely described by six geometric parameters called its elements. Orbital elements, and hence the shape and orientation of the orbit, also vary with time because each object is gravitationally acting on, and being acted upon by, all other bodies in the solar system. In most cases such gravitational effects can be accounted for so that accurate predictions of past and future locations can be made and a mean orbit can be defined. Those mean orbits can then be used to describe the geography of the asteroid belt.
Names and orbits of asteroids
Because of their widespread occurrence, asteroids are assigned numbers as well as names. The numbers are assigned consecutively after accurate orbital elements have been determined. Ceres is officially known as (1) Ceres, Pallas as (2) Pallas, and so forth. Of the 990,933 asteroids discovered through 2020, 55 percent were numbered. Asteroid discoverers have the right to choose names for their discoveries as soon as they have been numbered. The names selected are submitted to the International Astronomical Union (IAU) for approval. (In 2006 the IAU decided that Ceres, the largest known asteroid, also qualified as a member of a new category of solar system objects called dwarf planets.)
Prior to the mid-20th century, asteroids were sometimes assigned numbers before accurate orbital elements had been determined, so some numbered asteroids could not later be located. Such objects were referred to as “lost” asteroids. The final lost numbered asteroid, (719) Albert, was recovered in 2000 after a lapse of 89 years. Many newly discovered asteroids still become “lost” because of an insufficiently long span of observations, but no new asteroids are assigned numbers until their orbits are reliably known.
The Minor Planet Center at the Harvard-Smithsonian Center for Astrophysics in Cambridge, Massachusetts, maintains computer files for all measurements of asteroid positions. As of 2020 there were more than 268 million such positions in its database.
Distribution and Kirkwood gaps
The great majority of the known asteroids move in orbits between those of Mars and Jupiter. Most of those orbits, in turn, have semimajor axes, or mean distances from the Sun, between 2.06 and 3.28 AU, a region called the main belt. The mean distances are not uniformly distributed but exhibit population depletions, or “gaps.” Those so-called Kirkwood gaps are due to mean-motion resonances with Jupiter’s orbital period. An asteroid with a mean distance from the Sun of 2.50 AU, for example, makes three circuits around the Sun in the time it takes Jupiter, which has a mean distance of 5.20 AU, to make one circuit. The asteroid is thus said to be in a three-to-one (written 3:1) resonance orbit with Jupiter. Consequently, once every three orbits, Jupiter and an asteroid in such an orbit would be in the same relative positions, and the asteroid would experience a gravitational force in a fixed direction. Repeated applications of that force would eventually change the mean distance of that asteroid—and others in similar orbits—thus creating a gap at 2.50 AU. Major gaps occur at distances from the Sun that correspond to resonances with Jupiter of 4:1, 3:1, 5:2, 7:3, and 2:1, with the respective mean distances being 2.06, 2.50, 2.82, 2.96, and 3.28. The major gap at the 4:1 resonance defines the nearest extent of the main belt; the gap at the 2:1 resonance, the farthest extent.
Some mean-motion resonances, rather than dispersing asteroids, are observed to collect them. Outside the limits of the main belt, asteroids cluster near resonances of 5:1 (at 1.78 AU, called the Hungaria group), 7:4 (at 3.58 AU, the Cybele group), 3:2 (at 3.97 AU, the Hilda group), 4:3 (at 4.29 AU, the Thule group), and 1:1 (at 5.20 AU, the Trojan groups). The presence of other resonances, called secular resonances, complicates the situation, particularly at the sunward edge of the belt. Secular resonances, in which two orbits interact through the motions of their ascending nodes, perihelia, or both, operate over timescales of millions of years to change the eccentricity and inclination of asteroids. Combinations of mean-motion and secular resonances can either result in long-term stabilization of asteroid orbits at certain mean-motion resonances, as is evidenced by the Hungaria, Cybele, Hilda, and Trojan asteroid groups, or cause the orbits to evolve away from the resonances, as is evidenced by the Kirkwood gaps.
Near-Earth asteroids
Asteroids that can come close to Earth are called near-Earth asteroids (NEAs), although not all NEAs actually cross Earth’s orbit. NEAs are divided into several orbital classes. Asteroids belonging to the class most distant from Earth—those asteroids that can cross the orbit of Mars but that have perihelion distances greater than 1.3 AU—are dubbed Mars crossers. That class is further subdivided into two: shallow Mars crossers (perihelion distances no less than 1.58 AU but less than 1.67 AU) and deep Mars crossers (perihelion distances greater than 1.3 AU but less than 1.58 AU).
The next-most-distant class of NEAs is the Amors. Members of that group have perihelion distances that are greater than 1.017 AU, which is Earth’s aphelion distance, but no greater than 1.3 AU. Amor asteroids therefore do not at present cross Earth’s orbit. Because of strong gravitational perturbations produced by their close approaches to Earth, however, the orbital elements of all Earth-approaching asteroids except the shallow Mars crossers change appreciably on timescales as short as years or decades. For that reason, about half the known Amors—including (1221) Amor, the namesake of the group—are part-time Earth crossers. Only asteroids that cross the orbits of planets—i.e., Earth-approaching asteroids and idiosyncratic objects such as (944) Hidalgo and Chiron (see below Asteroids in unusual orbits)—suffer significant changes in their orbital elements on timescales shorter than many millions of years.
There are two classes of NEAs that deeply cross Earth’s orbit on an almost continuous basis. The first of those to be discovered were the Apollo asteroids, named for (1862) Apollo, which was discovered in 1932 but was lost shortly thereafter and not rediscovered until 1978. The mean distances of Apollo asteroids from the Sun are greater than or equal to 1 AU, and their perihelion distances are less than or equal to Earth’s aphelion distance of 1.017 AU; thus, they cross Earth’s orbit when near the closest points to the Sun in their own orbits. The other class of Earth-crossing asteroids is named Atens for (2062) Aten, which was discovered in 1976. The Aten asteroids have mean distances from the Sun that are less than 1 AU and aphelion distances that are greater than or equal to 0.983 AU, the perihelion distance of Earth; they cross Earth’s orbit when near the farthest points from the Sun of their orbits.
The class of NEAs that was the last to be recognized is composed of asteroids with orbits entirely inside that of Earth. Known as Atira asteroids after (163693) Atira, they have mean distances from the Sun that are less than 1 AU and aphelion distances less than 0.983 AU; they do not cross Earth’s orbit.
By 2020 the known Atira, Aten, Apollo, and Amor asteroids of all sizes numbered 42, 1,771, 11,851, and 9,837, respectively, although those numbers are steadily increasing as the asteroid survey programs progress. Most of those have been discovered since 1970, when dedicated searches for those types of asteroids were begun. Astronomers have estimated that there are roughly 15 Atiras, 45 Atens, 570 Apollos, and 270 Amors that have diameters larger than about 1 km (0.6 mile).
Because they can approach quite close to Earth, some of the best information available on asteroids has come from Earth-based radar studies of NEAs. In 1968 the Apollo asteroid (1566) Icarus became the first NEA to be observed with radar. By 2020 almost 1,000 NEAs had been so observed. Because of continuing improvements to the radar systems themselves and to the computers used to process the data, the information provided by that technique increased dramatically beginning in the final decade of the 20th century. For example, the first images of an asteroid, (4769) Castalia, were made by using radar data obtained in 1989, more than two years before the first spacecraft flyby of an asteroid—(951) Gaspra by the Galileo spacecraft in 1991 (see below Spacecraft exploration). The observations of Castalia provided the first evidence in the solar system for a double-lobed object, interpreted to be two roughly equal-sized bodies in contact. Radar observations of (4179) Toutatis in 1992 revealed it to be several kilometres long with a peanut-shell shape; similar to Castalia, Toutatis appears predominantly to be two components in contact, one about twice as large as the other. The highest-resolution images show craters having diameters between 100 and 600 metres (roughly 300 and 2,000 feet). Radar images of (1620) Geographos obtained in 1994 were numerous enough and of sufficient quality for an animation to be made showing it rotating.
The orbital characteristics of NEAs mean that some of those objects make close approaches to Earth and occasionally collide with it. In January 1991, for example, an Apollo asteroid (or, as an alternative description, a large meteoroid) with an estimated diameter of 10 metres (33 feet) passed by Earth within less than half the distance to the Moon. Such passages are not especially unusual. On October 6, 2008, the asteroid 2008 TC3, which had a size of about 5 metres (16 feet), was discovered. It crashed in the Nubian Desert of Sudan the next day. However, because of the small sizes of NEAs and the short time they spend close enough to Earth to be seen, it is unusual for such close passages to be observed. An example of an NEA for which the lead time for observation is large is (99942) Apophis. That Aten asteroid, which has a diameter of about 375 metres (1,230 feet), is predicted to pass within 32,000 km (20,000 miles) of Earth—i.e., closer than communications satellites in geostationary orbits—on April 13, 2029; during that passage its probability of hitting Earth is thought to be near zero. The collision of a sufficiently large NEA with Earth is generally recognized to pose a great potential danger to human beings and possibly to all life on the planet. For a detailed discussion of this topic, see Earth impact hazard.
Main-belt asteroid families
Within the main belt are groups of asteroids that cluster with respect to certain mean orbital elements (semimajor axis, eccentricity, and inclination). Such groups are called families and are named for the lowest numbered asteroid in the family. Asteroid families are formed when an asteroid is disrupted in a catastrophic collision, the members of the family thus being pieces of the original asteroid. Theoretical studies indicate that catastrophic collisions between asteroids are common enough to account for the number of families observed. About 40 percent of the larger asteroids belong to such families, but as high a proportion as 90 percent of small asteroids (i.e., those about 1 km in diameter) may be family members, because each catastrophic collision produces many more small fragments than large ones and smaller asteroids are more likely to be completely disrupted.
The three largest families in the main asteroid belt are named Eos, Koronis, and Themis. Each family has been determined to be compositionally homogeneous; that is, all the members of a family appear to have the same basic chemical makeup. If the asteroids belonging to each family are considered to be fragments of a single parent body, then their parent bodies must have had diameters of 200, 90, and 300 km (124, 56, and 186 miles), respectively. The smaller families present in the main belt have not been as well studied, because their numbered members are fewer and smaller (and hence fainter when viewed telescopically). It is theorized that some of the Earth-crossing asteroids and the great majority of meteorites reaching Earth’s surface are fragments produced in collisions similar to those that produced the asteroid families. For example, the asteroid Vesta, whose surface appears to be basaltic rock, is the parent body of the meteorites known as basaltic achondrite HEDs, a grouping of the related howardite, eucrite, and diogenite meteorite types.
Hungarias and outer-belt asteroids
Only one known concentration of asteroids, the Hungaria group, occupies the region between Mars and the inner edge of the main belt. The orbits of all the Hungarias lie outside the orbit of Mars, whose aphelion distance is 1.67 AU. Hungaria asteroids have nearly circular (low-eccentricity) orbits but large orbital inclinations to Earth’s orbit and the general plane of the solar system.
Four known asteroid groups fall beyond the main belt but within or near the orbit of Jupiter, with mean distances from the Sun between about 3.28 and 5.3 AU, as mentioned above in the section Distribution and Kirkwood gaps. Collectively called outer-belt asteroids, they have orbital periods that range from more than one-half that of Jupiter to approximately Jupiter’s period. Three of the outer-belt groups—the Cybeles, the Hildas, and Thule—are named after the lowest-numbered asteroid in each group. Members of the fourth group are called Trojan asteroids. By 2020 there were about 2,034 Cybeles, 4,493 Hildas, 3 Thules, and 8,721 Trojans. Those groups should not be confused with asteroid families, all of which share a common parent asteroid. However, some of those groups—e.g., the Hildas and Trojans—contain families.
Trojan asteroids
In 1772 the French mathematician and astronomer Joseph-Louis Lagrange predicted the existence and location of two groups of small bodies located near a pair of gravitationally stable points along Jupiter’s orbit. Those are positions (now called Lagrangian points and designated L4 and L5) where a small body can be held, by gravitational forces, at one vertex of an equilateral triangle whose other vertices are occupied by the massive bodies of Jupiter and the Sun. Those positions, which lead (L4) and trail (L5) Jupiter by 60° in the plane of its orbit, are two of the five theoretical Lagrangian points in the solution to the circular restricted three-body problem of celestial mechanics (see celestial mechanics: The restricted three-body problem). The other three points are located along a line passing through the Sun and Jupiter. The presence of other planets, however—principally Saturn—perturbs the Sun-Jupiter-Trojan asteroid system enough to destabilize those points, and no asteroids have been found actually at them. In fact, because of that destabilization, most of Jupiter’s Trojan asteroids move in orbits inclined as much as 40° from Jupiter’s orbit and displaced as much as 70° from the leading and trailing positions of the true Lagrangian points.
In 1906 the first of the predicted objects, (588) Achilles, was discovered near the Lagrangian point preceding Jupiter in its orbit. Within a year two more were found: (617) Patroclus, located near the trailing Lagrangian point, and (624) Hektor, near the leading Lagrangian point. It was later decided to continue naming such asteroids after participants in the Trojan War as recounted in Homer’s epic work the Iliad and, furthermore, to name those near the leading point after Greek warriors and those near the trailing point after Trojan warriors. With the exception of the two “misplaced” names already bestowed (Hektor, the lone Trojan in the Greek camp, and Patroclus, the lone Greek in the Trojan camp), that tradition has been maintained.
As of 2020, of the 8,721 Jupiter Trojan asteroids discovered, about two-thirds are located near the leading Lagrangian point, L4, and the remainder are near the trailing one, L5. Astronomers estimate that 1,800–2,200 of the total existing population of Jupiter’s Trojans have diameters greater than 10 km (6 miles).
Since the discovery of Jupiter’s orbital companions, the term Trojan has been applied to any small object occupying the equilateral Lagrangian points of other pairs of relatively massive bodies. Astronomers have searched for Trojan objects of Earth, Mars, Saturn, Uranus, and Neptune as well as of the Earth-Moon system. It was long considered doubtful whether truly stable orbits could exist near those Lagrangian points because of gravitational perturbations by the major planets. However, in 1990 an asteroid later named (5261) Eureka was discovered librating (oscillating) about the trailing Lagrangian point of Mars, and since then three others have been found, two at the trailing point and one at the leading point. Twenty-nine Trojans of Neptune, all but five associated with the leading Lagrangian point, have been discovered since 2001. One Neptune Trojan, 2010 EN65, is a jumping Trojan, which was discovered at L3, the Lagrangian point on the opposite side of the Sun from Neptune. This asteroid is passing through L3 on its way from L4 to L5. The first Earth Trojan asteroid, 2010 TK7, which librates around L4, was discovered in 2010. The first Uranus Trojan, 2011 QF99, which librates around L4, was discovered in 2011. Although Trojans of Saturn have yet to be found, objects librating about Lagrangian points of the systems formed by Saturn and its moon Tethys and Saturn and its moon Dione are known.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1624 2023-01-04 00:05:11
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1527) Computer monitor
A computer monitor is an output device that displays information in pictorial or textual form. A discrete monitor comprises a visual display, support electronics, power supply, housing, electrical connectors, and external user controls.
The display in modern monitors is typically an LCD with LED backlight, having by the 2010s replaced CCFL backlit LCDs. Before the mid-2000s, most monitors used a CRT. Monitors are connected to the computer via DisplayPort, HDMI, USB-C, DVI, VGA, or other proprietary connectors and signals.
Originally, computer monitors were used for data processing while television sets were used for video. From the 1980s onward, computers (and their monitors) have been used for both data processing and video, while televisions have implemented some computer functionality. In the 2000s, the typical display aspect ratio of both televisions and computer monitors has changed from 4:3 to 16:9.
Modern computer monitors are mostly interchangeable with television sets and vice versa. As most computer monitors do not include integrated speakers, TV tuners, nor remote controls, external components such as a DTA box may be needed to use a computer monitor as a TV set.
LCD : Liquid-crystal display
LED : Light-emitting diode
LED backlight : LED-backlit LCD
CCFL :Cold-cathode fluorescent lamps
CRT: Cathode-ray tube
HDMI : High-Definition Multimedia Interface
USB-C : a 24-pin USB connector system with a rotationally symmetrical connector.
USB : Universal Serial Bus
DVI : Digital Visual Interface
VGA : Video Graphics Array
DTA : Digital television adapter
History
Early electronic computer front panels were fitted with an array of light bulbs where the state of each particular bulb would indicate the on/off state of a particular register bit inside the computer. This allowed the engineers operating the computer to monitor the internal state of the machine, so this panel of lights came to be known as the 'monitor'. As early monitors were only capable of displaying a very limited amount of information and were very transient, they were rarely considered for program output. Instead, a line printer was the primary output device, while the monitor was limited to keeping track of the program's operation.
Computer monitors were formerly known as visual display units (VDU), particularly in British English. This term mostly fell out of use by the 1990s.
Technologies
Multiple technologies have been used for computer monitors. Until the 21st century most used cathode-ray tubes but they have largely been superseded by LCD monitors.
Cathode-ray tube
The first computer monitors used cathode-ray tubes (CRTs). Prior to the advent of home computers in the late 1970s, it was common for a video display terminal (VDT) using a CRT to be physically integrated with a keyboard and other components of the workstation in a single large chassis, typically limiting them to emulation of a paper teletypewriter, thus the early epithet of 'glass TTY'. The display was monochromatic and far less sharp and detailed than on a modern monitor, necessitating the use of relatively large text and severely limiting the amount of information that could be displayed at one time. High-resolution CRT displays were developed for specialized military, industrial and scientific applications but they were far too costly for general use; wider commercial use became possible after the release of a slow, but affordable Tektronix 4010 terminal in 1972.
Some of the earliest home computers (such as the TRS-80 and Commodore PET) were limited to monochrome CRT displays, but color display capability was already a possible feature for a few MOS 6500 series-based machines (such as introduced in 1977 Apple II computer or Atari 2600 console), and the color output was a speciality of the more graphically sophisticated Atari 800 computer, introduced in 1979. Either computer could be connected to the antenna terminals of an ordinary color TV set or used with a purpose-made CRT color monitor for optimum resolution and color quality. Lagging several years behind, in 1981 IBM introduced the Color Graphics Adapter, which could display four colors with a resolution of 320 × 200 pixels, or it could produce 640 × 200 pixels with two colors. In 1984 IBM introduced the Enhanced Graphics Adapter which was capable of producing 16 colors and had a resolution of 640 × 350.
By the end of the 1980s color progressive scan CRT monitors were widely available and increasingly affordable, while the sharpest prosumer monitors could clearly display high-definition video, against the backdrop of efforts at HDTV standardization from the 1970s to the 1980s failing continuously, leaving consumer SDTVs to stagnate increasingly far behind the capabilities of computer CRT monitors well into the 2000s. During the following decade, maximum display resolutions gradually increased and prices continued to fall as CRT technology remained dominant in the PC monitor market into the new millennium, partly because it remained cheaper to produce. CRTs still offer color, grayscale, motion, and latency advantages over today's LCDs, but improvements to the latter have made them much less obvious. The dynamic range of early LCD panels was very poor, and although text and other motionless graphics were sharper than on a CRT, an LCD characteristic known as pixel lag caused moving graphics to appear noticeably smeared and blurry.
Liquid-crystal display
There are multiple technologies that have been used to implement liquid-crystal displays (LCD). Throughout the 1990s, the primary use of LCD technology as computer monitors was in laptops where the lower power consumption, lighter weight, and smaller physical size of LCDs justified the higher price versus a CRT. Commonly, the same laptop would be offered with an assortment of display options at increasing price points: (active or passive) monochrome, passive color, or active matrix color (TFT). As volume and manufacturing capability have improved, the monochrome and passive color technologies were dropped from most product lines.
TFT-LCD is a variant of LCD which is now the dominant technology used for computer monitors.
The first standalone LCDs appeared in the mid-1990s selling for high prices. As prices declined they became more popular, and by 1997 were competing with CRT monitors. Among the first desktop LCD computer monitors was the Eizo FlexScan L66 in the mid-1990s, the SGI 1600SW, Apple Studio Display and the ViewSonic VP140 in 1998. In 2003, LCDs outsold CRTs for the first time, becoming the primary technology used for computer monitors. The physical advantages of LCD over CRT monitors are that LCDs are lighter, smaller, and consume less power. In terms of performance, LCDs produce less or no flicker, reducing eyestrain, sharper image at native resolution, and better checkerboard contrast. On the other hand, CRT monitors have superior blacks, viewing angles, response time, are able to use arbitrary lower resolutions without aliasing, and flicker can be reduced with higher refresh rates, though this flicker can also be used to reduce motion blur compared to less flickery displays such as most LCDs. Many specialized fields such as vision science remain dependent on CRTs, the best LCD monitors having achieved moderate temporal accuracy, and so can be used only if their poor spatial accuracy is unimportant.
High dynamic range (HDR) has been implemented into high-end LCD monitors to improve grayscale accuracy. Since around the late 2000s, widescreen LCD monitors have become popular, in part due to television series, motion pictures and video games transitioning to widescreen, which makes squarer monitors unsuited to display them correctly.
Organic light-emitting diode
Organic light-emitting diode (OLED) monitors provide most of the benefits of both LCD and CRT monitors with few of their drawbacks, though much like plasma panels or very early CRTs they suffer from burn-in, and remain very expensive.
Measurements of performance
The performance of a monitor is measured by the following parameters:
* Display geometry:
** Viewable image size - is usually measured diagonally, but the actual widths and heights are more informative since they are not affected by the aspect ratio in the same way. For CRTs, the viewable size is typically 1 in (25 mm) smaller than the tube itself.
** Aspect ratio - is the ratio of the horizontal length to the vertical length. Monitors usually have the aspect ratio 4:3, 5:4, 16:10 or 16:9.
** Radius of curvature (for curved monitors) - is the radius that a circle would have if it had the same curvature as the display. This value is typically given in millimeters, but expressed with the letter "R" instead of a unit (for example, a display with "3800R curvature" has a 3800 mm radius of curvature.
* Display resolution is the number of distinct pixels in each dimension that can be displayed natively. For a given display size, maximum resolution is limited by dot pitch or DPI.
** Dot pitch represents the distance between the primary elements of the display, typically averaged across it in nonuniform displays. A related unit is pixel pitch, In LCDs, pixel pitch is the distance between the center of two adjacent pixels. In CRTs, pixel pitch is defined as the distance between subpixels of the same color. Dot pitch is the reciprocal of pixel density.
** Pixel density is a measure of how densely packed the pixels on a display are. In LCDs, pixel density is the number of pixels in one linear unit along the display, typically measured in pixels per inch (px/in or ppi).
* Color characteristics:
** Luminance - measured in candelas per square meter (cd/m^2, also called a nit).
** Contrast ratio is the ratio of the luminosity of the brightest color (white) to that of the darkest color (black) that the monitor is capable of producing simultaneously. For example, a ratio of 20,000∶1 means that the brightest shade (white) is 20,000 times brighter than its darkest shade (black). Dynamic contrast ratio is measured with the LCD backlight turned off. ANSI contrast is with both black and white simultaneously adjacent onscreen.
** Color depth - measured in bits per primary color or bits for all colors. Those with 10 bpc (bits per channel) or more can display more shades of color (approximately 1 billion shades) than traditional 8 bpc monitors (approximately 16.8 million shades or colors), and can do so more precisely without having to resort to dithering.
** Gamut - measured as coordinates in the CIE 1931 color space. The names sRGB or Adobe RGB are shorthand notations.
** Color accuracy - measured in ΔE (delta-E); the lower the ΔE, the more accurate the color representation. A ΔE of below 1 is imperceptible to the human eye. A ΔE of 2–4 is considered good and requires a sensitive eye to spot the difference.
** Viewing angle is the maximum angle at which images on the monitor can be viewed, without subjectively excessive degradation to the image. It is measured in degrees horizontally and vertically.
* Input speed characteristics:
** Refresh rate is (in CRTs) the number of times in a second that the display is illuminated (the number of times a second a raster scan is completed). In LCDs it is the number of times the image can be changed per second, expressed in hertz (Hz). Determines the maximum number of frames per second (FPS) a monitor is capable of showing. Maximum refresh rate is limited by response time.
** Response time is the time a pixel in a monitor takes to change between two shades. The particular shades depend on the test procedure, which differs between manufacturers. In general, lower numbers mean faster transitions and therefore fewer visible image artifacts such as ghosting. Grey to grey (GtG), measured in milliseconds (ms).
** Input latency is the time it takes for a monitor to display an image after receiving it, typically measured in milliseconds (ms).
* Power consumption is measured in watts.
Size
On two-dimensional display devices such as computer monitors the display size or view able image size is the actual amount of screen space that is available to display a picture, video or working space, without obstruction from the bezel or other aspects of the unit's design. The main measurements for display devices are: width, height, total area and the diagonal.
The size of a display is usually given by manufacturers diagonally, i.e. as the distance between two opposite screen corners. This method of measurement is inherited from the method used for the first generation of CRT television, when picture tubes with circular faces were in common use. Being circular, it was the external diameter of the glass envelope that described their size. Since these circular tubes were used to display rectangular images, the diagonal measurement of the rectangular image was smaller than the diameter of the tube's face (due to the thickness of the glass). This method continued even when cathode-ray tubes were manufactured as rounded rectangles; it had the advantage of being a single number specifying the size, and was not confusing when the aspect ratio was universally 4:3.
With the introduction of flat panel technology, the diagonal measurement became the actual diagonal of the visible display. This meant that an eighteen-inch LCD had a larger viewable area than an eighteen-inch cathode-ray tube.
Estimation of monitor size by the distance between opposite corners does not take into account the display aspect ratio, so that for example a 16:9 21-inch (53 cm) widescreen display has less area, than a 21-inch (53 cm) 4:3 screen. The 4:3 screen has dimensions of 16.8 in × 12.6 in (43 cm × 32 cm) and area 211 sq in (1,360 sq cm), while the widescreen is 18.3 in × 10.3 in (46 cm × 26 cm), 188 sq in (1,210 sq cm).
Aspect ratio
Until about 2003, most computer monitors had a 4:3 aspect ratio and some had 5:4. Between 2003 and 2006, monitors with 16:9 and mostly 16:10 (8:5) aspect ratios became commonly available, first in laptops and later also in standalone monitors. Reasons for this transition included productive uses for such monitors, i.e. besides Field of view in video games and movie viewing, are the word processor display of two standard letter pages side by side, as well as CAD displays of large-size drawings and application menus at the same time.[ In 2008 16:10 became the most common sold aspect ratio for LCD monitors and the same year 16:10 was the mainstream standard for laptops and notebook computers.
In 2010, the computer industry started to move over from 16:10 to 16:9 because 16:9 was chosen to be the standard high-definition television display size, and because they were cheaper to manufacture.
In 2011, non-widescreen displays with 4:3 aspect ratios were only being manufactured in small quantities. According to Samsung, this was because the "Demand for the old 'Square monitors' has decreased rapidly over the last couple of years," and "I predict that by the end of 2011, production on all 4:3 or similar panels will be halted due to a lack of demand."
Resolution
The resolution for computer monitors has increased over time. From 280 × 192 during the late 1970s, to 1024 × 768 during the late 1990s. Since 2009, the most commonly sold resolution for computer monitors is 1920 × 1080, shared with the 1080p of HDTV.[19] Before 2013 mass market LCD monitors were limited to 2560 × 1600 at 30 in (76 cm), excluding niche professional monitors. By 2015 most major display manufacturers had released 3840 × 2160 (4K UHD) displays, and the first 7680 × 4320 (8K) monitors had begun shipping.
Gamut
Every RGB monitor has its own color gamut, bounded in chromaticity by a color triangle. Some of these triangles are smaller than the sRGB triangle, some are larger. Colors are typically encoded by 8 bits per primary color. The RGB value [255, 0, 0] represents red, but slightly different colors in different color spaces such as Adobe RGB and sRGB. Displaying sRGB-encoded data on wide-gamut devices can give an unrealistic result. The gamut is a property of the monitor; the image color space can be forwarded as Exif metadata in the picture. As long as the monitor gamut is wider than the color space gamut, correct display is possible, if the monitor is calibrated. A picture which uses colors that are outside the sRGB color space will display on an sRGB color space monitor with limitations. Still today, many monitors that can display the sRGB color space are not factory nor user calibrated to display it correctly. Color management is needed both in electronic publishing (via the Internet for display in browsers) and in desktop publishing targeted to print.
[RGB: The RGB color model is an additive color model in which the red, green and blue primary colors of light are added together in various ways to reproduce a broad array of colors. The name of the model comes from the initials of the three additive primary colors, red, green, and blue.]

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline
#1625 2023-01-05 00:09:42
- Jai Ganesh
- Administrator
- Registered: 2005-06-28
- Posts: 53,809
Re: Miscellany
1528) Schengen Area
Summary
The Schengen Area is an area comprising 27 European countries that have officially abolished all passport and all other types of border control at their mutual borders. Being an element within the wider area of freedom, security and justice policy of the EU, it mostly functions as a single jurisdiction under a common visa policy for international travel purposes. The area is named after the 1985 Schengen Agreement and the 1990 Schengen Convention, both signed in Schengen, Luxembourg.
Of the 27 EU member states, 23 participate in the Schengen Area. Of the four EU members that are not part of the Schengen Area, three—Bulgaria, Cyprus and Romania—are legally obligated to join the area in the future; Ireland maintains an opt-out, and instead operates its own visa policy. The four European Free Trade Association (EFTA) member states, Iceland, Liechtenstein, Norway, and Switzerland, are not members of the EU, but have signed agreements in association with the Schengen Agreement. Also, three European microstates—Monaco, San Marino, and the Vatican City—maintain open borders for passenger traffic with their neighbours, and are therefore considered de facto members of the Schengen Area due to the practical impossibility of travelling to or from them without transiting through at least one Schengen member country.
The Schengen Area has a population of more than 423 million people and an area of 4,368,693 square kilometres (1,686,762 sq mi). About 1.7 million people commute to work across an internal European border each day, and in some regions these people constitute up to a third of the workforce. Each year, there are 1.3 billion crossings of Schengen borders in total. 57 million crossings are due to transport of goods by road, with a value of €2.8 trillion each year. The decrease in the cost of trade due to Schengen varies from 0.42% to 1.59% depending on geography, trade partners, and other factors. Countries outside of the Schengen Area also benefit. States in the Schengen Area have strengthened border controls with non-Schengen countries.
Details
Schengen Agreement, is an international convention initially approved by Belgium, France, West Germany (later Germany), Luxembourg, and the Netherlands in Schengen, Luxembourg, on June 14, 1985. The signatories agreed to begin reducing internal border controls, with the ultimate goal of allowing free movement of persons between countries within the Schengen area. To implement this, a system of shared policies regarding visa and asylum applications was adopted by member countries, and a massive database, known as the Schengen Information System (SIS), was created to share information about persons and goods transiting the Schengen zone.
By the time the agreement went into effect in March 1995, Italy, Spain, Portugal, and Greece had joined the original five members, with Austria, Denmark, Finland, Iceland, Norway, and Sweden following soon after. Although the Schengen Agreement originated outside the framework of the European Union, the Treaty of Amsterdam brought it into the corpus of EU law in 1999. Upgrades were made to the SIS to aid national law enforcement bodies. In 2007 the Schengen area expanded to include the Czech Republic, Estonia, Hungary, Latvia, Lithuania, Malta, Poland, Slovakia, and Slovenia. The area was further enlarged by the addition of Switzerland (2008), Liechtenstein (2011), and Croatia (2023).
Additional Information
Schengen Area Countries:
The 27 Schengen countries are Austria, Belgium, Czech Republic, Croatia, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Iceland, Italy, Latvia, Liechtenstein, Lithuania, Luxembourg, Malta, Netherlands, Norway, Poland, Portugal, Slovakia, Slovenia, Spain, Sweden, and Switzerland.
Currently, the Schengen Area consists of 27 member countries. All of these countries are located in Europe, from which:
* 23 members fully implement the Schengen acquis,
* Four of them – members of the EFTA, implement Schengen acquis through specific agreements related to the Schengen agreement.
* Iceland, Norway, Switzerland and Lichtenstein are associate members of the Schengen Area but are not members of the EU. They are part of the EFTA and implement the Schengen acquis through specific agreements related to the Schengen agreement.
* Monaco, San Marino, and Vatican City have opened their borders with, but are not members of the visa-free zone.
* The Azores, Madeira, and the Canary Islands are special members of the EU and part of the Schengen Zone even though they are located outside the European continent.
* There are four more EU members, that have not joined the Schengen zone: Ireland – which still maintains opt-outs and Romania, Bulgaria, and Cyprus – that are seeking to join soon.
The external borders of the Schengen Zone reach a distance of 50,000 km long, where 80% of it is comprised of water and 20% of the land. The area counts hundreds of airports and maritime ports, many land crossing points, an area of 4,312,099 sq km, and a population of 419,392,429 citizens.

It appears to me that if one wants to make progress in mathematics, one should study the masters and not the pupils. - Niels Henrik Abel.
Nothing is better than reading and gaining more and more knowledge - Stephen William Hawking.
Offline